1、Google重磅推出“Google Skills”平台,内部AI知识向公众免费开放
2、大模型推理学习新范式!ExGRPO框架:从盲目刷题到机智复盘
3、AI在线强化学习“边做边学”,斯坦福团队让7B小模型性能飙升,甚至超越GPT-4o
4、腾讯发布全新ima 2.0:任务模式上线 新增「AI要点」等功能
5、松延动力正式宣布即将发布全球首款万元以内的高性能人形机器人
6、戴上眼镜,就能控物!俄罗斯团队让机械臂“秒懂”你的眼神
1、Google重磅推出“Google Skills”平台,内部AI知识向公众免费开放
- Google 近日推出了一个名为“Google Skills”的全新学习平台,该平台整合了 DeepMind AI 研究团队、Google Cloud、Gemini AI 模型开发团队以及 Google Education 的精华内容,被誉为是“Google 的内部 AI 知识”首次系统性地向外界开放。
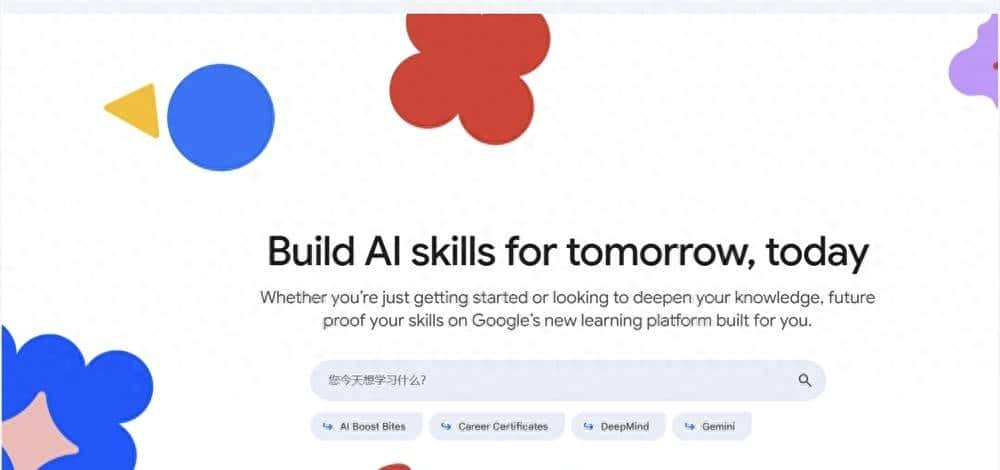
- 对比大学同类课程动辄 5万至6万美元的学费,Google Skills 针对 Google Cloud 用户实现完全免费,几乎达到“零门槛”学习。非 Cloud 用户也可选择每月 $29的订阅制,企业用户则可定制培训方案。
- 该平台提供的核心内容包括:
- DeepMind 的真实 AI 研究训练课程
- 超过700个真实云环境中的实操实验室(Labs)
- 内置 Gemini Code Assist(AI 编程助手)
- 完成课程后颁发官方数字证书和技能徽章(Skill Badge / Certificate)
- 与150多家合作公司直接连接的就业通道
- Google Skills 尤其强调“动手学习”(hands-on learning)的实操训练。除了传统的视频和讲解,平台的核心特色是提供真实的 Google Cloud 环境实验室,学员需完成练习任务(Tasks),亲自编写代码和构建模型。学习过程中,AI 工具 Gemini 会实时提供反馈,协助学员调试代码或补充提示,确保高效的实践效果。
- 地址:https://www.skills.google/
2、大模型推理学习新范式!ExGRPO框架:从盲目刷题到机智复盘
- 来自上海人工智能实验室、澳门大学、南京大学和香港中文大学的研究团队,最近提出了一套经验管理和学习框架ExGRPO——
- 通过科学地识别、存储、筛选和学习有价值的经验,让大模型在优化推理能力的道路上,走得更稳、更快、更远。
- 实验结果显示,与传统的在线策略RLVR(基于可验证奖励的强化学习)方法相比,ExGRPO在不同基准上均带来了必定程度的性能提升。
- 作者设计了ExGRPO框架,包含了两个核心部件:经验管理和混合经验优化。
- 作者将模型经验定义为问题+对应推理过程,分两个层级进行经验的管理和挑选,具体它分为三步:
1、经验收集:ExGRPO会建立一个“经验回放池”,像一个巨大的“错题本”,专门收集模型在训练过程中所有成功的推理案例。这也是传统强化学习和先前相关工作中均拥有的基础机制。
2、经验划分与存储:根据每个问题最新的“在线正确率”,将经验池中的问题动态地划分到不同的“难度分区”里。这就像给错题本按章节和难度进行分类。这样,所有经验都被贴上了“简单”、“中等”、“困难”的标签,管理起来一目了然。
同时,为了防止模型在简单问题上“刷分”而产生过拟合,ExGRPO还拥有一个“退休机制”(Retired Set),将模型已经完全掌握(例如连续多次全部成功解答)的问题移出学习队列,让模型始终聚焦于更具挑战性的任务。
3、经验筛选:按照之前分析实验得到的启示和洞见,ExGRPO从两个层次挑选经验:
- 问题筛选:利用高斯分布概率模型,有偏地优先从中等难度的分组中抽取问题。这样能确保模型总是在学习效率最高的甜蜜点上。
- 轨迹筛选:对于选出的问题,如果它历史上有多个成功解法,只挑选出当前模型看来熵最低的那一个,也就是最笃定清晰的那个解法。
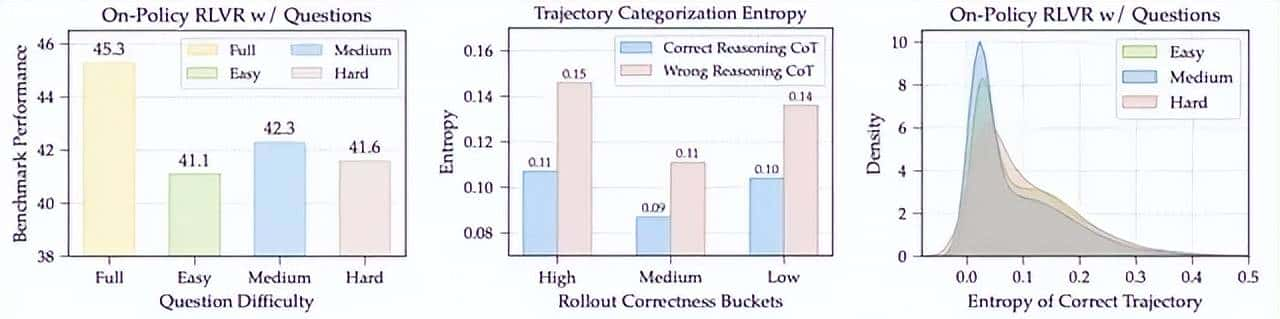
- 通过这套精细化管理,确保了每次复习的都是最高质量的黄金经验。ExGRPO采用了一种混合策略的优化目标,除了对重大性采样进行修正外,在每一次训练迭代中,Mini-Batch中一部分计算资源用于让模型探索全新的问题(On-policy),另一部分则用于学习从经验池中精心筛选出的经验(Off-policy)。巧妙地平衡了探索新知(On-Policy Exploration)和复习旧识(Experience Exploitation)。
- 论文:https://arxiv.org/pdf/2510.02245
- Code:https://github.com/ElliottYan/LUFFY/tree/main/ExGRPO
- 模型:https://huggingface.co/collections/rzzhan/exgrpo-68d8e302efdfe325187d5c96
3、AI在线强化学习“边做边学”,斯坦福团队让7B小模型性能飙升,甚至超越GPT-4o
- 斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o——AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。
- 它由规划器、执行器、验证器、生成器四个专业智能体组成的团队通过共享内存进行协作,利用新方法Flow-GRPO,在系统内部直接对其规划器智能体进行实时优化。
- 以Qwen-2.5-7B-Instruct为基座模型的AgentFlow在10个基准测试中表现突出:
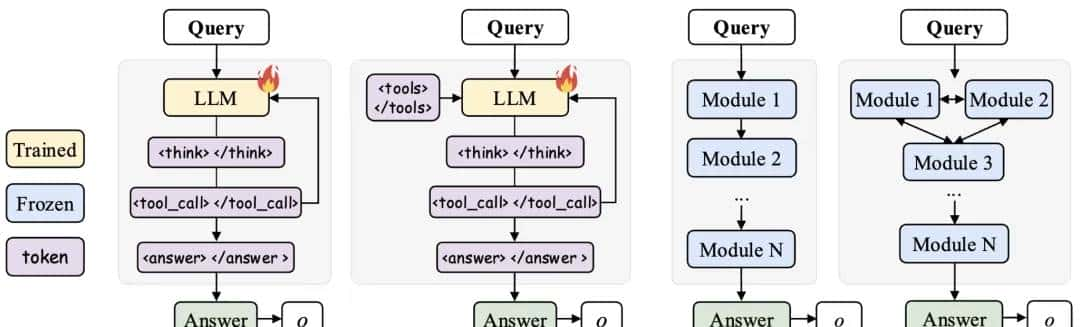
- 搜索任务提升14.9%、智能体任务提升14.0%、数学任务提升14.5%、科学任务提升4.1%。多项任务表现甚至超越比其大50倍的模型,超越GPT-4o、Llama3.1-405B。
- 论文地址:https://arxiv.org/abs/2510.05592
- 项目主页:https://agentflow.stanford.edu/
- Github仓库:https://github.com/lupantech/AgentFlow
- 在线Demo:https://huggingface.co/spaces/AgentFlow/agentflow
- YouTube视频:https://www.youtube.com/watch?v=kIQbCQIH1SI
4、腾讯发布全新ima 2.0:任务模式上线 新增「AI要点」等功能
- 10月23日,腾讯在ima open day活动上正式发布了全新升级的ima2.0版本。作为业界首个融合Agent能力的个人知识库,ima2.0推出了“任务模式”,将知识库从简单的搜索问答工具升级为能够理解复杂任务、自主拆解步骤、调用工具并完成整套流程的智能伙伴。
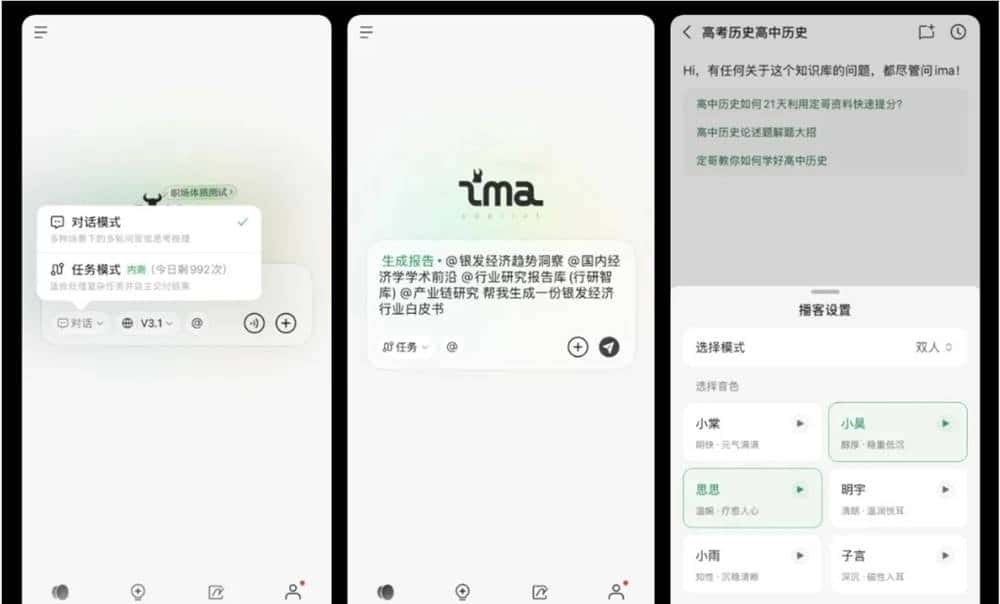
- 用户只需用自然语言发出指令,ima2.0就能理解指令的真实意图,自动拆解任务为多个步骤,调用包括精读、全网搜索、知识库查询、内容生成等工具,逐步完成任务,并在执行过程中自我监测和修正,最终输出可以直接使用的结果。用户还可以附上自己的知识库、文档、图片、音频、网页链接等作为“参考书”,让输出内容更贴近实际需求。
- 除了文字任务,ima2.0的任务模式还支持播客内容的智能生成。用户可以自定义角色、选择音色,快速生成行业访谈、知识讲解、课程内容等多样化音频,适用于教育、营销、个人创作等多元场景。
5、松延动力正式宣布即将发布全球首款万元以内的高性能人形机器人
- 10月22日,松延动力正式宣布即将发布全球首款万元以内的高性能人形机器人Bumi小布米,不仅将人形机器人从实验室拽入消费级市场,更以9998元的震撼价格,让普通家庭也能触碰到曾经高不可攀的科技红利。

- 据悉,这款定价9998元的人形机器人将在双十一至双十二期间,于京东平台开启限时预售,从而象征着一个人形机器人产品走向市场化大时代的开始。
- 新机器人高度仅94cm,尺寸为34.5*19*94cm,重量约12kg,这个重量即使是成年人也能轻松抱起,孩子也能推着它在房间里移动。

- 轻量化设计不仅方便携带,列如带它去参与学校的科技展、户外的亲子活动,还降低了能耗,配合48V电压、≥3.5Ah容量的电池,续航可达1-2小时,覆盖大部分家庭日常使用需求。
- 同时,机器人的材质选择也兼顾了耐用性与安全性:躯干和外壳采用高强度塑料,抗摔耐磨,局部关键部位使用铝合金增强稳定性,表面则做了圆角处理,避免孩子玩耍时被划伤,这些细节设计,都体现了松延动力对家庭使用场景的深度考量。

- 新机器人延续了N2的运动基因,不仅能稳定行走、奔跑,还能完成更复杂的舞蹈动作,无论是节奏感强的流行舞,还是需要精准肢体控制的古典舞,它都能流畅呈现。
- 第三大支柱是智能交互能力,这款机器人并非只会执行指令的机器人,而是能真正实现自然对话交互的伙伴,虽然个头不大,但是它能识别日常语音,理解上下文语境,避免了传统机器人机械感的交流体验。
6、戴上眼镜,就能控物!俄罗斯团队让机械臂“秒懂”你的眼神
- 来自俄罗斯斯科尔科沃科学技术研究院(Skoltech)最新研发的GazeGrasp系统。
- 这个系统最大的亮点是:完全不需要动手,仅凭眼神就能准确控制机械臂抓取和放置物体。对于患有严重运动障碍的人群来说,这无疑是一个福音。研究团队通过引入”磁吸效应”功能,让系统的操作效率提升了31%。13名测试者的实验数据显示,有了这个功能后,用户锁定目标物体的平均时间从6.77秒缩短到了4.65秒。

要让机器人”看懂”你的眼神,可不是一件容易的事。GazeGrasp系统巧妙地整合了多项前沿技术:
- 第一是眼动追踪硬件。研究团队开发了一副特制眼镜,上面装载了ESP32 CAM摄像头模组。这个小巧的设备能够实时捕捉用户的眼球运动,并通过无线网络传输数据。
- 其次是深度学习算法矩阵。系统采用了谷歌的MediaPipe框架来检测和追踪面部特征点,特别是虹膜的位置。这项技术能够在各种光照条件下稳定工作,确保眼动追踪的准确性。
- YOLOv8目标检测模型负责识别工作区域内的物体。它能实时标注出杯子、刀具、瓶子、手机、鼠标等常见物品的位置,并为每个物体生成边界框。
- 研究团队的解决方案是引入”磁吸效应”。当用户的视线接近某个物体的边界框时,光标会自动吸附到物体中心。这就像磁铁吸引铁块一样,大大降低了准确对准的难度。
- 具体来说,当视线进入物体边界框时,系统会执行以下逻辑:如果在边界框内,鼠标位置会自动调整为物体中心坐标;否则,保持原始视线位置。这个看似简单的功能,却让操作效率提升了近三分之一。
- 让机器人准确抓取物体,还需要解决一个关键问题:如何将屏幕上的像素坐标转换为机器人工作空间中的真实坐标。
- GazeGrasp系统采用了精密的坐标转换算法。第一,用户需要进行一次性的校准流程。系统会在屏幕上显示35个预设点,用户依次注视这些点,让系统学习眼球运动与屏幕坐标的对应关系。

- 研究团队使用了三次多项式回归模型来建立这种映射关系。通过这个模型,系统能够将ESP32 CAM捕捉到的虹膜坐标准确转换为屏幕坐标。
- 为了消除眼动数据中的噪声,系统还集成了卡尔曼滤波器。这个经典的信号处理算法能够平滑原始的眼动轨迹,让光标移动更加稳定流畅。
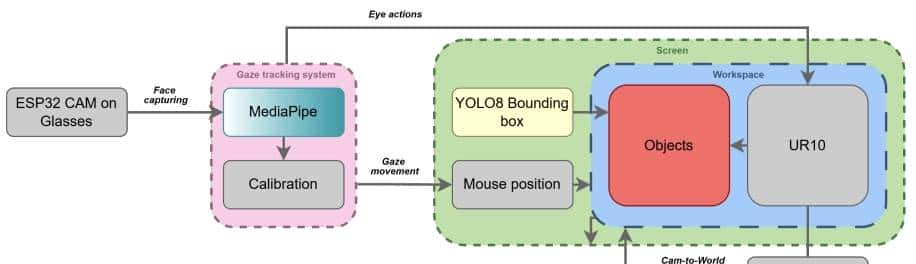
- 最后一步是将检测到的物体中心从相机坐标系转换到机器人基座坐标系。这涉及到相机的内参和外参标定,以及逆投影变换。对于平面工作台,这个过程可以简化为一个单应性矩阵变换。
- 研究团队表明,未来将继续优化系统,包括提升在复杂环境下的鲁棒性、增加避障功能、扩展可识别物体类型等。随着技术的不断完善,用眼神控制机器人或许会像今天用鼠标键盘一样自然。
- 论文地址:https://arxiv.org/abs/2501.07255
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/2.jpg)