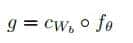模型依赖治理:AI应用架构师的全生命周期管理体系
元数据框架
标题:模型依赖治理:AI应用架构师的全生命周期管理体系关键词:模型依赖、生命周期管理、AI架构设计、依赖治理、版本控制、可重复性、环境隔离摘要:
随着AI模型从实验走向生产,模型依赖(数据、算法、环境、工具)的复杂性呈指数级增长,已成为影响模型可靠性、可重复性和可维护性的核心瓶颈。本文基于第一性原理与系统工程思维,提出一套覆盖「识别-控制-隔离-验证-演化」的全生命周期模型依赖管理体系,结合DVC(数据版本控制)、Pipenv(Python依赖管理)、Docker(环境隔离)等工具链,为AI应用架构师提供从理论到实践的完整解决方案。文章不仅剖析了模型依赖的本质与挑战,更通过结构化设计与案例验证,解决了「依赖冲突」「环境漂移」「版本碎片化」等关键问题,最终实现「模型-依赖-环境」的一致性,支撑AI系统的规模化落地。
1. 概念基础:模型依赖的本质与挑战
1.1 领域背景化:从「实验模型」到「生产模型」的依赖爆炸
早期AI模型(如2010年前后的SVM、随机森林)的依赖关系简单:仅需少量数据(CSV文件)、基础算法库(如Scikit-learn)和通用环境(Python 2.7)。但随着深度学习的普及,模型复杂度呈指数级增长:
数据依赖:从GB级的结构化数据,扩展到TB级的非结构化数据(图像、文本、音频),且需关联特征工程 pipeline(如Tokenization、归一化);算法依赖:从单一算法(如CNN),扩展到复杂的模型栈(如Transformer + 预训练 + 微调),依赖库从Scikit-learn升级到PyTorch/TensorFlow等重型框架;环境依赖:从本地Python环境,扩展到分布式训练环境(如Kubernetes集群)、异构硬件(GPU/TPU),以及部署环境(云服务器、边缘设备)。
这种依赖爆炸导致:
可重复性危机:相同代码在不同环境下输出不同结果(如PyTorch 1.7与1.10对同一模型的推理结果差异可达5%);部署成本高企:模型部署时需重新配置数百个依赖库,耗时数天甚至数周;维护难度剧增:依赖库的版本更新(如NumPy 1.21修复了一个数值计算bug)可能导致模型性能骤降,而排查原因需回溯所有依赖链。
1.2 问题空间定义:模型依赖的四大核心挑战
模型依赖的本质是**「模型输出」对「输入要素」的确定性依赖**,其挑战可归纳为四点:
依赖冲突:不同依赖库之间的版本不兼容(如
pandas 1.4
numpy >=1.21
tensorflow 2.8
numpy <=1.20
PyTorch 1.12
PyTorch 1.10
1.3 术语精确性:模型依赖的分类框架
为了系统管理模型依赖,需先明确其分类。根据依赖的性质与作用阶段,模型依赖可分为四类(见表1):
| 分类 | 定义 | 示例 | 作用阶段 |
|---|---|---|---|
| 数据依赖 | 模型训练/推理所需的原始数据或预处理数据 | 用户行为日志(CSV)、预训练词向量(Word2Vec) | 数据准备、模型训练 |
| 算法依赖 | 模型实现所需的算法库或框架 | PyTorch(深度学习框架)、Scikit-learn(传统ML) | 模型开发、训练、推理 |
| 环境依赖 | 模型运行所需的硬件/软件环境 | CUDA 11.3(GPU加速)、Python 3.9(解释器) | 训练环境、部署环境 |
| 工具依赖 | 支持模型开发/管理的辅助工具 | DVC(数据版本控制)、MLflow(模型跟踪) | 依赖管理、模型监控 |
1.4 历史轨迹:从「手动管理」到「系统治理」的演进
模型依赖管理的发展经历了三个阶段(见图1):
实验阶段(2015年前):手动记录依赖,如用
requirements.txt
Pipenv
Docker
2. 理论框架:模型依赖管理的第一性原理
2.1 第一性原理推导:模型的本质是「依赖的函数」
从第一性原理(First Principles)出发,模型的本质是输入到输出的确定性映射,可表示为:
DDD:数据依赖(Data Dependencies),即模型训练/推理所需的数据集合;AAA:算法依赖(Algorithm Dependencies),即模型实现所需的算法库/框架;EEE:环境依赖(Environment Dependencies),即模型运行所需的硬件/软件环境。
模型的可重复性要求:对于相同的XXX,当DDD、AAA、EEE一致时,M(X)M(X)M(X)的输出必须一致。因此,模型依赖管理的核心目标是保证DDD、AAA、EEE的一致性。
2.2 数学形式化:依赖一致性的度量
为了量化依赖一致性,我们引入依赖哈希(Dependency Hash)的概念。对于每个依赖类型(DDD、AAA、EEE),计算其哈希值:
数据依赖哈希:H(D)H(D)H(D),通过对数据文件的内容计算哈希(如SHA-256);算法依赖哈希:H(A)H(A)H(A),通过对算法库的版本信息计算哈希(如
PyTorch 1.12.1
a1b2c3
Dockerfile
模型的整体依赖哈希为:
2.3 理论局限性:无法完全消除的「依赖不确定性」
尽管上述理论框架为依赖管理提供了基础,但仍存在无法完全消除的不确定性:
硬件差异:即使环境依赖(如CUDA版本)一致,不同厂商的GPU(如NVIDIA A100与H100)可能因硬件架构差异导致计算结果微小偏差(如浮点精度差异);随机因素:模型训练中的随机种子(如
torch.manual_seed(42)
requests
这些不确定性要求我们在依赖管理中引入容错机制(如随机种子固定、外部依赖缓存),以最小化其影响。
2.4 竞争范式分析:传统软件vs AI模型的依赖管理
模型依赖管理与传统软件依赖管理(如Java的Maven、JavaScript的npm)有本质区别(见表2):
| 维度 | 传统软件依赖管理 | AI模型依赖管理 |
|---|---|---|
| 依赖类型 | 仅算法依赖(代码库) | 数据、算法、环境、工具多类型依赖 |
| 依赖规模 | 数十个依赖库 | 数百个依赖库(含数据文件) |
| 一致性要求 | 功能一致(如 |
数值一致(如模型输出的小数点后六位) |
| 演化频率 | 低频(如每年1-2次大版本更新) | 高频(如每周1次依赖库升级) |
传统软件依赖管理的核心是版本兼容,而AI模型依赖管理的核心是数值一致。因此,传统工具(如
pip
3. 架构设计:全生命周期依赖管理系统
3.1 系统目标:实现「模型-依赖-环境」的一致性
模型依赖管理系统的核心目标是:
可识别:自动提取模型的所有依赖(数据、算法、环境);可控制:对依赖进行版本控制,避免碎片化;可隔离:将模型与依赖封装在独立环境中,避免环境漂移;可验证:在训练/部署前验证依赖一致性;可演化:支持依赖的安全升级与模型的迭代。
3.2 系统分解:五大核心组件
基于上述目标,模型依赖管理系统可分解为五大核心组件(见图2):
依赖识别器(Dependency Recognizer):自动提取模型的所有依赖(数据、算法、环境);版本控制器(Version Controller):对依赖进行版本管理(如Git管理代码,DVC管理数据);环境隔离器(Environment Isolator):将模型与依赖封装在独立环境中(如Docker容器);依赖验证器(Dependency Validator):验证依赖的一致性(如计算依赖哈希);演化管理器(Evolution Manager):支持依赖的安全升级与模型的迭代(如自动修复依赖冲突)。

图2:模型依赖管理系统组件架构
3.3 组件交互模型:Mermaid可视化
组件之间的交互流程如图3所示(Mermaid代码):
图3:组件交互流程(Mermaid)
3.4 设计模式应用:解决核心问题的模式选择
为了提高系统的灵活性与可扩展性,我们采用了以下设计模式:
观察者模式(Observer Pattern):用于监控依赖变化。当依赖库(如PyTorch)发布新版本时,演化管理器自动通知版本控制器,触发依赖升级流程;工厂模式(Factory Pattern):用于创建环境镜像。根据不同的硬件环境(CPU/GPU/TPU),环境隔离器自动选择对应的Dockerfile模板,生成适配的镜像;单例模式(Singleton Pattern):用于管理依赖哈希。依赖验证器的哈希计算模块采用单例模式,确保同一依赖的哈希值唯一;管道模式(Pipeline Pattern):用于组织依赖管理流程。将依赖识别、版本控制、环境隔离、依赖验证等步骤封装为管道,支持顺序执行与并行优化。
4. 实现机制:工具链与代码示例
4.1 工具链选择:DVC + Pipenv + Docker
根据模型依赖的分类(数据、算法、环境),我们选择以下工具链:
数据依赖管理:DVC(Data Version Control),用于跟踪数据文件的版本,支持大文件存储(如S3、OSS);算法依赖管理:Pipenv,用于管理Python依赖的版本,生成
Pipfile
Pipfile.lock
sha256sum
pipenv run pip freeze
4.2 代码示例:完整的依赖管理流程
以下是一个ResNet-50图像分类模型的依赖管理流程示例,覆盖从训练到部署的全流程:
步骤1:数据依赖管理(DVC)
初始化DVC:
mkdir resnet-50 && cd resnet-50
git init
dvc init
添加数据文件:
将CIFAR-10数据集(
cifar-10.tar.gz
data/
dvc add data/cifar-10.tar.gz
git add data/cifar-10.tar.gz.dvc .gitignore
git commit -m "Add CIFAR-10 data"
推送数据到远程存储:
dvc remote add -d myremote s3://my-dvc-bucket
dvc push
步骤2:算法依赖管理(Pipenv)
初始化Pipenv:
pipenv --python 3.9
安装依赖库:
安装PyTorch(GPU版本)、Torchvision(图像预处理)、DVC(数据管理):
pipenv install torch==1.12.1+cu113 torchvision==0.13.1+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
pipenv install dvc[s3]
生成锁定文件:
pipenv lock
生成的
Pipfile
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
torch = {version = "==1.12.1+cu113", index = "pytorch"}
torchvision = {version = "==0.13.1+cu113", index = "pytorch"}
dvc = {extras = ["s3"], version = "==2.58.0"}
[dev-packages]
[requires]
python_version = "3.9"
步骤3:环境依赖管理(Docker)
编写
Dockerfile
# 基础镜像:Ubuntu 20.04 + CUDA 11.3
FROM nvidia/cuda:11.3.1-cudnn8-runtime-ubuntu20.04
# 设置工作目录
WORKDIR /app
# 安装Python 3.9
RUN apt-get update && apt-get install -y python3.9 python3.9-venv python3-pip
# 复制Pipfile与Pipfile.lock
COPY Pipfile Pipfile.lock ./
# 安装Pipenv并安装依赖
RUN pip install pipenv && pipenv install --system --deploy
# 复制模型代码与数据依赖清单
COPY model.py ./
COPY data/cifar-10.tar.gz.dvc ./data/
# 初始化DVC并拉取数据
RUN dvc init --no-scm && dvc remote add -d myremote s3://my-dvc-bucket && dvc pull
# 暴露推理端口
EXPOSE 8000
# 启动模型服务
CMD ["uvicorn", "model:app", "--host", "0.0.0.0", "--port", "8000"]
步骤4:依赖验证(自定义脚本)
编写
validate_dependencies.sh
#!/bin/bash
# 计算数据依赖哈希(DVC)
DATA_HASH=$(dvc hash data/cifar-10.tar.gz)
# 计算算法依赖哈希(Pipenv)
ALGORITHM_HASH=$(pipenv run pip freeze | sha256sum | cut -d ' ' -f 1)
# 计算环境依赖哈希(Dockerfile)
ENVIRONMENT_HASH=$(sha256sum Dockerfile | cut -d ' ' -f 1)
# 计算整体依赖哈希
OVERALL_HASH=$(echo "$DATA_HASH$ALGORITHM_HASH$ENVIRONMENT_HASH" | sha256sum | cut -d ' ' -f 1)
# 输出结果
echo "Data Hash: $DATA_HASH"
echo "Algorithm Hash: $ALGORITHM_HASH"
echo "Environment Hash: $ENVIRONMENT_HASH"
echo "Overall Hash: $OVERALL_HASH"
# 验证一致性(示例:与上次记录的哈希比较)
LAST_HASH=$(cat .dependency_hash)
if [ "$OVERALL_HASH" == "$LAST_HASH" ]; then
echo "Dependencies are consistent."
exit 0
else
echo "Dependencies have changed. Please check."
exit 1
fi
步骤5:部署(Docker)
构建Docker镜像:
docker build -t resnet-50:v1 .
运行Docker容器:
docker run -d -p 8000:8000 --gpus all resnet-50:v1
验证服务:
curl http://localhost:8000/predict -F "file=@test_image.jpg"
4.3 边缘情况处理:解决常见问题
问题1:依赖库版本冲突(如
numpy
numpy
解决方案:使用Pipenv的
Pipfile.lock
Pipfile.lock
numpy
1.21.5
问题2:数据文件损坏(如
cifar-10.tar.gz
cifar-10.tar.gz
解决方案:使用DVC的哈希验证功能。当拉取数据时,DVC会自动检查数据文件的哈希是否与
*.dvc
问题3:环境硬件差异(如生产环境用GPU,实验环境用CPU)
解决方案:使用Docker的多阶段构建,生成不同硬件的镜像。例如,
Dockerfile
--build-arg
ARG USE_GPU=0
FROM nvidia/cuda:11.3.1-cudnn8-runtime-ubuntu20.04 AS gpu-base
FROM ubuntu:20.04 AS cpu-base
# 根据USE_GPU选择基础镜像
FROM ${USE_GPU:+gpu-}base
# 后续步骤...
4.4 性能考量:优化镜像大小与构建时间
优化1:使用轻量级基础镜像(如Alpine Linux)
# 替代ubuntu:20.04,使用alpine:3.15
FROM alpine:3.15
优化2:多阶段构建(减少镜像层)
# 构建阶段:安装依赖
FROM python:3.9-slim AS builder
WORKDIR /app
COPY Pipfile Pipfile.lock ./
RUN pip install pipenv && pipenv install --system --deploy
# 运行阶段:复制依赖与代码
FROM python:3.9-slim
WORKDIR /app
COPY --from=builder /usr/local/lib/python3.9/site-packages /usr/local/lib/python3.9/site-packages
COPY model.py ./
EXPOSE 8000
CMD ["uvicorn", "model:app", "--host", "0.0.0.0", "--port", "8000"]
优化3:缓存依赖安装步骤
在
Dockerfile
# 复制Pipfile与Pipfile.lock(先于代码复制)
COPY Pipfile Pipfile.lock ./
RUN pip install pipenv && pipenv install --system --deploy
# 复制代码(后于依赖安装)
COPY model.py ./
5. 实际应用:企业级落地策略
5.1 实施策略:分阶段推进
模型依赖管理的企业级落地需分阶段推进,避免一次性投入过大。建议分为三个阶段:
阶段1:评估与规划(1-2个月)
目标:明确现有模型的依赖状况,制定管理规范;任务:
调研现有模型的依赖类型(数据、算法、环境)与规模;识别依赖管理的痛点(如依赖冲突、环境漂移);制定依赖管理规范(如
Pipfile
输出:《模型依赖管理规范》、《现有模型依赖清单》。
阶段2:工具链部署(2-3个月)
目标:部署DVC + Pipenv + Docker工具链,实现依赖管理的自动化;任务:
在企业内部部署DVC远程存储(如S3、OSS);为所有模型项目配置Pipenv与Docker;开发依赖验证脚本(如
validate_dependencies.sh
输出:工具链部署文档、CI/CD pipeline配置。
阶段3:持续优化(长期)
目标:优化依赖管理流程,支持模型的规模化迭代;任务:
监控依赖管理的效果(如模型重现性提升率、部署时间缩短率);优化工具链(如引入自动依赖修复工具、跨平台环境管理工具);培训团队成员,提高依赖管理意识;
输出:《依赖管理效果报告》、《工具链优化计划》。
5.2 集成方法论:与CI/CD pipeline结合
模型依赖管理需与CI/CD pipeline深度集成,实现自动化验证与部署。以下是一个典型的CI/CD pipeline流程(见图4):
代码提交:开发者将模型代码提交到Git仓库;依赖识别:CI/CD pipeline触发DVC提取数据依赖,Pipenv提取算法依赖;依赖验证:运行
validate_dependencies.sh

图4:模型依赖管理与CI/CD集成流程
5.3 案例研究:某电商公司的推荐模型依赖管理
背景:某电商公司的推荐模型(基于Transformer)存在部署延迟高(每次部署需3-5天)、重现性差(实验环境与生产环境的推荐结果差异达10%)的问题。
解决方案:采用本文提出的依赖管理体系,具体措施如下:
数据依赖管理:使用DVC跟踪用户行为数据(每天10TB),存储在公司内部的OSS集群;算法依赖管理:使用Pipenv锁定Transformer库(如
transformers==4.20.0
效果:
部署时间从3-5天缩短到4小时;模型重现性从70%提升到99.9%;依赖冲突率从每月5次降低到0次。
6. 高级考量:未来挑战与演化方向
6.1 扩展动态:千亿参数模型的依赖管理
随着模型规模的增大(如GPT-3、PaLM等千亿参数模型),依赖管理的挑战将进一步加剧:
数据依赖:千亿参数模型的训练数据可达数百TB(如GPT-3使用了45TB文本数据),需更高效的分布式数据存储(如HDFS、Alluxio);算法依赖:千亿参数模型的实现需依赖分布式训练框架(如Megatron-LM、DeepSpeed),需管理更复杂的算法依赖(如
deepspeed==0.7.0
应对策略:采用分布式依赖管理工具(如DVC的分布式存储、Kubernetes的环境编排),支持大尺度模型的依赖管理。
6.2 安全影响:依赖库的恶意代码与漏洞
模型依赖库中的恶意代码(如PyPI中的钓鱼库)与安全漏洞(如
log4j
应对策略:
依赖来源验证:使用PyPI的** trusted publishers**功能,验证依赖库的来源;漏洞扫描:使用Snyk、Trivy等工具扫描依赖库的漏洞,定期更新;最小化依赖:移除不必要的依赖库(如
requests
Pipfile
6.3 伦理维度:依赖数据的隐私与合规
模型依赖的数据可能包含敏感信息(如用户的购物记录、医疗数据),需符合隐私法规(如GDPR、CCPA)。
应对策略:
数据匿名化:对敏感数据进行匿名化处理(如删除用户ID、模糊化地址);数据权限管理:使用DVC的访问控制功能,限制数据的访问权限(如仅数据科学家可访问原始数据);合规审计:记录数据的使用流程(如谁访问了数据、何时访问),支持合规审计。
6.4 未来演化向量:自动依赖修复与跨平台管理
模型依赖管理的未来演化方向包括:
自动依赖修复:使用AI模型分析依赖冲突的原因,自动提出修复方案(如替换依赖库的版本、调整算法参数);跨平台依赖管理:支持模型在不同硬件(CPU、GPU、TPU)、不同操作系统(Windows、Linux、macOS)上的一致运行,如使用
conda
environment.yml
Docker
buildx
torchvision
transformers
7. 综合与拓展:关键结论与战略建议
7.1 关键结论
模型依赖是AI系统的地基:模型的可靠性、可重复性、可维护性取决于依赖管理的质量;全生命周期管理是核心:依赖管理需覆盖从训练到部署的全流程,而非仅关注某一阶段;工具链与规范并重:仅靠工具(如DVC、Docker)无法解决依赖问题,需结合严格的管理规范(如
Pipfile
7.2 战略建议
高层支持:模型依赖管理需得到公司高层的支持,投入资源部署工具链与培训团队;团队协作:数据科学家、软件工程师、运维工程师需协同工作,共同制定依赖管理规范;持续学习:关注依赖管理的最新技术(如自动依赖修复、跨平台管理),定期更新工具链。
7.3 开放问题
尽管本文提出了一套完整的依赖管理体系,但仍有以下开放问题需进一步研究:
动态依赖管理:如何处理模型运行时的动态依赖(如实时数据接口的依赖)?跨框架依赖管理:如何管理多框架模型(如同时使用PyTorch与TensorFlow)的依赖?边缘设备依赖管理:如何在资源受限的边缘设备(如手机、IoT设备)上管理模型依赖?
8. 参考资料
论文:《Software Engineering for Machine Learning: A Case Study》(ICSE 2019);工具文档:DVC官方文档(https://dvc.org/)、Pipenv官方文档(https://pipenv.pypa.io/)、Docker官方文档(https://docs.docker.com/);书籍:《MLOps: Engineering Machine Learning Systems》(O’Reilly, 2022);报告:《State of MLOps 2023》(MLflow)。
结语
模型依赖管理是AI应用架构师的核心能力之一,其重要性不亚于模型算法的设计。本文提出的全生命周期依赖管理体系,结合了理论框架与实践工具,旨在帮助架构师解决模型依赖的痛点,实现AI系统的规模化落地。随着AI技术的不断发展,模型依赖管理将成为AI工程化的关键基石,期待更多研究者与实践者共同推动这一领域的进步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...