
原创内容实属不易,请大家多多添加关注。本号将重点聚焦于与人工智能算力中心投建营的全流程方案研究,结合实际项目经验进行总结,希望能够为大家带来协助。
人工智能算力中心项目,按项目阶段主要分为投资、建设、运营三部分,按服务内容分为通算平台、智算平台、超算平台。本文重点介绍智算平台的人工智能开发平台网络架构常用技术,其他内容请参考本号其他章节。
一、RDMA技术
RDMA全称是Remote Direct MemoryAccess,即远程直接内存访问,在概念上是相对于DMA而言的。指外部设备能够绕过CPU,不仅可以访问本地主机的主存,它还可以访问另一台远端主机上用户态的系统主存。是一种用于高性能网络通信的技术。RDMA技术可以让计算机直接访问远程计算机的内存,而无需在本地和远程计算机之间进行数据复制。
相比传统的网络通信方式,RDMA技术具有更低的延迟、更高的带宽和更低的CPU利用率等优点可以显著提高网络通信的性能和效率。目前支持RDMA的网络协议主要有:InfiniBand、ROCE、iWARP。
传统通信示意图:

在传统的Socket套接字网络中,应用程序向操作系统申请网络资源时,要通过特定的API来管理程序的行为。
RDMA通信示意图:

RDMA仅仅使用操作系统建立一个通道,然后就可以再不需要操作系统干预的情况下,应用程序之间既要能进行直接的消息传递。
二、IB网络技术
Infiniband是一种高带宽、低延迟、高可靠性的开放标准网络互连技术,这项技术是由 IBTA (InfiniBand Trade Association)定义的,该技术在超级计算机集群领域得到了广泛的应用。
Infiniband在物理层定义了多种链路速度,如x1链路、x4链路、x12链路,每个单独的链路都是四线串行差分连接(每个方向两根线),目前大多采用x4链路,当前Infiniband主流常见网络类型参考如下:

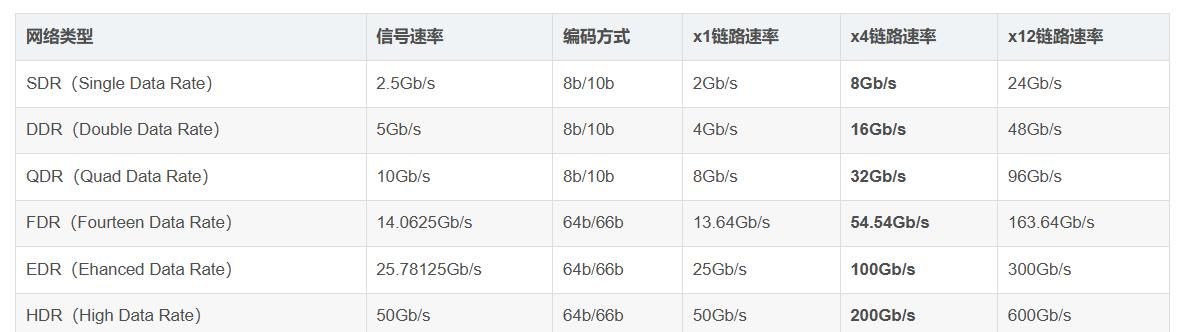
1、IB网络硬件设备
(1)网卡
高端网卡一般支持IB RDMA,可以接入IB交换机,具体支持情况需要根据产品规格进行确定。网卡按照速率可分为QDR(40Gb)、EDR(100Gb)、HDR(200Gb)及NDR(400Gb)
(2)光模块
光模块在数据通信行业中起着关键的作用,SFP、SFP+、SFP28、QSFP+、QSFP28、QSFP56、QSFP-DD和OSFP是不同类型的光收发器。
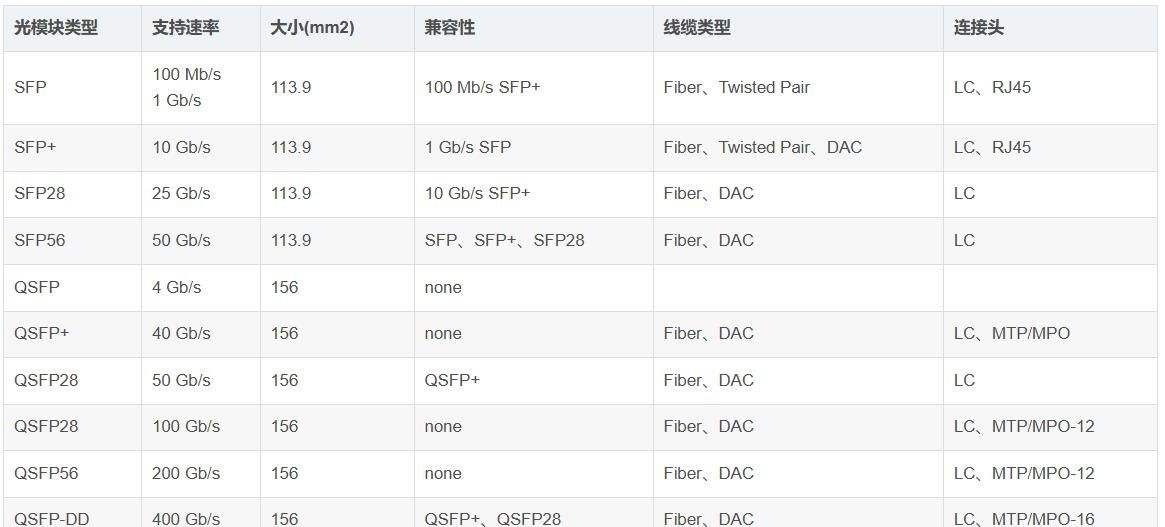
(3)线缆
Infiniband网络中,使用的线缆区别于传统的以太网线缆和光纤线缆。针对不同的连接场景,需使用专用的InfiniBand线缆,可分为DAC高速铜缆、AOC有源线缆两种,两者材质不一(前者使用铜缆、后者使用光纤),AOC有源线缆价格要高于DAC高速铜缆
(4)交换机
Infiniband网络需使用专用的IB交换机
2、IB网络组网方案-DGX BasePOD A100
(1)DGX A100 整机规格
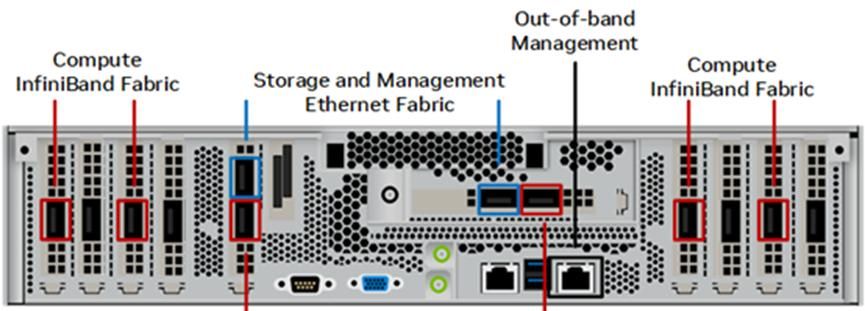
DGX A100 端口面板
CPU:Dual AMD EPYC™ 7742 CPUs, 128 total cores, 2.25 GHz (base), 3.4 GHz (max boost).
GPU:Eight NVIDIA A100 GPUs. 40 GB or 80 GB GPU memory options. Six NVIDIA NVSwitch™ chips.
内存:Up to 2 TB of system memory.
网卡:Eight NVIDIA ConnectX-6 or ConnectX-7 InfiniBand HCAs.
解析1:NVIDIA ConnectX-6 最大支持200Gbps,PCIe 4.0(x16,最大32GB*8=256Gbps,所以200G网卡用PCIe 4.0);NVIDIA ConnectX-7 最大支持400Gbps,PCIe 5.0.
解析2:一般推荐配置8块HDR InfiniBand网卡。在DGX-A100服务器内的 NVLink 传输带宽高达的 600 GB/s(4,800 Gbps),但是目前PCIE性能最高的网络就是HDR的InfiniBand网络,PCIE 4.0 只有200Gb/s带宽,显然无法满足以4,800 Gbps速度将数据跨服务器传输。但是由于PCIe规范的限制,以目前的系统设计而言,8张HDR InfiniBand网卡提供1,600Gb/s的带宽是个最佳的设计。尽管相对于4,800 Gbps的内部速度而言,这个速度还是远远不够,但是这是目前能做到的最大限度
系统盘:Two 1.92 TB M.2 NVMe drives for DGX OS
数据盘:eight 3.84 TB U.2 NVMe drives for storage/cache.
电源:6.5 kW max power.
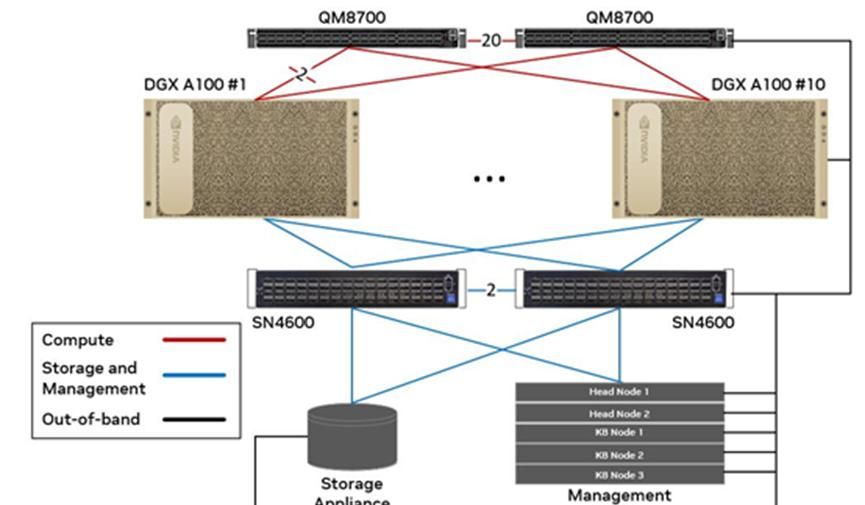
(2)DGX A100 BasePOD 方案
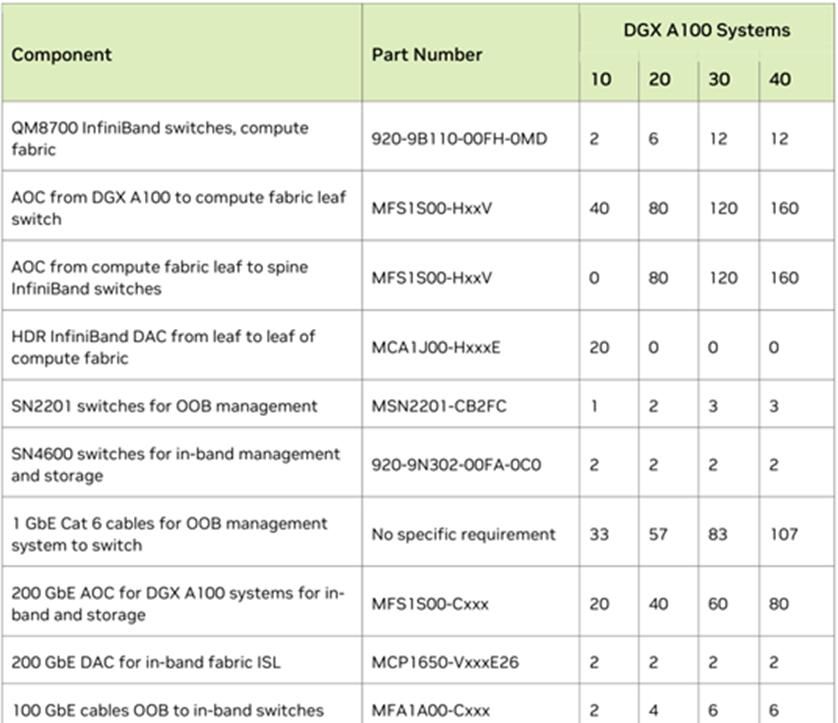
DGX BasePOD方案中A100使用4x200G连接到计算IB Fabric,2x200G连接存储&管理以太网Fabric,带外管理接入单独的OOB以太网网络,IB交换机胖树组网,收敛比1:1。部署10-40台A100节点,5台x86服务器部署管理节点。
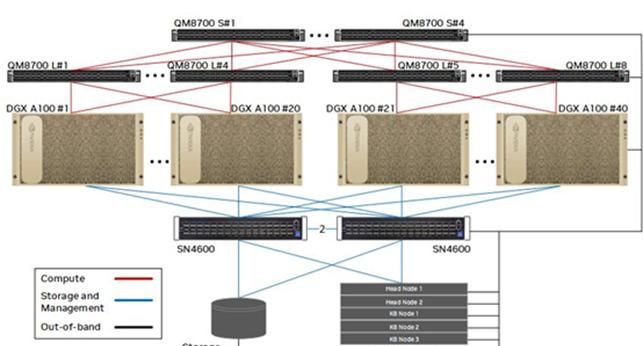
如果10台以内A100节点,只有两台Leaf交换机互连即可,收敛比1:1。
耗材清单:
3、IB网络组网方案-DGX H100 NDR200
(1)DGX H100 整机规格
GPU:Eight NVIDIA H100 GPUs. 80 GB GPU memory.Four NVIDIA NVSwitch™ chips.
CPU:Dual 56-core fourth Gen Intel® Xeon® capable processors with PCIe 5.0 support.
内存:2 TB of DDR5 system memory.
网卡:Four OSFP ports serving eight single-port NVIDIA ConnectX-7 VPI, three dual-port
NVIDIA ConnectX-7 VPI.
系统盘:Two 1.92 TB M.2 NVMe drives for DGX OS,
数据盘:eight 3.84 TB U.2 NVMe drives for storage/cache.
电源:11.3 kW max power
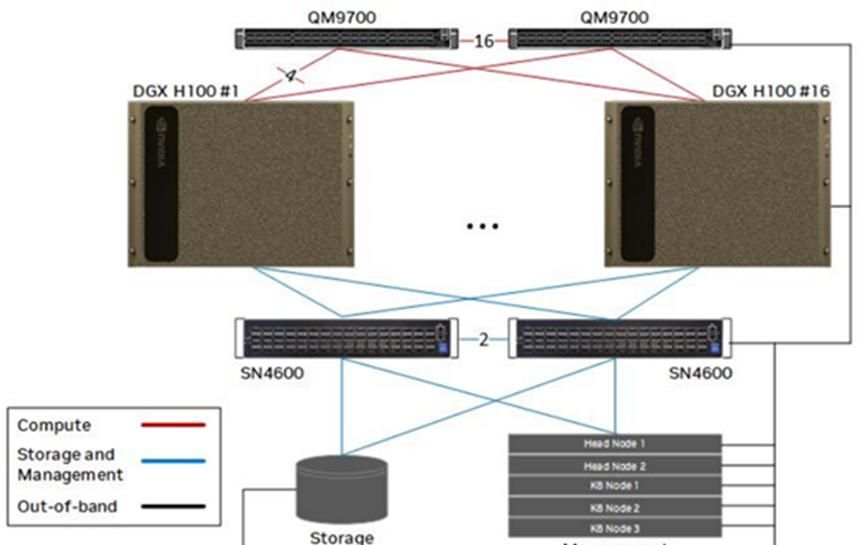
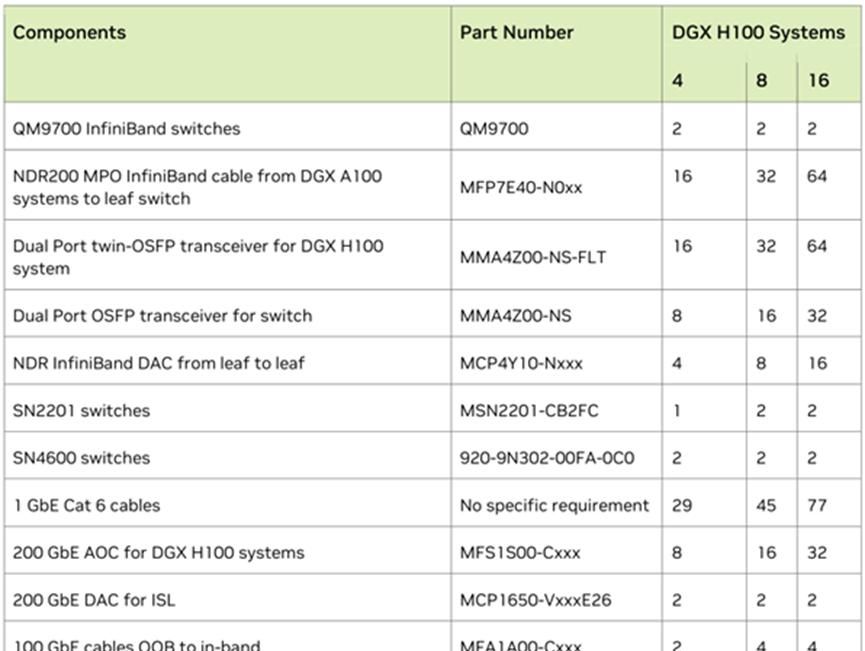
(2)DGX BasePOD H100 方案
DGX BasePOD 方案中,QM9700之间16x800G(NDR)互连,每个H100 8x200G接入IB计算Fabric,2x200G连接存储&管理以太网Fabric,带外管理接入单独的OOB以太网网络。
部署16台H100节点,5台x86服务器部署管理节点。
耗材清单:
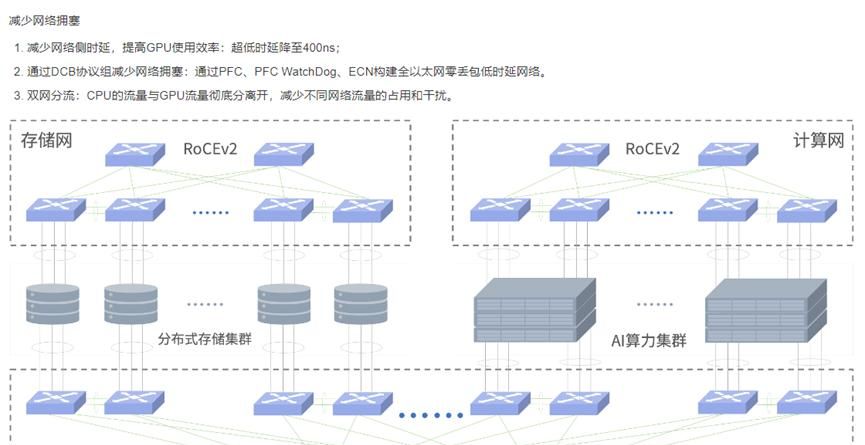
三、ROCE网络技术
ROCE网络,基于 Ethernet的RDMA,RoCEv1版本基于网络链路层,无法跨网段,基本无应用。RoCEv2基于UDP,可以跨网段具有良好的扩展性,而且可以做到吞吐,时延相对性能较好,所以是大规模被采用的方案。RoCE消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,但是需要支持RoCE的网卡。
1、ROCE网卡
在RoCE v2技术体系中,核心硬件设备之一是RoCE网络接口卡(简称RoCE网卡),这种专门设计的网卡旨在高效支持RDMA操作。作为系统间直接内存访问的关键实现载体,RoCE网卡集成了必要的硬件特性,能够将CPU从繁重的RDMA任务中解脱出来,从而显著降低数据传输延迟,并有力提升整个系统的运行性能。

2、ROCE交换机
构建高性能网络交换机的核心基础在于其采用的转发芯片技术。值得一提的是,Tomahawk3系列芯片已广泛应用于各类交换机产品之中,且随着市场趋势的发展,越来越多的交换机开始支持更新一代的Tomahawk4系列芯片。这种向更先进芯片技术的过渡进一步突显了这些芯片在当前商业领域中的重大地位,它们被普遍用于高速、大容量的数据包转发处理。

目前正在生产的 Tomahawk4 系列成员包括 Tomahawk4-50G、Tomahawk4-100G 和 Tomahawk4-12.8T,Tomahawk4 设备提供的各种 SerDes 速度和带宽点可直接连接到大容量 200Gbps、400Gbps 和 800Gbps 光纤
华为RoCE交换机 CloudEngine 9800

华三RoCE交换机 S6805

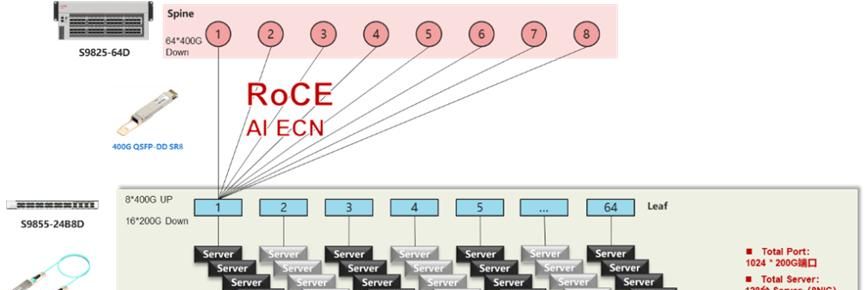
3、ROCE组网方案–新华三
2级Clos TH4+TD4组网方案,最大提供1024个200G端口接入能力
|
产品名称 |
产品型号 |
产品描述 |
数量 |
备注 |
|
Spine交换机 |
S9825-64D |
64个400G端口(QSFP-DD) |
8 |
Spine 交换机40端口 |
|
200G IB交换机 |
S9855-24B8D |
8个400G端口,16个200G端口 |
64 |
Leaf 交换机40端口 |
|
400G QSFP-DD SR8 |
512 |
Spine 到 Leaf 之间互连线缆 |
||
|
200G QSFP56 AOC |
1024 |
Leaf 到Server 之间互连线缆 |
||
|
Server配置 |
128台 Server (8NIC) |
四、ROCEv2与infiniBand技术对比
RoCE v2(基于以太网融合的RDMA第二版)和InfiniBand均为针对数据中心及高性能计算环境设计,旨在提供高速、低延迟通信解决方案的技术。以下从不同层面剖析两者的关键差异。

End-to-End Delay:端到端时延
Flow Control Mechanism:流量控制
Forwarding Mode:转发模式
Load Balancing Mode:负载均衡模式
Recovery:恢复
Network Configuration:网络配置
1、物理层架构
· RoCE v2:依托于现有的以太网基础设施,允许在同一网络中整合存储数据流和常规数据流量,因此更易于融入既有的数据中心架构。
· InfiniBand:采用独立于以太网之外的专有通讯结构,一般需要专门构建的InfiniBand网络,并可能涉及独立的线缆布设和专用交换机设备。
2、协议栈与网络协议兼容性
· RoCE v2:通过以太网实现RDMA(远程直接内存访问)功能,其能够与传统的TCP/IP协议栈无缝集成,从而确保了对标准网络协议的兼容性。
· InfiniBand:配备了一套专为高速、低延迟传输优化定制的自有协议栈和网络架构,使用时可能需要安装特定的驱动程序和进行相应的配置调整。
3、交换机制
· RoCE v2:能够在支持数据中心桥接(DCB)特性的标准以太网交换机上运行,从而实现无损以太网的数据传输。
· InfiniBand:则依赖于专为追求最低延迟和最高吞吐量而设计的InfiniBand交换机,以保证极致性能表现
4、拥塞管理与控制
RoCE v2:
· 拥塞管理:RoCE v2依赖于以太网交换机所支持的数据中心桥接(DCB)特性来有效应对网络拥塞状况。通过启用DCB,RoCE v2能够创建一个无损以太网环境,从而避免因拥塞导致的数据包丢失问题。
· 拥塞控制:RoCE v2本身并不具备内置的专门解决方案,而是主要依靠底层以太网基础设施所提供的功能来管理和缓解拥塞现象。
InfiniBand:
· 拥塞管理:InfiniBand具备原生的拥塞控制能力。它运用信用流控等机制,确保即使在网络流量高峰时期也能防止拥塞发生,保障通信过程中的数据完整性。
· 拥塞控制:InfiniBand还整合了自适应路由和先进的拥塞控制算法,这些算法能够根据实时网络状况动态调整数据传输路径,从而有效地预防和减轻网络内的拥塞问题。
5、路由机制与拓扑结构
RoCE v2:
· 路由机制:RoCE v2一般采用传统的以太网路由协议进行路由决策,如路由信息协议(RIP)或开放最短路径优先(OSPF)。这意味着RoCE v2网络中的数据传输路径选择是基于这些成熟的标准路由协议实现的。
· 拓扑结构:RoCE v2普遍应用于标准以太网环境之中,其路由策略的制定和执行受到底层以太网基础设施的制约和影响。这意味着在设计和实施RoCE v2网络时,需要思考现有的以太网架构,并根据该架构的特点来进行路由优化。
InfiniBand:
· 路由机制:InfiniBand具备针对低延迟、高吞吐量通信特别优化的路由机制,它能够支持多路径设定以实现网络冗余及负载均衡,确保高效稳定的传输性能。
· 拓扑结构:InfiniBand网络支持丰富的配置方式,包括但不限于胖树形(Fat Tree)、超立方体以及多路配置等多样化布局。不同的拓扑结构选择对路由决策有着直接影响,可根据实际应用场景和需求灵活构建高度可扩展且适应性强的高性能网络。
在选择RoCE v2与InfiniBand这两种技术时,决策依据主要源于现有的基础设施条件、特定应用需求以及实际环境的具体性能指标。RoCE v2的一大优势在于能够更加平滑地整合到已有的以太网网络架构中,这对于希望在不改变现有网络基础的前提下提升数据通信效率的用户尤为适用。
相反,对于那些追求极致性能表现和高度可扩展性的高性能计算场景,InfiniBand则因其专为低延迟、高吞吐量设计的特性及内置优化的路由与拥塞控制机制而可能成为更优的选择。简而言之,RoCE v2更适合于充分利用现有资源进行高效升级,而InfiniBand则更倾向于满足对性能有严格要求且不吝啬投入独立专用网络设施的高端应用场景。
此为系列文章,详细描述智算平台投资、建设、运营相关的规划设计、架构原理等,此关注本号其他章节。
- 《投资智算中心—“投-建-运”一体化服务》
- 《建设智算中心-三大运营模式篇》
- 《建设智算中心-改善运营服务模式,提高算力利用率》
- 《建设智算中心-用户群体与业务场景分析》
- 《建设智算中心-Flops算力与大模型参数、GPU卡型号间关系》
- 《建设智算中心-需满足企业等保合规要求》
- 《建设智算中心-满足生成式人工智能服务安全基本要求》
- 《建设智算中心-需获取的相关认证》
- 《建设智算中心-通算、智算、超算业务架构》
- 《建设智算中心-多元算力中心组网拓扑图》
- 《建设智算中心-通算平台整体功能架构(1)》
- 《建设智算中心-通算平台整体功能架构(2)》
- 《建设智算中心-通算平台标准组网模式》
- 《建设智算中心-通算平台计算架构原理》
- 《建设智算中心-通算平台存储架构原理》
- 《建设智算中心-通算平台网络架构原理》
- 《建设智算中心-通算平台三级等保建设方案》
- 《建设智算中心-通算平台双活/灾备/迁移机制》
- 《建设智算中心-人工智能开发平台业务架构图》
- 《建设智算中心-人工智能开发平台业务流程图》
- 《建设智算中心-人工智能开发平台组网架构图》
- 《建设智算中心-人工智能开发平台计算架构常用技术》
- 《建设智算中心-人工智能开发平台存储架构常用技术》
- 《建设智算中心-人工智能开发平台网络架构常用技术》
© 版权声明
文章版权归作者所有,未经允许请勿转载。









![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/7.jpg)


收藏了,感谢分享
谢谢