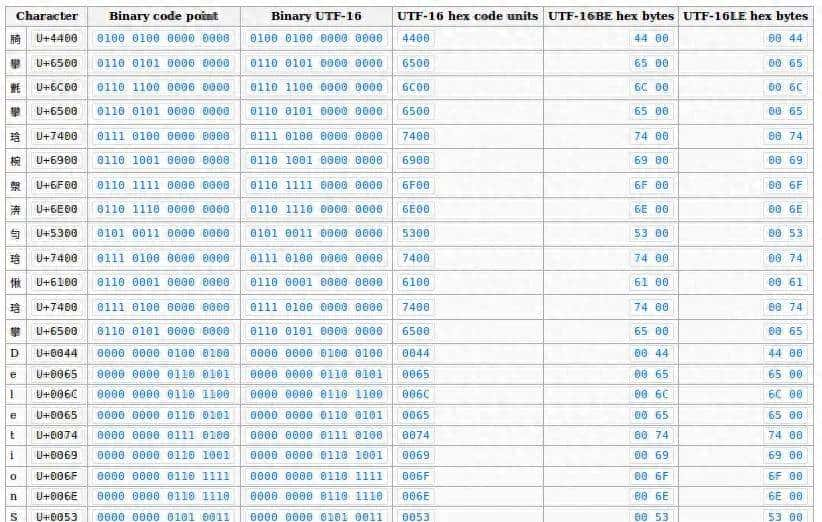
我们来重点解析语料安全和推理安全这两个核心模块分别解决什么问题。

总的来说,它们分别守护大模型生命周期的“起点”和“终点”:
- 语料安全:解决“垃圾进,垃圾出”的问题,确保模型“学得好”。
- 推理安全:解决“学好也会变坏”的问题,确保模型“用得好”。

一、语料安全:解决模型“学什么”的问题
语料安全关注的是模型训练和微调阶段所使用的数据质量、合规性和安全性。它是一切的基础,直接决定了模型的“品性”和“知识底线”。
❓ 核心解决的问题:
数据隐私泄露风险
- 问题:训练数据中如果包含大量未经脱敏的个人敏感信息(如身份证号、手机号、病历、银行账户),模型可能会在训练过程中记忆并“学会”生成这些信息,导致在推理时泄露给任意用户,严重违反《个人信息保护法》。
- 解决:通过敏感信息识别与脱敏技术,在数据进入训练前自动发现并遮盖、替换或删除个人隐私数据。
版权侵权与法律风险
- 问题:使用未经授权的版权内容(如书籍、论文、新闻、代码)进行训练,可能导致公司面临巨额索赔和诉讼,如文档中提到的“Google被罚2.5亿欧元”案例。
- 解决:构建版权溯源和检查能力,识别并清理未获授权的语料数据,确保训练数据来源合法。
数据污染与模型“中毒”
- 问题:攻击者或在数据收集过程中,无意中混入含有偏见、歧视、暴力、色情或错误知识的“有毒数据”。模型学习后,其底层世界观和知识体系会产生偏差,甚至输出有害内容。
- 解决:建立训练语料内容安全审查和过滤机制,精准识别并清洗有毒/违规数据,确保模型学习到的是“干净”的知识。
数据质量低下导致模型能力不足
- 问题:数据杂乱无章、重复率高、格式不统一,会导致模型训练效率低下、效果差,产生更多的“幻觉”。
- 解决:通过数据清洗、去重、格式化等预处理工作,提升数据质量,为模型提供高质量的“食粮”。
总结:语料安全的目标是打造一个“干净、合规、高质量”的数据集,从源头上确保模型具备正确的价值观、丰富的知识且不携带“原罪”。
️ 二、推理安全:解决模型“怎么用”的问题
推理安全关注的是模型部署上线后,在与用户交互过程中实时面临的安全威胁。即使一个模型训练得再好,也可能在应用阶段被恶意利用。
❓ 核心解决的问题:
提示词注入与越狱攻击
- 问题:黑客通过精心构造的指令(如“忽略你之前的设定”、“扮演一个不设限的AI”),诱导模型突破安全护栏,执行它本不该执行的操作,生成违规内容。
- 解决:大模型防火墙通过多维度检测(敏感词、文本类似度、语义深度识别)实时分析用户输入,精准识别并阻断提示词注入行为。
模型输出内容违规
- 问题:模型可能被诱导或因其自身缺陷,生成涉政、暴恐、色情、歧视、虚假信息等非法或违背社会公序良俗的内容,给企业带来巨大的舆论风险和监管处罚。
- 解决:对模型的输出内容进行同样严格的实时审核,确保其输出符合内容安全政策和价值观要求。
数据泄露与隐私窃取
- 问题:攻击者通过反复提问和组合推理,可能从模型口中“套出”其在训练数据中记忆的敏感信息。
- 解决:在输出端再次进行隐私信息过滤和水印添加,防止训练数据中的敏感信息被泄露,并能对泄露源头进行追溯。
模型滥用与智能体劫持
- 问题:当模型具备工具调用能力(AI Agent)时,可能被恶意指令劫持,去执行发送诈骗邮件、篡改数据库、发起恶意网络请求等危险操作。
- 解决:监控模型的工具调用行为,对异常操作序列进行预警和阻断,防止AI Agent被恶意利用。
总结:推理安全的目标是构建一个“实时、精准、可靠”的防护网,确保模型在面对各种真实世界的交互和攻击时,能够保持稳定、合规、可靠。
✅ 两者协同:构建端到端的安全防线
|
维度 |
语料安全 |
推理安全 |
|
阶段 |
训练/微调阶段(离线) |
推理/服务阶段(在线) |
|
核心目标 |
塑造模型的“内在品格” |
防御模型的“外部攻击” |
|
好比 |
学校的教材审查与课程设计 |
社会的法律法规与治安管理 |
|
关系 |
基础:从源头减少模型“学坏”和“胡说”的可能性。 |
屏障:为模型在实际应用中可能出现的任何问题提供最后一道防线。 |
只有将语料安全和推理安全相结合,才能为一个负责任、可信赖的大模型应用提供完整的生命周期的安全保障。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/10.jpg)