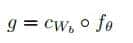1、11011101的二进制补码是多少?
先求
11011101
的
一的补码
,即将每一位取反,得到
00100010
,然后再加
1
,得到
00100011
。所以
11011101
的二进制补码是
00100011
。
2、完成以下表格中的进制转换,填充空白处:十进制、二进制、十六进制、二十一进制,已知十进制数23,二进制数010011,十六进制数ABB,二十一进制数2HE。
表格中各进制数转换如下:
| Base 10 | Base 2 | Base 16 | Base 21 |
|---|---|---|---|
| 23 | 10111 | 无 | 无 |
| 19 | 010011 | 无 | 无 |
| 2747 | 无 | ABB | 无 |
| 1253 | 无 | 无 | 2HE |
十进制 23 转换为二进制是 10111。
二进制 010011 转换为十进制是 19。
十六进制 ABB 转换为十进制是 2747。
二十一进制 2HE 转换为十进制是 1253(计算过程:2×21² + 17×21 + 14 = 882 + 357 + 14 = 1253)。
3、UTF – 8 常被称为 Unicode,为什么这是不正确的?
ISO/IEC 10646 定义了从码点(数字)到字形(字符)的映射,UTF-8 为 ISO/IEC 10646 标准中的码点(文本数据)定义了一种高效的可变长度编码,而 Unicode 为 ISO/IEC 10646 字符集添加了特定语言属性。
三者共同为几乎所有人类书面语言的文本数据提供支持,所以 UTF-8 只是其中一部分,不能简单等同于 Unicode。
4、熟练的汇编程序员可以在脑海中对二进制、十六进制和十进制的小数字进行相互转换。不参考任何表格、不使用计算器或纸笔,填写以下表格,将二进制、十进制、十六进制进行相互转换:
| 二进制 | 十进制 | 十六进制 |
|---|---|---|
| 5 | ||
| 1010 | ||
| C | ||
| 23 | ||
| 0101101 | ||
| 4B | ||
| 二进制 | 十进制 | 十六进制 |
| ——– | —— | ——– |
| 0101 | 5 | 5 |
| 1010 | 10 | A |
| 1100 | 12 | C |
| 00010111 | 23 | 17 |
| 0101101 | 45 | 2D |
| 01001011 | 75 | 4B |
5、汇编语言有四个主要元素。它们是什么?
汇编语言的四个主要元素是汇编指令、标签、汇编命令和注释。
6、展示三种不同的方法来创建一个包含短语“segmentation fault”的以空字符结尾的字符串。
方法一:使用
.asciz
指令,如:
str1: .asciz "segmentation fault"
方法二:使用
.string
指令,如:
str2: .string "segmentation fault"
方法三:可以先使用
.ascii
指令,再手动添加空字符,如:
str3: .ascii "segmentation fault",0
7、变量 var1、var2 和 expr 总共分配了多少字节的内存?其中 var1 为 .word 类型,值为 23;var2 为 .long 类型,值为 0xC;expr 为 .ascii 类型,值为 “>>”。
在大多数系统中,
.word
和
.long
通常都占用 4 个字节,
.ascii
字符串
">>"
包含 2 个字符,占用 2 个字节,所以总共分配 4 + 4 + 2 = 10 个字节。
8、识别以下代码中的指令、标签、注释和语句:
1 .global main
2 main:
3 mov r0,#1 @ the program return code is 1
4 mov pc,lr @ return and exit the program
## 指令
.global,mov
## 标签
main
## 注释
- @ the program return code is 1
- @ return and exit the program
## 语句
.global main
mov r0,#1
mov pc,lr
9、编写汇编代码来声明与以下 C 代码等效的变量,这些变量在任何函数外部声明:static int foo[3]; (在当前文件的任何地方可见) static char bar[4]; (在当前文件的任何地方可见) char barfoo; (在程序的任何地方可见) int foobar; (在程序的任何地方可见)
以下是等效的汇编代码:
.data
.global barfoo
.global foobar
foo:
.word 0, 0, 0
bar:
.byte 0, 0, 0, 0
barfoo:
.byte 0
foobar:
.word 0
10、在以下代码中插入最少数量的 .align 指令,使所有字变量按字边界对齐,所有半字变量按半字边界对齐,同时尽量减少空间浪费。代码如下:1 .data 2 .align 2 3 a: .byte 0 4 b: .word 32 5 c: .byte 3 6 d: .hword 45 7 e: .hword 0 8 f: .byte 0 9 g: .word 128
在第5行和第8行插入
.align
指令。修改后的代码如下:
1 .data
2 .align 2
3 a: .byte 0
4 b: .word 32
5 .align 2
6 c: .byte 3
7 d: .hword 45
8 .align 1
9 e: .hword 0
10 f: .byte 0
11 .align 2
12 g: .word 128
11、编写一个能打印你名字的程序。
以下是示例代码:
.data
str:
.asciz "你的名字
"
.text
.globl main
main:
stmfd sp!, {lr} @ 将返回地址压入栈
ldr r0, =str @ 加载指向格式字符串的指针
bl printf @ 调用printf函数
mov r0, #0 @ 将返回码移到r0
ldmfd sp!, {lr} @ 从栈中弹出返回地址
mov pc, lr @ 从main函数返回
将“你的名字”替换为实际名字,然后使用GNU C编译器编译生成可执行文件。
12、哪些寄存器分别保存栈指针、返回地址和程序计数器?
栈指针由r13(或sp)保存,返回地址由r14(或lr)保存,程序计数器由r15(或pc)保存。
13、stm 和 ldm 指令在地址寄存器后包含一个可选的 ‘!’,它有什么作用?
可选的 ‘!’ 指定在寄存器存储后应修改地址寄存器 Rd。
14、以下C语句声明了一个包含四个整数的数组,并按顺序将其值初始化为7、3、21和10。int nums[]={7,3,21,10}; (a) 写出等效的GNU ARM汇编代码。(b) 分别使用以下方法编写ARM汇编指令,将这四个数字分别加载到寄存器r3、r5、r6和r9中:i. 一条ldm指令;ii. 四条ldr指令。
(a) 在GNU ARM汇编中,等效代码如下:
```armasm
.data
nums: .word 7, 3, 21, 10
(b) i. 使用一条
ldm
指令:
LDR r0, =nums
LDMIA r0, {r3, r5, r6, r9}
ii. 使用四条
ldr
指令:
LDR r0, =nums
LDR r3, [r0]
LDR r5, [r0, #4]
LDR r6, [r0, #8]
LDR r9, [r0, #12]
15、使用ldm和stm编写一段简短的ARM汇编语言序列,将16个字的数据从源地址复制到目标地址。假设源地址已加载到r0中,目标地址已加载到r1中。你可以根据需要使用寄存器r2到r5来保存值。你的代码可以修改r0和/或r1。
可以使用以下汇编代码实现:
ldmia r0, {r2 - r5, r6 - r9, r10 - r13, r14}
stmia r1, {r2 - r5, r6 - r9, r10 - r13, r14}
解释:
第一条指令使用
ldmia
(Load Multiple Increment After)从
r0
指向的源地址加载16个字的数据到寄存器
r2 - r14
中,每次加载后地址自动递增4字节。
第二条指令使用
stmia
(Store Multiple Increment After)将寄存器
r2 - r14
中的数据存储到
r1
指向的目标地址,每次存储后地址自动递增4字节。
16、如果r0初始值为1,在执行以下指令序列的第三条指令后,r0的值是多少? 1 add r0,r0,#1 2 mov r1,r0 3 add r0,r1,r0 lsl #1
6
17、执行以下每条指令后,r0 和 r1 分别包含什么值?以十进制给出答案。1 mov r0,#1 2 mov r1,#0x20 3 orr r1,r1,r0 4 lsl r1,#0x2 5 orr r1,r1,r0 6 eor r0,r0,r1 7 lsr r1,r0,#3
执行
mov r0,#1
后,
r0 = 1
,
r1
未操作;
执行
mov r1,#0x20
后,
r0 = 1
,
r1 = 32
;
执行
orr r1,r1,r0
后,
r0 = 1
,
r1 = 33
;
执行
lsl r1,#0x2
后,
r0 = 1
,
r1 = 132
;
执行
orr r1,r1,r0
后,
r0 = 1
,
r1 = 133
;
执行
eor r0,r0,r1
后,
r0 = 132
,
r1 = 133
;
执行
lsr r1,r0,#3
后,
r0 = 132
,
r1 = 16
;
18、lsr和asr有什么区别?
以下是调整为 Markdown 格式的文本内容:
`lsr` 操作将每个位向右移动指定的位数 `n`,`n` 个最高有效位补零,最低有效 `n` 位丢失;
`asr` 操作也将每个位向右移动指定的位数 `n`,但 `n` 个最高有效位变为符号位(第31位)的副本,最低有效 `n` 位丢失。
19、给定以下变量定义:num1:.word x ,num2:.word y,其中不知道x和y的值。编写一段简短的ARM汇编指令序列,用于加载这两个数字,比较它们,并将较大的数字移动到寄存器r0中。
以下是实现该功能的ARM汇编代码:
LDR r1, =num1 ; 将num1的地址加载到r1
LDR r2, [r1] ; 从num1地址处加载值到r2
LDR r1, =num2 ; 将num2的地址加载到r1
LDR r3, [r1] ; 从num2地址处加载值到r3
CMP r2, r3 ; 比较r2和r3的值
MOVGT r0, r2 ; 如果r2 > r3,将r2的值移动到r0
MOVLE r0, r3 ; 如果r2 <= r3,将r3的值移动到r0
20、假设a存储在寄存器r0中,b存储在寄存器r1中,请给出与以下C代码等效的ARM汇编代码。if ( a & 1 ) a = -a; else b = b+7;
以下是等效的ARM汇编代码:
tst r0, #1 @ 比较a的第0位与1
rsbne r0, r0, #0 @ 如果第0位被设置,将a取负
addeq r1, r1, #7 @ 否则将b加7
21、寄存器为易失性(volatile)是什么意思?根据ARM函数调用约定,哪些ARM寄存器被认为是易失性的?
寄存器为易失性意味着这些寄存器可以自由使用,子程序调用时无需保存其内容。
根据ARM函数调用约定,寄存器 r0 – r3 和 r12 是易失性的;在 VFP 相关内容中,寄存器 s0 – s15(也称为 d0 – d7)以及若存在的 d16 – d31 是易失性的。
22、用ARM汇编语言编写一个与以下C函数等价的函数:
int max(int a, int b) {
if (a > b) {
return a;
}
return b;
}
以下是实现该功能的ARM汇编代码:
max:
CMP r0, r1 ; 比较a (r0) 和 b (r1)
MOVGT r0, r0 ; 如果 a > b,将a (r0) 作为返回值
MOVLE r0, r1 ; 如果 a <= b,将b (r1) 作为返回值
BX lr ; 返回
在上述代码中,
CMP
指令用于比较
r0
和
r1
的值,
MOVGT
指令在
a > b
时将
r0
的值作为返回值,
MOVLE
指令在
a <= b
时将
r1
的值作为返回值,最后
BX lr
指令用于返回调用函数。
23、自动变量可以存储在哪两个地方?
栈:临时调整栈以存放变量;2. 寄存器:变量在其整个生命周期内都存于寄存器中。
24、你要编写一个函数,决定在函数内使用寄存器 r4 和 r5。该函数不会调用其他函数,是自包含的。修改以下框架结构,确保 r4 和 r5 能在函数内使用,且恢复到符合 ARM 标准的状态,同时避免不必要的内存访问。
1 myfunc: stmfd sp!,{lr}
2…
3 @ 函数语句
4…
5 ldmfd sp!,{lr}
1 myfunc: stmfd sp!,{r4, r5, lr}
2...
3 @ 函数语句
4...
5 ldmfd sp!,{r4, r5, lr}
25、编写一个完整的 ARM 汇编函数,使其等同于以下 C 函数。注意,a 和 b 必须分配在栈上,并且它们的地址必须传递给 scanf 函数,以便 scanf 可以将它们的值存入内存。C 函数如下:
int read_and_add() {
int a, b, sum;
scanf("%d", &a);
scanf("%d", &b);
sum = a + b;
return sum;
}
以下是对应的 ARM 汇编代码:
.data
fmt: .asciz "%d"
.text
.global read_and_add
read_and_add:
stmfd sp!,{lr}
sub sp, sp, #12 @ 为 a, b, sum 分配栈空间
ldr r0, =fmt @ 加载格式字符串地址
add r1, sp, #8 @ 获取 a 的地址
bl scanf @ 调用 scanf 读取 a
ldr r0, =fmt @ 加载格式字符串地址
add r1, sp, #4 @ 获取 b 的地址
bl scanf @ 调用 scanf 读取 b
ldr r2, [sp, #8] @ 加载 a 的值
ldr r3, [sp, #4] @ 加载 b 的值
add r1, r2, r3 @ 计算 sum = a + b
str r1, [sp] @ 保存 sum 到栈
ldr r0, [sp] @ 加载返回值到 r0
add sp, sp, #12 @ 释放栈空间
ldmfd sp!,{lr} @ 恢复链接寄存器
mov pc, lr @ 返回
26、使用抽象数据类型设计软件有哪些优点?
抽象数据类型是结构化编程概念,有助于提高软件可靠性、便于维护,并能以安全的方式进行重大修改。它支持信息隐藏,将信息封装到模块中,通过接口呈现,隐藏实现细节,减少软件开发风险,使代码依赖从不确定的实现转移到定义良好的接口上,若实现改变,客户端代码无需改变。此外,它还便于用多种语言实现软件模块,只要代码符合标准,就能与其他语言编写的代码链接。
27、为什么Pixel数据类型的内部结构要对客户端代码隐藏?
为了提供数据结构保护,使客户端代码只能通过提供的接口访问数据结构。只有
pval
定义被暴露,向客户端程序表明像素的红、绿、蓝分量必须是 0 到 255 之间的数字。在 C 语言等结构化编程语言中,子例程的实现也可通过放在单独的编译模块中进行隐藏,这些模块可访问 Image 数据类型的内部结构。
28、高级语言提供了信息隐藏机制,但汇编语言没有。为什么汇编程序员不直接绕过所有信息隐藏,直接访问任何抽象数据类型(ADT)的内部数据结构呢?
编码实践与设计的重要性
因为不良的编码实践和设计会导致严重后果,包括生命损失。程序员有责任在软件设计和实现中做出符合道德的决策,要考虑决策可能带来的后果。
此外,使用抽象数据类型有助于确保软件的安全性、可靠性和可维护性,也便于用多种语言实现软件模块。因此,汇编程序员不应绕过信息隐藏直接访问内部数据结构。
29、解释Therac 25开发者是如何违反《软件工程伦理与专业实践准则》的。
Therac 25 开发者违反准则体现如下:
代码未经过独立审查
不符合确保充分测试、调试和审查软件的要求。
软件设计未考虑故障情况
在评估机器故障或失灵情况时未考虑软件设计,开发者没有基于充分依据认为软件安全、符合规格并通过适当测试。
硬件和软件分开设计
直到在医院组装才作为完整系统测试,未进行充分测试。
硬件联锁改为软件联锁
早期机器的硬件联锁被改为软件联锁,增加风险且未充分测试。
错误以数字代码显示
无严重程度指示,不利于调试和维护,未以专业态度对待软件维护。
30、当问题被报告时,加拿大原子能有限公司(AECL)的工程师和经理应该如何回应?
软件工程道德规范要求
依据软件工程道德规范,工程师和经理应在以下方面履行职责:
软件批准
在有充分依据认为软件
安全、符合规格且通过适当测试
时才批准软件。
确保对所负责软件进行
充分测试、调试和审查
。
对软件维护与新开发
一视同仁
。
问题报告处理
当问题报告出现时,应
立即展开全面且专业的调查
。
不轻易假设问题原因,对
所有可能的故障进行排查
。
仔细分析问题
,不主观否定机器存在故障。
与专业机构合作调查
,如:
独立工程公司
医院医疗物理学家等
向监管机构报告
及时准确地向监管机构报告问题
。
积极配合监管机构的要求
。
制定纠正措施
制定
有效的纠正措施计划
,涵盖:
软件和硬件的改进
例如:对软件进行全面审查和修改、增加机械安全联锁装置等
后续验证与通报
对改进后的机器进行
充分测试
,确保问题得到解决。
向所有使用该机器的场所
通报问题及解决进展
。
提供
详细的故障信息和安全建议
。
31、还有哪些道德和非道德方面的考虑因素可能导致了人员伤亡?
道德方面
开发者未遵循软件工程道德规范
未确保软件安全、进行充分测试和审查
对软件维护缺乏专业态度
未对问题及时有效处理
未对代码进行独立审查
非道德方面
硬件和软件分开设计且未作为完整系统测试
早期机器的硬件联锁改为软件联锁
错误以数字代码显示,无严重程度指示
操作员可忽略故障继续治疗
软件设计未在评估机器故障或失灵时被考虑
32、使用有符号8位二进制乘法将 -90 乘以 105,得到一个有符号16位结果。请展示所有计算步骤。
首先,将 -90 和 105 转换为8位二进制数。
105 的二进制表示为:
01101001
-90 的原码为:
11011010
-90 的反码为:
10100101
-90 的补码为:
10100110
接下来进行无符号乘法:
10100110 × 01101001
,按照二进制乘法规则计算:
10100110
× 01101001
——————————————
10100110 (10100110 × 1)
00000000 (10100110 × 0,右移一位)
10100110 (10100110 × 1,右移二位)
00000000 (10100110 × 0,右移三位)
10100110 (10100110 × 1,右移四位)
10100110 (10100110 × 1,右移五位)
00000000 (10100110 × 0,右移六位)
01010011 (10100110 × 0,右移七位)
——————————————
1110001011011010
因为乘数 -90 为负,而被乘数 105 为正,根据规则需要对结果取补码。
原码:
1110001011011010
反码:
1001110100100101
补码:
1001110100100110
所以,-90 乘以 105 的有符号16位二进制结果是:
1001110100100110
33、展示将寄存器 r0 中的数字乘以常量 6710 所需的最优高效指令。
首先将 6710 转换为二进制:6710 = 1101000000110₂。可以将乘法转换为一系列的移位和加法操作操作。以下是实现将寄存器
r0
中的数字乘以 6710 的指令序列:
lsl r1, r0, #1
; r1 = r0 << 1(r1 = 2 * r0)
lsl r2, r0, #2
; r2 = r0 << 2(r2 = 4 * r0)
add r3, r1, r2
; r3 = r1 + r2(r3 = 2 * r0 + 4 * r0 = 6 * r0)
lsl r4, r3, #8
; r4 = r3 << 8(r4 = 6 * r0 * 256 = 1536 * r0)
lsl r5, r0, #1
; r5 = r0 << 1(r5 = 2 * r0)
lsl r6, r0, #0
; r6 = r0 << 0(r6 = r0)
add r7, r5, r6
; r7 = r5 + r6(r7 = 2 * r0 + r0 = 3 * r0)
add r8, r4, r7
; r8 = r4 + r7(r8 = 1536 * r0 + 3 * r0 = 6710 * r0)
最终结果存于
r8
寄存器中。
34、当除以一个常量值时,为什么希望 m 尽可能大?
为了达到最佳精度,在可用的位数下,希望 m 尽可能大。
35、进行以下进制转换:(a) 将二进制数10110.001₂转换为十进制。(b) 将二进制数11000.0101₂转换为十进制。(c) 将十进制数10.125₁₀转换为二进制。
(a)
10110.001₂
=
1×2⁴ + 0×2³ + 1×2² + 1×2¹ + 0×2⁰ + 0×2⁻¹ + 0×2⁻² + 1×2⁻³
=
16 + 4 + 2 + 0.125
=
22.125₁₀
(b)
11000.0101₂
=
1×2⁴ + 1×2³ + 0×2² + 0×2¹ + 0×2⁰ + 0×2⁻¹ + 1×2⁻² + 0×2⁻³ + 1×2⁻⁴
=
16 + 8 + 0.25 + 0.0625
=
24.3125₁₀
(c)
整数部分
10 ÷ 2 = 5 余 0
5 ÷ 2 = 2 余 1
2 ÷ 2 = 1 余 0
1 ÷ 2 = 0 余 1
从下往上取余数为:
1010
小数部分
0.125 × 2 = 0.25 取整数部分 0
0.25 × 2 = 0.5 取整数部分 0
0.5 × 2 = 1 取整数部分 1
所以小数部分为:
001
因此:
10.125₁₀ = 1010.001₂
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...