Key Points
☆国内
DeepSeek-OCR把文字当成图片来处理,信息压缩率提升90%;
宇树发布第2款全尺寸人形机器人H2,关节数量较上代增加63%;
iPhone 17标准版在华销量较iPhone 16翻倍;
☆全球
Andrej Karpathy不再鼓吹Vibe Coding,反而说Agent落地还要10年;
Lilian Weng离开OpenAI后公开露面,说研究工作也需要创造「现实扭曲力场」;
亚马逊云服务中断15小时后恢复。☆国内
DeepSeek-OCR把文字当成图片来处理,信息压缩率提升90%
10月20日,DeepSeek发布开源模型DeepSeek-OCR,将传统以语言序列处理的文字,转换为用图像识别的方式处理,从而实现对文档的压缩。
DeepSeek认为,传统的文字输入方式——即通过Tokenizer将语言拆解成最小单元(token)再转化为数字序列——在信息密度、排版特征及语义连续性上均存在天然局限。而视觉输入不仅能保留字体、颜色、格式等多维信息,还可用少量的视觉token来表明本需要大量文本token的内容,显著降低大模型的计算开销。
基于这种压缩方式,DeepSeek-OCR能将视觉上下文压缩至原始信息量的1/10以下,在OmniDocBench评测中,DeepSeek-OCR以更少的视觉token超越了GOT-OCR 2.0和MinerU 2.0等主流文档识别模型。
DeepSeek认为,该模型可以用于对话式AI的「记忆压缩」,通过降低旧对话的分辨率以保留语义主干,从而在不显著增加计算成本的前提下延长模型的上下文长度,模拟人类记忆随时间衰减的特性。有猜测称,这项技术正是Gemini得以保有巨大上下文窗口的关键。
特斯拉前AI负责人、OpenAI初创团队成员Andrej Karpathy在社交平台上对该论文表达赞赏。他表明,DeepSeek-OCR的研究让他重新思考大型语言模型的输入范式——或许未来的AI应该以图像而非文字作为主要输入形式。他长期批评Tokenizer体系「臃肿、低效、充满历史包袱」,认为直接以像素输入能让模型获得更自然的语义感知能力。
参考链接:
https://github.com/deepseek-ai/DeepSeek-OCR
https://x.com/karpathy/status/1980397031542989305
宇树发布第2款全尺寸人形机器人H2,关节数量较上代增加了63%
10月20日,宇树科技发布新一代仿生人形机器人Unitree H2,这是该公司继H1、G1、R1之后发布的第4款人形机器人,以及继H1之后的第二款全尺寸机器人。G1和R1都是身高和体积更小的半尺寸机器人。
00:00
H系列机器人变得像G1和R1一样灵活。
这款机器人身高180厘米,与2023年8月推出的首款全尺寸人形机器人H1身高一样,但体重从H1的47公斤增加至70公斤。官方视频中,H2能模仿芭蕾舞演员动作,还能流畅完成武术等复杂动作,表明即使是难度更大的全尺寸机器人,也能做到G1、R1那样半尺寸机器人的灵敏度。
H2配备31个关节,其中双臂各6个、躯干3个、双腿各7个,关机总数相较于H1提升63%,主要增加了手臂和腰部的活动自由度,使其上肢运动能力接近人类水平。此外,H2在H1的基础上增加了仿生人脸,外观和功能更接近科幻电影中的机器人形象。
参考链接:
https://weibo.com/1818617132/Q9ZqoACHP
iPhone 17标准版在华销量较iPhone 16翻倍
10月20日,Counterpoint Research发布数据称,iPhone 17系列在美国和中国上市前10天的销量分别比iPhone 16系列同期高出14%,其中标准版在中国市场的销量几乎翻倍。
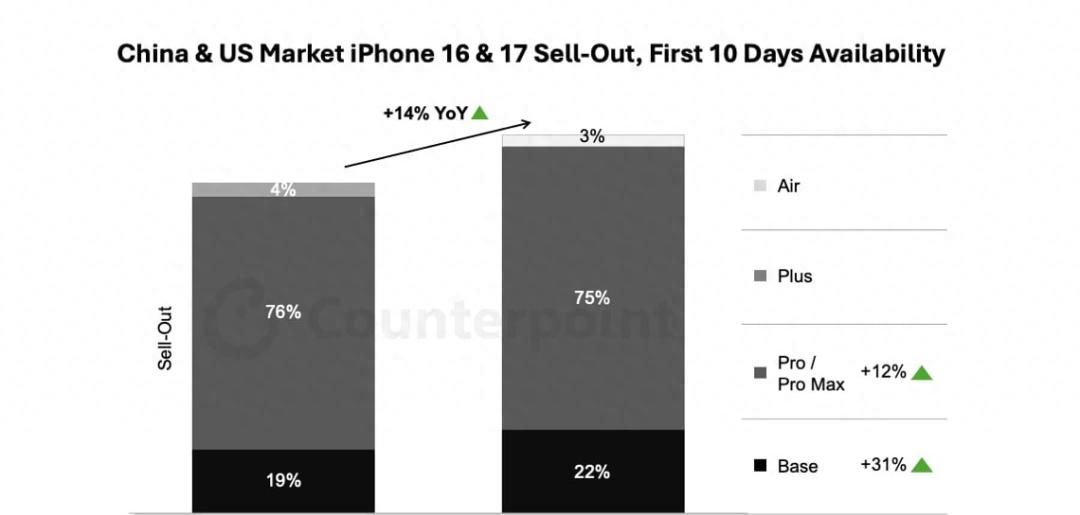
iPhone 17标准版相较于iPhone 16在中国销量翻倍了,在美国并没有。
iPhone 17标准版拥有更好的芯片、改善的显示屏、更高的基本存储空间以及升级后的自拍相机,不过价格却与去年的iPhone 16持平。此外,iPhone 17 Pro Max在美国需求更为强劲,吸引了在疫情期间买上部手机的用户升级换代。
10月20日,苹果天猫官方旗舰店宣布参与天猫「双11」大促,其中,iPhone 17 Pro和Pro Max分别降价300元,而iPhone 17标准版则不参与此次降价。
参考链接:
https://counterpointresearch.com/en/insights/iPhone-17-Far-Outpaces-iPhone-16-Sales-in-China-and-US-During-First-10-Days-of-Availability
全球
Andrej Karpathy不再鼓吹Vibe Coding,反而说Agent落地还要10年
10月18日,OpenAI联合创始人、特斯拉前AI总监Andrej Karpathy在一次播客采访中称:当前的Agent在认知上存在缺陷,也没有持续学习能力。Karpathy以自己编程类Agent的经历为例,指出AI在编程场景中常常会误解用户对代码的需求,把代码复杂化,让最终的代码过于冗杂。
Karpathy认为,业内鼓吹「智能体元年」的提法过度乐观。创造一个能解决基础性缺陷、真正像秘书一样工作的Agent,大约需要10年,需攻克多模态、持续学习、使用计算机等瓶颈。
此外,Karpathy还指出当前训练模型的主流方法——强化学习存在根本性缺点。他认为强化学习要在大量试错后才能获得正确信号,无法像人类通过「反思」「类比」来得出正确结论,效率不高。Karpathy认为尽管现阶段强化学习依然是训练模型的最佳方法,但研究者未来应该研发出更优质的路径。
不过,最初认为AI已经强劲到可以取代人而非辅助人完成编程工作、并为此提出Vibe Coding这个概念的,正是Karpathy本人。他今年2月在X(原Twitter)撰文称,由于AI的存在,编程工作已经变得就像云中漫步一样的优雅体验,用户只需提出需求,AI就能自己生成、迭代和完善代码,而开发者本人已经无需再深入代码细节。
参考链接:
https://www.youtube.com/watch?v=lXUZvyajciY%20
Lilian Weng离开OpenAI后公开露面,说研究工作也需要创造「现实扭曲力场」
10月18日,OpenAI前研究与安全负责人、现Thinking Machines Lab联合创始人翁荔(Lilian Weng)在硅谷HYSTA年会上公开亮相。她回顾了在OpenAI的工作成果,并谈到离开OpenAI后的研究方向与创业路径。同日,她创立的Thinking Machines近期对外发布的「Tinker」API亦成为会场焦点。
年会上,她提到了在OpenAI时期团队研究工作中形成的「现实扭曲力场」。「现实扭曲力场」(Reality Distortion Field, RDF)源自对史蒂夫·乔布斯的描述:当一个人(或团队)对方向有足够的信念并密集试错时,表面「不可能」的目标可以被不断重写边界、最终落地。翁荔把这一心态迁移到科研语境:每个研究者都有属于其个人的小型RDF——在强信念与系统化探索的共同作用下,把难题一步步「扭」进可实现的解空间。

在虚拟环境中训练一套算法,用这套算法控制机械手,使其可以将魔方解开。
2017至2024年在OpenAI任职期间,翁荔早期曾在机器人团队主导「机械手解魔方」等项目,她和团队通过「自动领域随机化(ADR)」等Sim2Real技术,将纯仿真训练的策略迁移到现实世界,最终实现「机械手解魔方」等里程碑。翁荔称,这个过程中,她产生过「如果你信任某个方向,即使它看起来不可能,但只要足够努力、足够机智地尝试,就能找到成功的方法」的「现实扭曲力场」体验。
2024年离开OpenAI后,翁荔参与创办了Thinking Machines Lab,目标是把前沿多模态模型与高可靠训练基础设施做成「人人可用、可定制」的能力平台。
今年10月1日,Thinking Machines发布「Tinker」训练API。Tinker被定义为面向研究者与开发者推出的「托管式微调」(LLM fine-tuning)API:把它想象成「大模型训练的一站式接口」——你只需指定要用的基础模型和训练数据,Tinker就自动处理多机多卡分布式训练、容错与检查点、监控与扩缩容等工程细节,让团队像调用普通API一样快捷地完成微调与实验。Tinker支持LoRA以降低成本,并能够实现从小模型到大型 MoE(如Qwen-235B-A22B)之间一行代码切换。
Thinking Machines称,这些做法能够帮研究者在保留算法与数据主导权的同时,将分布式多GPU训练、容错与资源编排外包给平台。
目前,Tinker已覆盖Llama与Qwen等开源权重模型,并支持将训练后的权重下载到外部环境使用。产品已进入私测阶段,被普林斯顿、斯坦福、伯克利与红杉的研究团队用于真实项目场景。计划先免费开放,后续按用量计费。
参考链接:
https://lilianweng.github.io/
https://mp.weixin.qq.com/s/bZXfHtyCw9G7lWr_ihbn9g
亚马逊云服务中断15小时后恢复
10月20日,亚马逊AWS云服务在经历约15个小时的服务中断后,在纽约时间下午6点左右恢复正常运行。这次云服务中断波及包括亚马逊、Snapchat、Facebook、 Apple Music、Apple TV,以及游戏平台Fortnite和学习平台Canvas等。AWS的服务状态页面显示,本次服务中断的触发缘由是「亚马逊北部弗吉尼亚州数据工厂的DNS域名系统发送错误」。
© 版权声明
文章版权归作者所有,未经允许请勿转载。














既然能够以图像处理文字,那是不是意味着图像与文字这两种模态未来可以更加统一起来,比如让模型绘制Excel表格…