780M能够使用OLLAMA么,怎么用呢?
为什么要用OLLAMA?貌似启动ROCM后,它的速度比LM Studio的vulkan模式要快一些。同样用qwq 32b:
- lm studio:输出速度大致是1~2之间;
- OLLAMA:输出速度大致是3~4之间。
如何安装780M核显能够使用的OLLAMA,B站上已经有比较完整的教程了,包括五个步骤(教程中主要说了四个步骤):
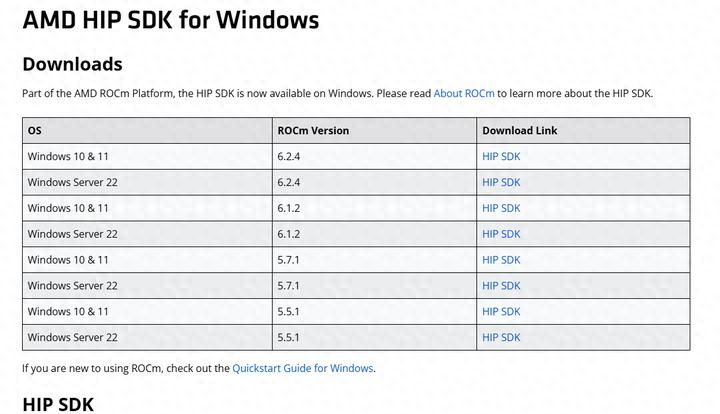
第一,安装AMD官方的ROCM程序。下载地址:AMD HIP SDK for Windows,可以直接下载最新版的6.2.4,不用教程中的6.1.2。
添加图片注释,不超过 140 字(可选)
第二,安装ROCM魔改版版的OLLAMA程序。下载地址:Releases ·
likelovewant/ollama-for-amd · GitHub,选择和amd rocm 6.2.4对应的安装程序,图中红圈1的部分。红圈2的部分,是GPU rocm库的链接,下一步要下载的。

添加图片注释,不超过 140 字(可选)
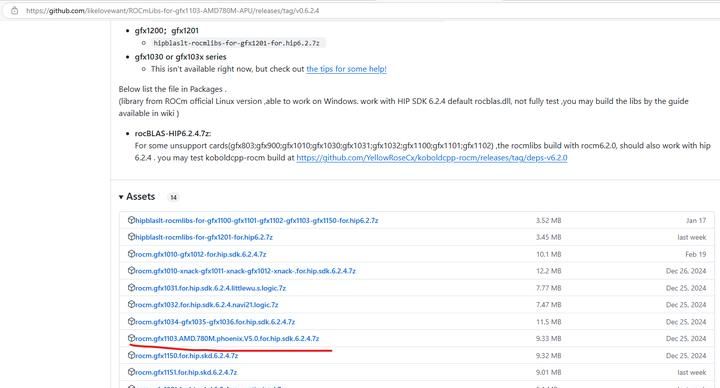
第三,用魔改版的780M库替换第一步和第二步的库,下载地址:Release v0.6.2.4 ·
likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU · GitHub。780M对应的是gfx1103,下载这个替换掉上面的就可以。
AMD HIP SDK默认安装位置:C:Program FilesAMDROCm6.2,
OLLAMA默认安装位置:C:UsersgavinAppDataLocalProgramsOllamalibollama
ocm
需要替换的主要是两大块:
第一,替换这个:rocblas.dll
第二,替换这个目录下的文件:C:UsersgavinAppDataLocalProgramsOllamalibollama
ocm
ocblaslibrary,(OLLAMA);
C:Program FilesAMDROCm6.2in
ocblaslibrary,(AMD HIP SDK)。
添加图片注释,不超过 140 字(可选)
第四,设置rocm path(如果你用一键安装的话,这一步好像可用可不用)。
第五,Bios中的显存设置为2g左右,大家可以试一下上限多少。这一步教程没说,如果你设置为16G,对于超出16G的模型,反而由于爆显存无法加载。我不知道ollama的机制是什么…
这个和LM studio不一样。LM studio如果用vulkan模式,bios中设置显存越大越好;而LM studio的ROCM模式,我的780M核显一直过不去,增加了gfx1103也不行,如果有人搞定了,还请告知。
上面几步做完后,开一个cmd窗口,输入“ollama serve”,将ollma服务开启。
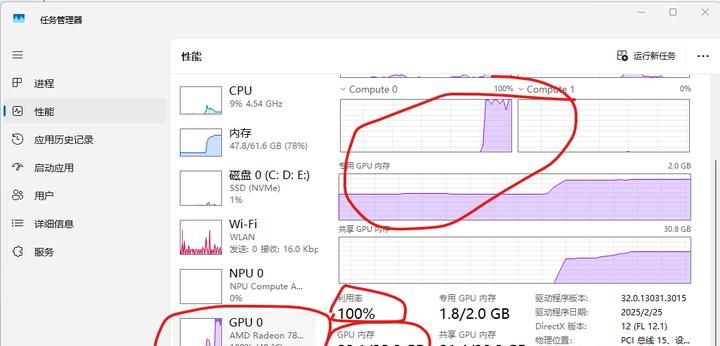
然后再开一个cmd窗口,输入”ollama run qwq:32b “,就会开始下载,下载完后载入模型。可以通过windows“任务管理器”查看CPU/GPU的使用情况:
添加图片注释,不超过 140 字(可选)
运行下来gpu温度和cpu温度,远低于8845笔记本的,这也是桌面处理器的优势了。
也可以再开一个cmd窗口,运行“ollama ps”,查看:

添加图片注释,不超过 140 字(可选)
如果模型占用内存太多,ollama会自动分配gpu和cpu的加载。
实则还是挺方便的。
后续还可以衔接anythingllm来做本地知识库。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...