我在 Mac Studio 上把 Ollama 和 Qwen2.5‑VL 7B 整套跑通了,能在本地直接让模型看图、读字、把票据和表单里的字段抽出来,还能用 Python 调接口做自动化处理,延迟低,响应够快。说白了,就是把一个能看图片会读字的模型放到自己电脑上跑,能直接把截图、票据、手写备注啥的变成结构化的数据,方便后续写脚本处理,隐私也放心点。

我先说测试结果,给个直观印象:丢一张包含表格、票据和手写备注的截图进去,出来的东西挺实用。识别出来的文字不只是贴一串字符,还能给每段文字的位置坐标,甚至把票据里常见的字段像“发票号”“开票日期”“合计金额”这些拆出来当键值对给你。公式能把符号和字符串化的表达识别出来,复杂排版有时候会乱,但平常遇到的公式基本够用。图片检测那块,除了文字,它对复杂场景里的物体也能做出基本标注,虽然不能像专业视觉模型那样精细,但日常自动化流程里已经省了一堆人工工序。
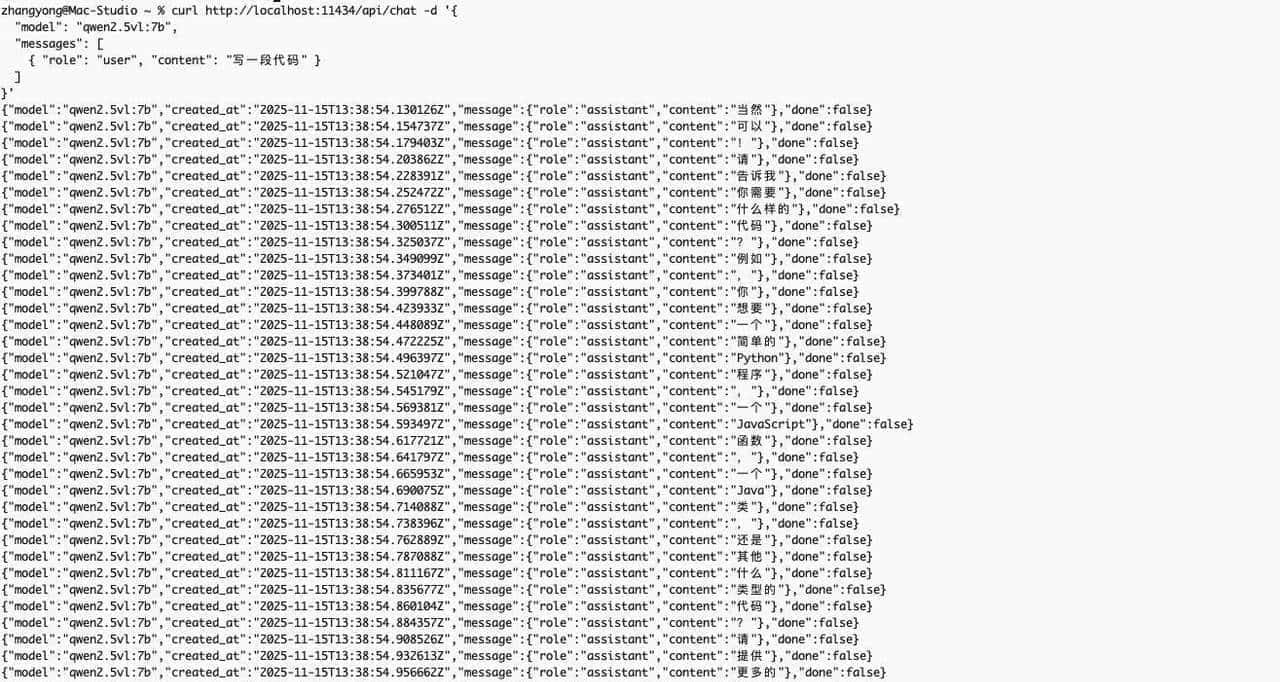
我用了两种调用方式:在 Ollama 的 GUI 里直接拖图上传,以及用 Python 调本地接口。两条路子输出基本一致,GUI 直观,上手快;Python 更好整合到自动化流水里。用 Python 时是请求本地 Ollama 服务,发图片(base64 或文件路径都行),回来的 JSON 包含文本段落、置信度、位置信息这些字段。我把置信度当筛子:低于阈值的字段打上“需人工复核”,这样半自动化的流程既省力又稳妥。还有一点挺好用:Ollama 对 OpenAI 协议有兼容性,流式输出能做实时预览,模型“想”一点返回一点,交互感觉接近在线大模型那种体验。
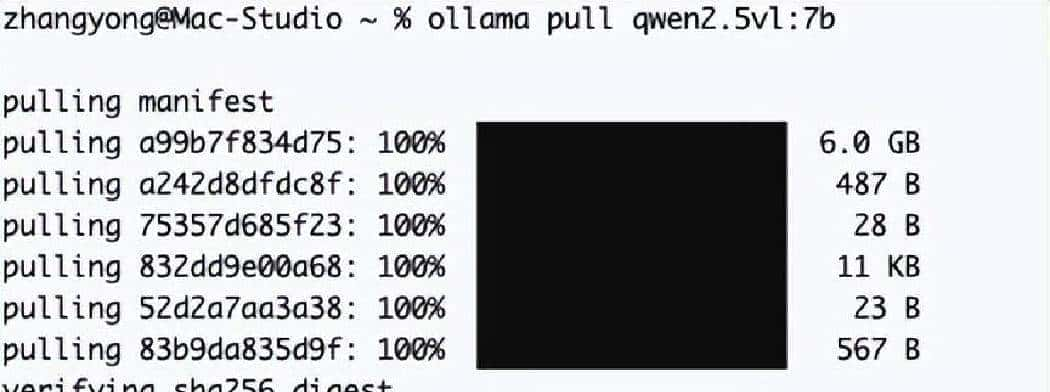
安装过程不难,我是在 Mac Studio 上跑的,步骤像安装普通 mac 应用那样:从官网拿 macOS 安装包,双击装好打开就能看到可用模型。如果界面没下好 Qwen2.5‑VL,会显示下载标识,点一下对话框里随意输句话就能触发下载,不用去折腾命令。要是习惯命令行管理的,也可以用命令拉取模型、启动服务,适合批量部署或者写脚本自动化。模型文件不小,7B 版本占用不菲,准备好磁盘和带宽别临时抱怨。启动模型时,CPU 和内存占用会上来,Mac Studio 的多核多内存优势会显得挺重大。
说下模型本身的背景,Qwen2.5‑VL 是通义千问里一类能同时理解文本和图像的视觉语言模型系列里的版本。它有不同参数量的变体,像 3B、7B、72B 那种,7B 是一个折中选项,既能在本地跑又有不错的能力,适合想离线处理票据、表单、截图之类任务的场景。它可以做 OCR、表单抽取、证件识别、简单场景理解,连一些公式的字符串化也行。
在识别质量上有几个要注意的地方。清晰、正拍、印刷体的文字识别准确度高,遇到倾斜、压缩、反光或拍糊了的照片,识别率就掉链子了,需要些预处理步骤。列如先做旋转纠偏、裁切、调对比度这些,效果能上去一截。手写体识别能力弱于印刷体,能看出大致内容但字符错误率高,最好配上人工校验或后续校正算法。对表单类图片,我让模型按请求输出 JSON 样式字段:给出键名“发票号”“金额”“日期”,模型会把识别到的对应文本填进去,拿到的数据格式化方便直接导入数据库或 Excel。
在开发对接方面,细节给得更清楚点。先启动 Ollama 服务进程,确认本地端口和鉴权设置(如果你启用了认证),然后用 requests 或官方 SDK 发请求。请求体可以带图片的 base64,也可以直接传文件路径。参数可以指定输出格式:纯文本、结构化 JSON 或流式。返回的 JSON 包含每段文本的位置、置信度等字段。我把置信度设定成阈值,低于就标成“需人工复核”,高于就直接进自动化流程。这个做法在真实业务里能把自动化和人工复核结合起来,降低错误率同时节省大量人力。

我还做了对图像检测的细化测试。把图片裁切成单页票据、截图、还有一张有折叠边的收据去试,发现对折叠边、裁损或边缘被遮挡的文字识别效果会下降。对复杂排版的表格,模型能识别出格子里的文字,但要把复杂的合并单元格、嵌套表头结构准确重建成原来的表格样式,有时还需要把模型输出再跑一层解析规则。也试了各种燃眉之需的小技巧:对倾斜图片先跑个自动纠偏,对低对比图片先增强一下,这些预处理往往比换模型更省事。
关于稳定性和速度,7B 在 Mac Studio 上表现挺平衡。响应速度比远程接口要快得多,尤其是图片体量不大的情况下,延迟低,交互上能感觉到“顺手”。本地运行的好处还在于数据掌控更强,处理敏感文档时不用担心把数据丢给云端。缺点也很明显:本地资源是瓶颈,模型越大需要越多内存和算力。想要更高精度,可能得思考 72B 那类更大模型,但那就不是普通台式机能吃下的了。

实践中,我把这种本地部署的流程应用在几个场景里做了试验:批量票据处理、截图信息抽取、现场拍照的文字识别、简单图表读取这些场景都可行。用流式输出做实时预览,可以把识别步骤放到操作台上,拍照后模型逐步返回识别结果,操作人员看到中间结果就能决定是否重拍或人工介入。再搭配后端的自动化脚本,把模型输出的 JSON 转成数据库记录或表单字段,整个链路从拍照到入库可以做到半自动,效率提升明显。
最后提一句兼容性和生态。Ollama 对 OpenAI 协议的兼容性让一些现有工具能少改接口就接入,这点对已经有工具链的团队特别友善。流式对话、中间件、可视化调试工具都可以较容易地接上本地服务,节省开发改造成本。GPU/CPU 分配、模型版本管理这些,想做规模化部署的话还是要走命令行和脚本自动化的路子,GUI 适合试验和小规模使用,命令行适合生产环境。

在我这套实验里,Qwen2.5‑VL 7B 表现出来的是一个可实用的视觉语言工具,能做 OCR、表单抽取、场景标注和必定程度的公式解析。它有两条好用的接入路:GUI 直观快速、命令行/接口适合自动化;支持 Python 调用,能很方便地把识别结果接入现有流程。适合想在本地处理敏感数据或对延迟有要求的场景,不过要注意磁盘和内存需求,手写体和糟糕图片还需要人工或后处理来补救。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...