
前言
在当今快速发展的 AI 应用生态中,Dify 作为一个开源的大模型应用平台,允许用户轻松构建自定义的 AI 应用。随着 Dify 1.6 的发布,其对工具链的支持更加灵活和强劲。本文将详细介绍如何在 Dify 1.6 中集成 Firecrawl 工具来抓取网页内容,并将其用于构建强劲的信息检索或数据采集类应用。
Firecrawl工具的安装
我们可以在dify的工具页面,找到或者搜索Firecrawl进行安装
安装完成之后,我们就可以点击该工具查看详细
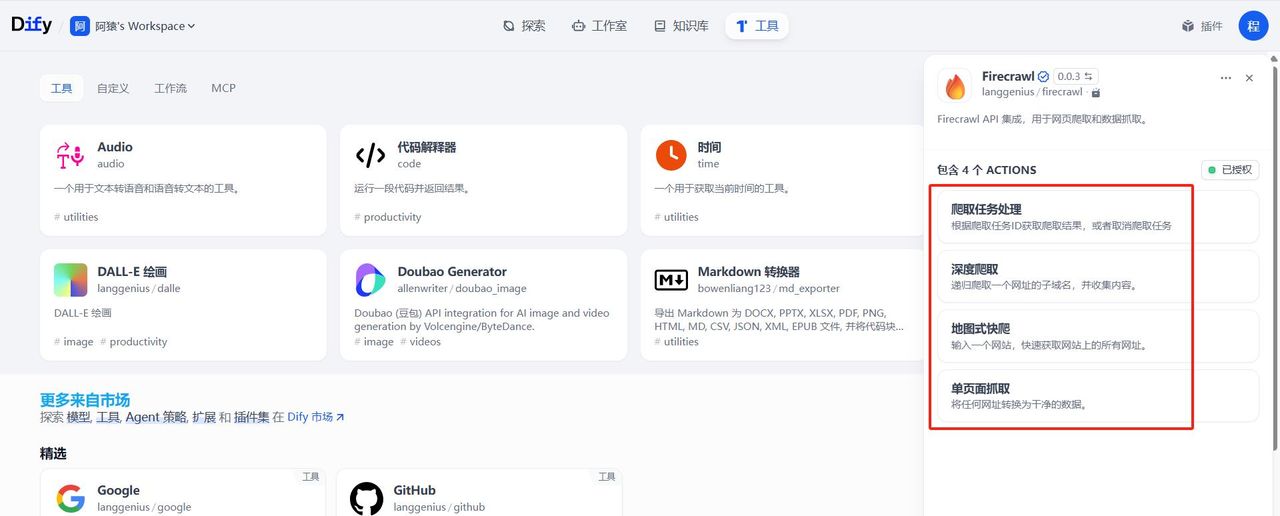
该工具一共包含4个action:
爬取任务处理:根据爬取任务ID获取爬取结果,或者撤销爬取任务
深度爬取:递归爬取一个网址的子域名,并收集内容。
地图式快爬:输入一个网站,快速获取网站上的所有网址。
单页面抓取:将任何网址转换为干净的数据。
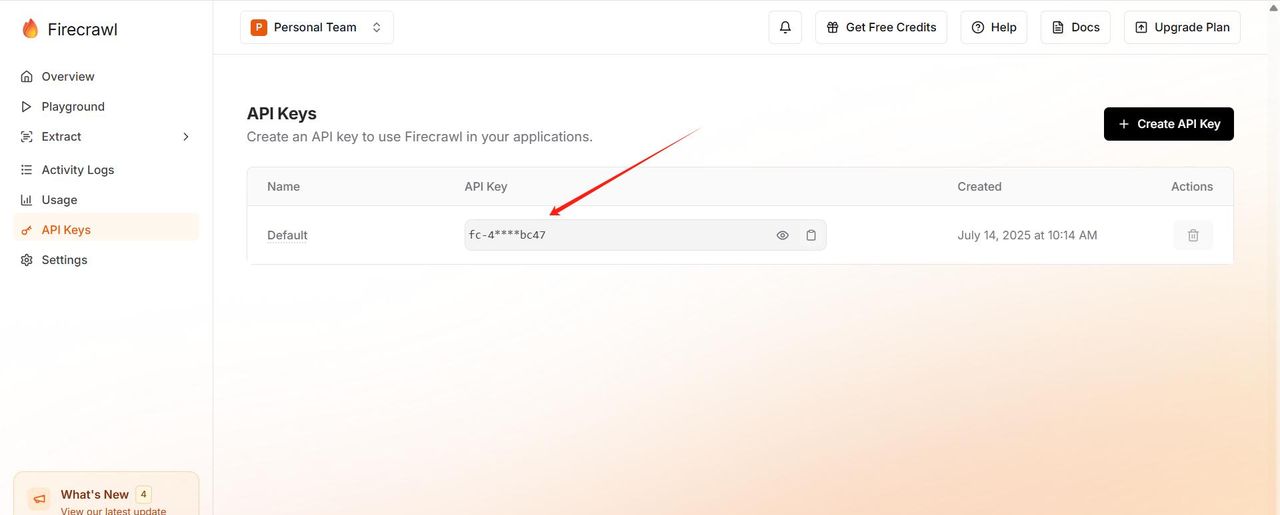
使用Firecrawl工具,需要得到Firecrawl网站的授权

我们到Firecrawl网站去获取key,然后设置到Firecrawl工具中,保存显示已授权,就成功了
网页内容抓取应用编排
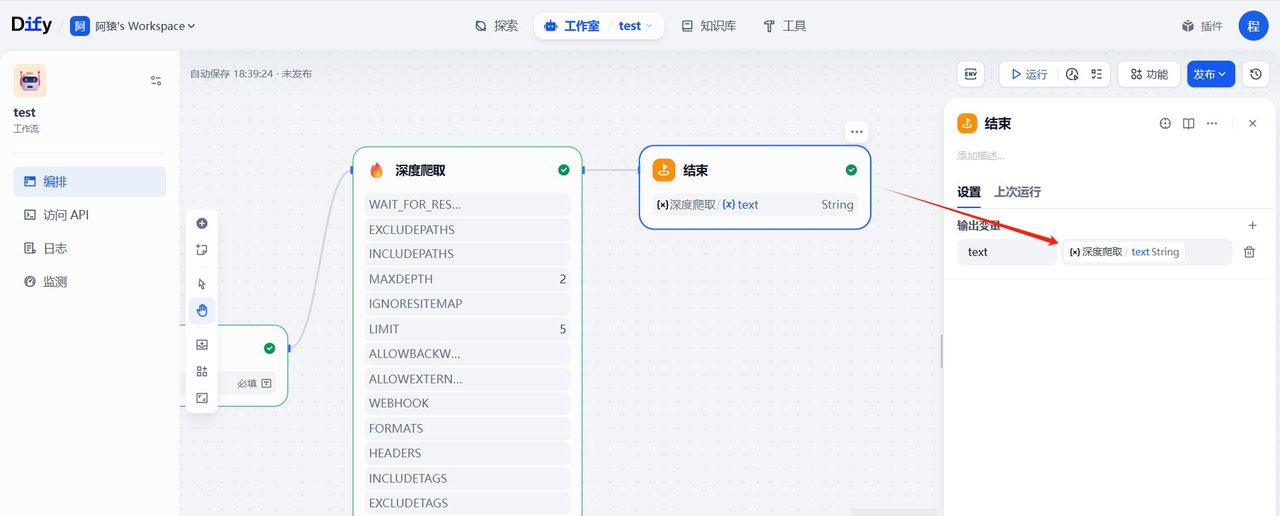
回到dify的工作室页面,我们新建一个workflow的应用,在开始节点设置变量,接受一个网址:

下一个节点选择工具-firecrawl选择深度爬取:

在输出的内容中,我们输出爬取的内容text
点击运行,我们输入一个网址:
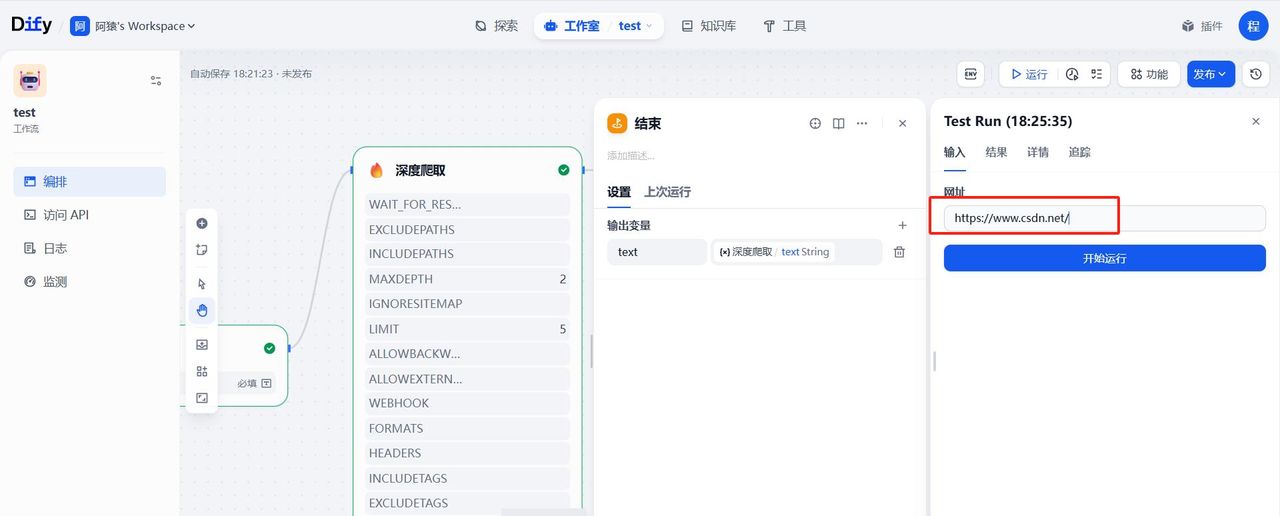
点击开始运行,我们可以在追踪中看执行情况:

执行成功,可以在详情中看输出结果:
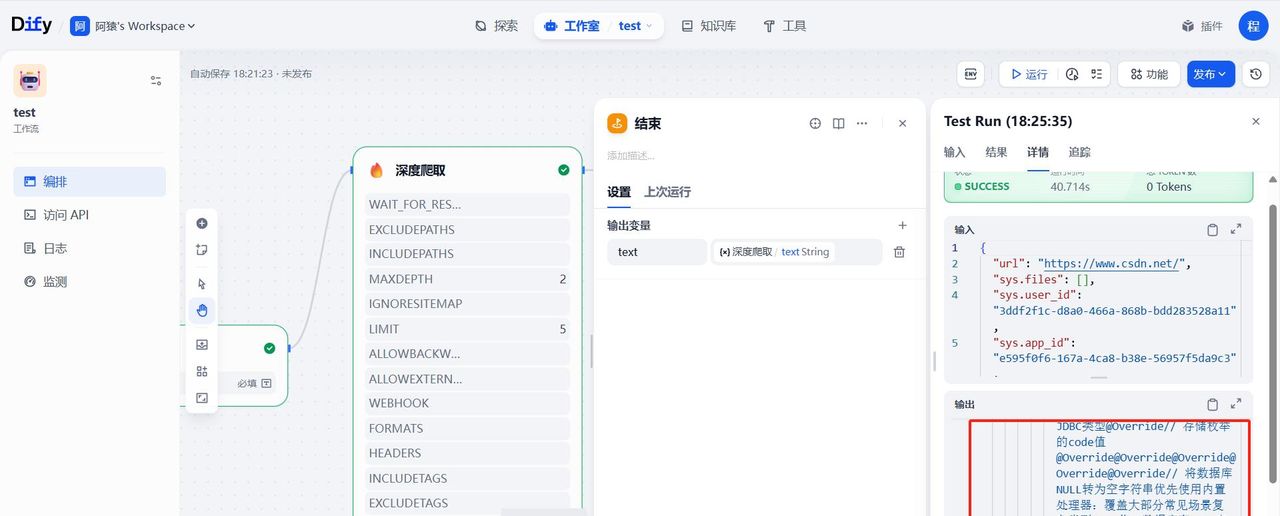
输出的文本如果想做进一步处理,后面可以对应用接着编排,列如输出到文档中,转成markdown格式,或者连接数据库,保存到库里面,都是可以的。
结语
通过 Dify 1.6 的强劲工作流能力和 Firecrawl 的高效网页解析能力,我们能够快速构建一个功能完整的网页内容抓取与摘要系统。这不仅适用于新闻聚合、内容推荐、知识库构建等场景,也为企业级 AI 应用开发提供了极大的便利。如果你正在寻找一种无需编码即可实现复杂任务的方式,Dify + Firecrawl 绝对是一个值得尝试的组合!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章












好思路💪
收藏了,感谢分享