selenium支持后台多平台多页面操作
selenium下载安装
1.先安装python环境和pytorch软件

在已有谷歌浏览器的情况下下载谷歌浏览器驱动(最好跟自己版本号对应,除非真的没有)
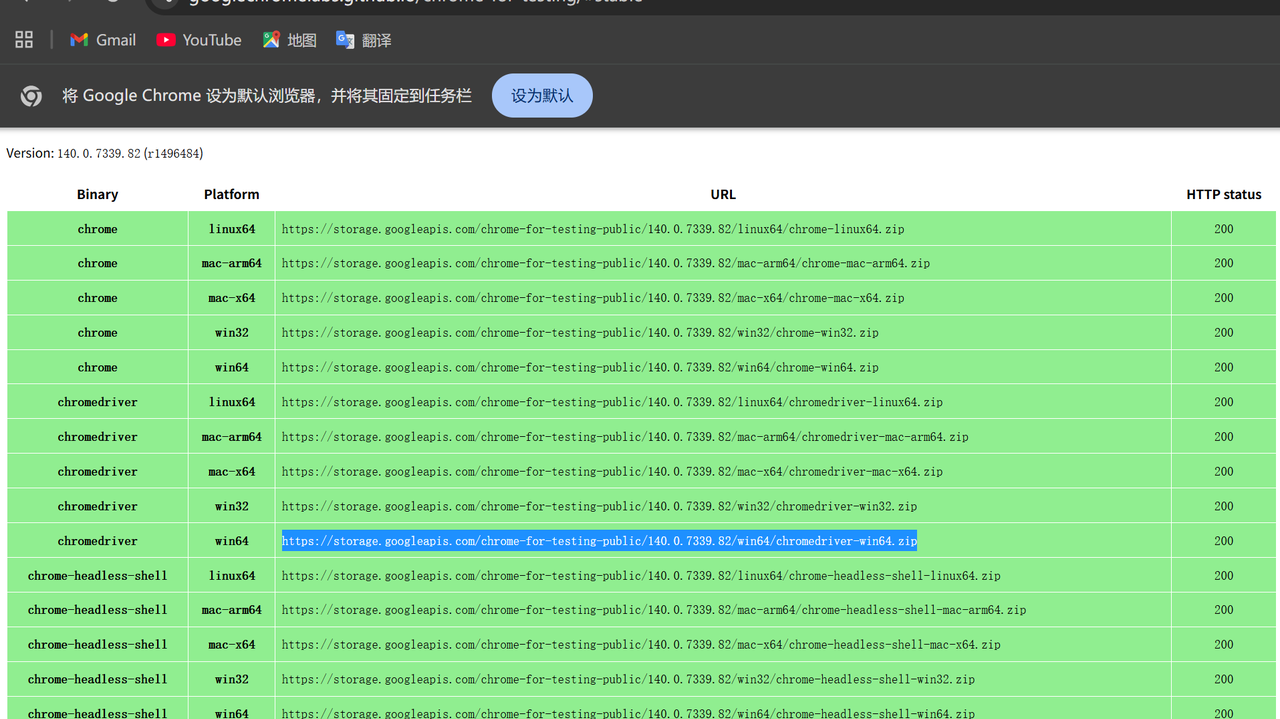

在服务中把谷歌相关的全部禁用,这样就不会自动更新,就不会导致下载的驱动后续无法使用的问题
浏览器开启

#保持浏览器打开状态(默认是代码执行完毕自动关闭)
browser1.add_experimental_option('detach', True)如果不添加该段代码,则运行打开浏览器命令后会闪一下又马上关闭窗口
如果不写禁用沙盒模式,可能会出现兼容问题导致报错、闪退等情况
用函数封装打开浏览器的执行代码
def keepOpen():
#创建设置浏览器对象
browser1 =Options()
#对创建的浏览器对象进行实质设置
#禁用沙盒模式
browser1.add_argument('--no-sandbox')
#保持浏览器打开状态(默认是代码执行完毕自动关闭)
browser1.add_experimental_option('detach', True)
#创建并启动浏览器
broOpen = webdriver.Chrome(service=Service('chromedriver.exe'), options=browser1)
return broOpen
browser = keepOpen() #从方法中返回一个启动的浏览器
#浏览器对象.get :打开指定网址
browser.get('https://www.baidu.com/') #括号中传字符串注意:字符串中的网址必须带上http/https协议,因为有的未必做了一个默认选项
打开的网页我们叫做标签页
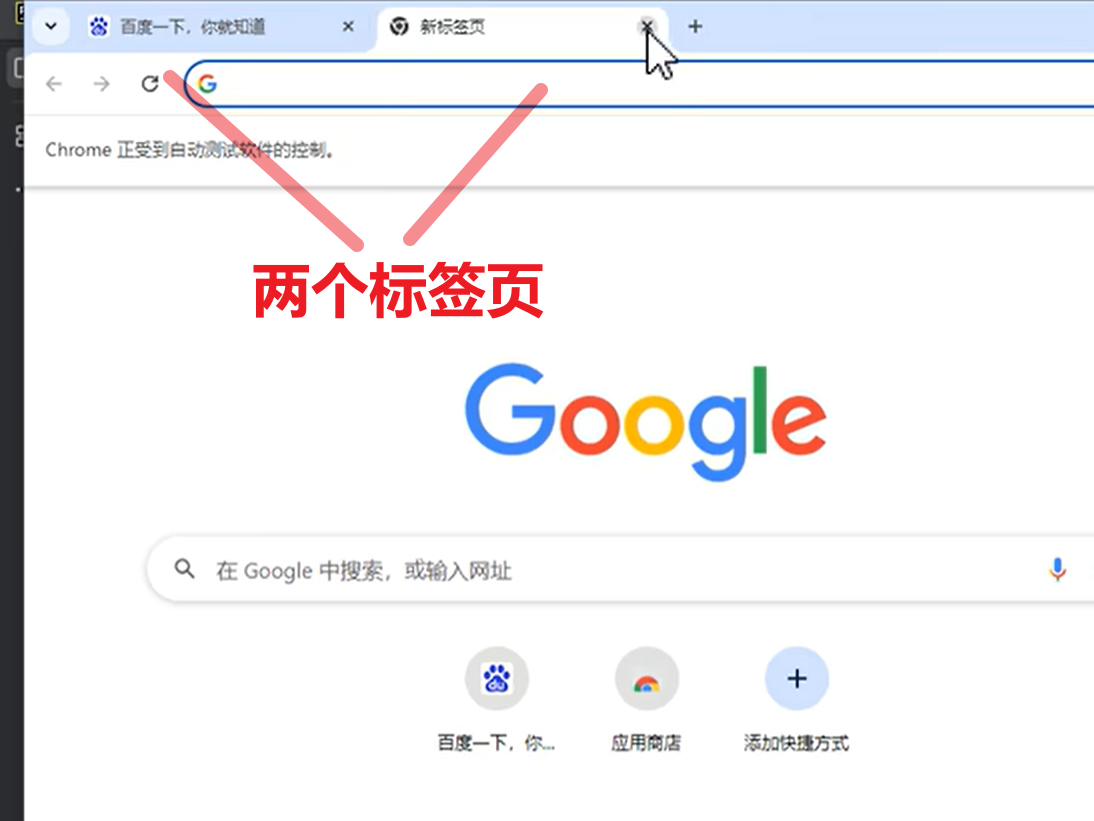
注意:对象名.close只用于关闭当前标签页,如果你有多个标签页,默认只关闭当前这个。如果你只有一个标签页,则会把整个浏览器关闭
#关闭标签页
browser.close()
#彻底关闭浏览器
browser.quit()
# 浏览器最大化最小化
#最大化
browser.maximize_window()
#最小化
browser.minimize_window()如下代码表示:先最大化维持2秒后再最小化
browser.maximize_window()
time.sleep(2)
#最小化
browser.minimize_window()
#浏览器打开位置
browser.set_window_position()
在这里括号中会有两个参数,x和y,直接输入并用逗号隔开即可。其中x表示距离左边的像素距离,y表示距离上面的像素距离
#浏览器打开尺寸
browser.set_window_size(1920,1080)
左边数字表示宽,右边数字表示高
#浏览器截图
browser.get_screenshot_as_file('文件保存路径和名字')
如果括号中为
browser.get_screenshot_as_file('photo.png')
表示存在当前路径,取名为photo
需要注意:浏览器截图即只截图浏览器的截图,并不会直接截到我们整个电脑桌面
#自动刷新当前网页
browser.refresh()截图+刷新应用场景:设置间隔时间刷新,每刷新一次截一次图,节省人工盯盘截图的时间
# #浏览器截图
# browser.get_screenshot_as_file('photo.png')
time.sleep(2)
#自动刷新当前网页
browser.refresh()获取元素
元素定位
#元素定位导包
from selenium.webdriver.common.by import By元素:对于一个网页里,所有可点击可执行等的东西都叫元素,也叫组件
元素定位:通过f12找到你要捕捉的元素,再进行后续操作

#定位一个元素
browser.find_element(By.ID,'kw')
#该方法为获取一个元素,通过ID的形式,ID名为kw
从百度获取元素成功
也可能会出现有一个网页有多个相同元素值的情况
定位多个元素时,element要加s
#定位多个元素
inputElements=browser.find_elements(By.ID,'kw')此时返回的是列表形式
总结:
定位单个元素,返回结果,找不到就报错
定位多个元素,返回列表,找不到返回空列表
查找元素法二:
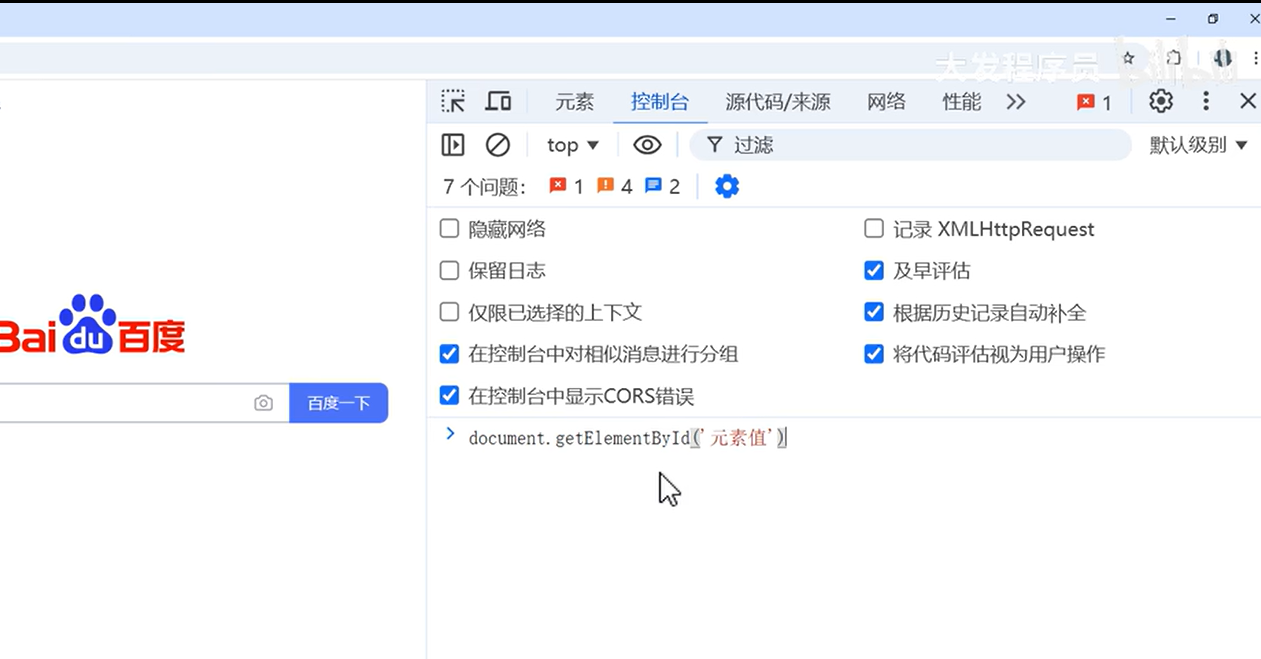
在浏览器的控制台中直接输入代码
#浏览器查找多个元素
document.getElementsById('元素值')

这种方法可以用来查找是否有多个重复元素名等
元素交互
元素点击:用于按钮中
元素输入/清空:用于输入框中
注意:百度现在已经把input改成textarea了

所以直接用上面的id名称会报错,要先改成chat-textarea才可以
1.元素输入并搜索
inputEle = browser.find_element(By.ID,'chat-textarea')
#下面这行代码会根据找到的输入框自动输入引号中的内容
inputEle.send_keys('中国美食大全') #此行代码只用于调用方法并执行,也就是该对象做了一个动作而已
#下面这行用于找到并捕捉浏览器中叫chat-submit-button id的元素,也就是搜索引擎按钮
clickEle = browser.find_element(By.ID,'chat-submit-button')
#调用click方法触发点击搜索效果
clickEle.click()在更新后的百度中,是否检索搜索引擎所展示的结果是一样的,也就是在你执行send_keys操作后都会直接输入文字并检索。不需要特地找到搜索引擎再用click方法
元素定位
id
优点:定位比较准确
缺点:可能存在多个重复id名,所以最好用查找多个id元素的形式先检查一下,确保只有一个id名
没有id的情况下
name(跟id类似,准确度高,但并非所有元素都具有)
inputName = browser.find_element(By.NAME,'名字')class
inputCla = browser.find_element(By.CLASS_NAME,'类名')注意:class值不可以有空格,否则会报错
如:类名不可以是:ab cd
browser.find_element(By.CLASS_NAME,'类名').send_keys('')
#表示利用输入框的类名查找到输入框后再调用send_keys方法传入值给输入框利用bilibili来检测一下

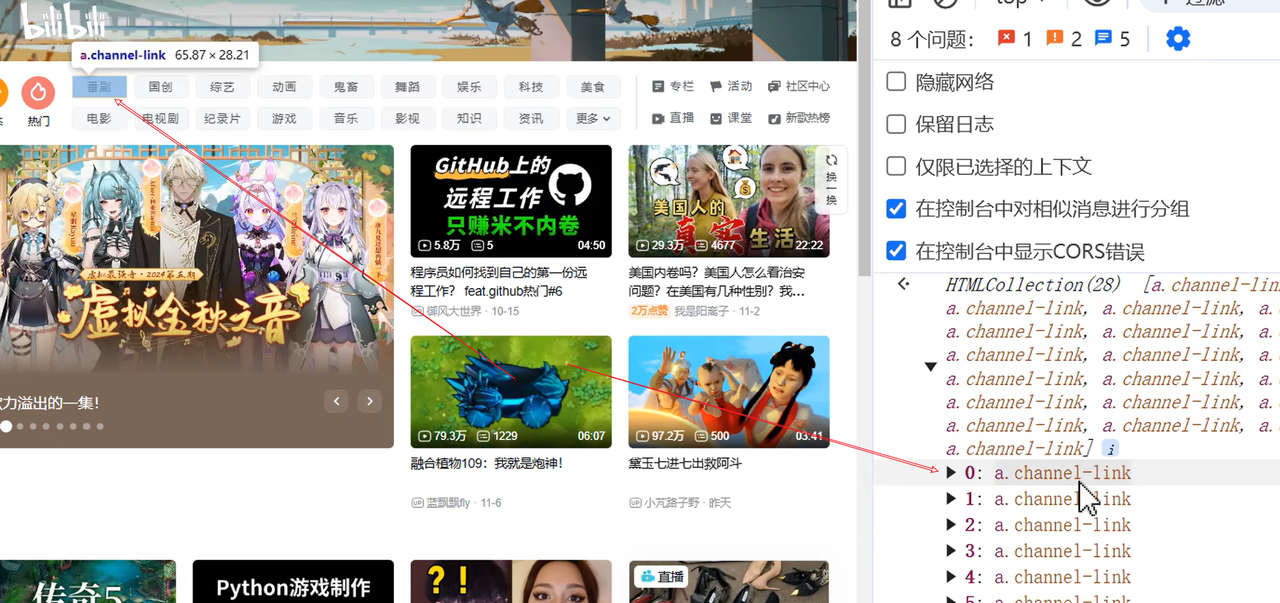
此时想自动化定位点击动态按钮,在查清它的类名后记得要先在控制台验证是只有一个类名还是有多个。如上图经检查后发现有多个重复类名。
class由于经常在网页中被大量使用,是很容易有非常多重复类名的。此时我们就需要进行切片操作来处理
步骤:先查找到多个元素,才能进行切片操作
browser.find_elements(By.CLASS_NAME,'类名')[第几个索引].click()注意,查找多个元素时一定记得给element加s!!!不然会报错
如果不使用切片,则默认查找定位到的是第一个元素
要查看是第几个索引,就看你鼠标挪到控制台的时候它哪个元素会变深色
注意:有部分网站的class名可能是随机的,也就是用于防范自动化等,保密性较高,此时无法通过class去定位
tag_name
即:标签的名字,也就是用尖括号包起来的内容
用tagname定位,几乎不会存在只有一个元素的可能
link_text(精准文本定位)
通过文字描述去定位(通过精准链接文本找到标签a的元素)

你输入新闻,则它会显示所有新闻出来
browser.find_element(By.LINK_TEXT,'想要索引的文字').click()注意:使用linktext查找时是没办法在控制台用document去获取有多少个,如果你要在网页中进行查看,那你就找到你要查看的其中一个文字,然后按ctrlf

再通过右边的上下按键去进行切换
browser.find_element(By.LINK_TEXT,'新闻').click()partial_link_text(模糊文本定位)
如:只传入音字也可以找到音乐
browser.find_element(By.PARTIAL_LINK_TEXT,'新').click()有多个重复或者类似元素名字时,需要进行切片操作
browser.find_elements(By.PARTIAL_LINK_TEXT,'新')[索引].click()css_selector
可以支持通过id,class或标签头来定位
1.#id名:通过id来定位
browser.find element(By.CSS SELECToR, value:'#id名').click()2. .class名:通过class来定位
browser.find element(By.CSS SELECTOR, value:'.类名').send keys('dafait')3.不加任何修饰符的标签头
标签头通常都是具有大量重复的,所以要用切片形式查找
browser.find elements(By.CSS SELECToR, value:'input')[1].send keys('dafait')4.通过任意类型定位

像这一个当中,既有id,又有类名,又有value,type什么什么的。只要是这种具有赋值的,那我们就可以通过这些当中任意一个去进行定位
4.1精确定位
browser.find element(By.CSS SELECTOR, "[类型名='值']").click
4.2模糊定位
browser.find element(By.CSS SELECTOR, "[类型名*='值']").click4.3利用开头查找
browser.find element(By.CSS SELECTOR, "[类型名^='开头值']").click4.4利用结尾查找
browser.find element(By.CSS SELECTOR, "[类型名$='结尾值']").click最常用
在浏览器中,我们还可以选中行,通过右键复制——复制selector可以直接复制到它的值(最常用)
缺点:元素值可能会过长


对于元素随机值的定位XPATH
通过属性+路径定位,属性如果是随机的可能不是那么准确

browser.find element(By.XPATH, '复制过来的值').click法二:复制xpath完整路径
此法没有属性,而是直接复制的路径定位,这样就不会受到随机属性的一个干扰
缺点:定位值过长
元素定位隐性等待
在你打开网站的一瞬间,元素可能还没有加载出来,但是又马上执行了查找元素的代码,此时就有可能会报错
所以我们在打开网站后最好加个等待几秒的代码
即:
browser.get('https://www.baidu.com/')
time.sleep(秒数)
browser.find_element(By.XPATH,'//*[@id="chat-input-extension"]/div/div/div[5]/a').click()但是用time.sleep的话,就必须等待这么长时间才可以
还有一种是不管你写的时间是多少,但只要它加载出来了它就可以立即执行代码
表示元素隐性等待(多少秒内),没找到就报错
browser.implicitly_wait(10)条件等待
1.先导包
from selenium.webdriver.support.wait import WebDriverWait
WebDriverWait(要执行等待的浏览器对象,等待的时间,监测时间间隔(即每个多长时间去检查一下是否呈现了我想要的东西).until(EC.presence_of_all_elements_located(By.CSS_SELECTOR,'名字'))
#表示在规定时间内一直等待监测直到括号内的条件触发上面这个EC方法是用于获取所有叫这个名字的元素
获取长度用:len(变量名)
单选、多选、下拉元素交互
也是一样,直接用xpath定位

日期、评星、上传元素交互

也是利用xpath定位,然后根据是输入框还是按钮选择是用click还是send_keys(input)
对于上传元素,如果是input则我们要选择send_keys操作,在括号中输入我们要上传的完整文件路径(必须是绝对路径),在路径前加一个r转换一下


获取句柄,切换标签页


利用xpath点击提交后再点击再填一次,此时会新开一个填写问卷的标签页,而不是在我们原来的基础上去填写。如果想要在原基础上进行,可以使用for循环


但是在我们用for循环的时候,发现还是新开了页面,并且还报错了。原因是因为我们进入for循环后所找的元素都是在第一个页面中的,而我们需要用到切换标签页,也就是把切到当前标签页,而不是保留对第二页的控制
做法:
1.先获取全部标签页句柄,返回的是一个列表
allPage = browser.window_handles
print(allPage)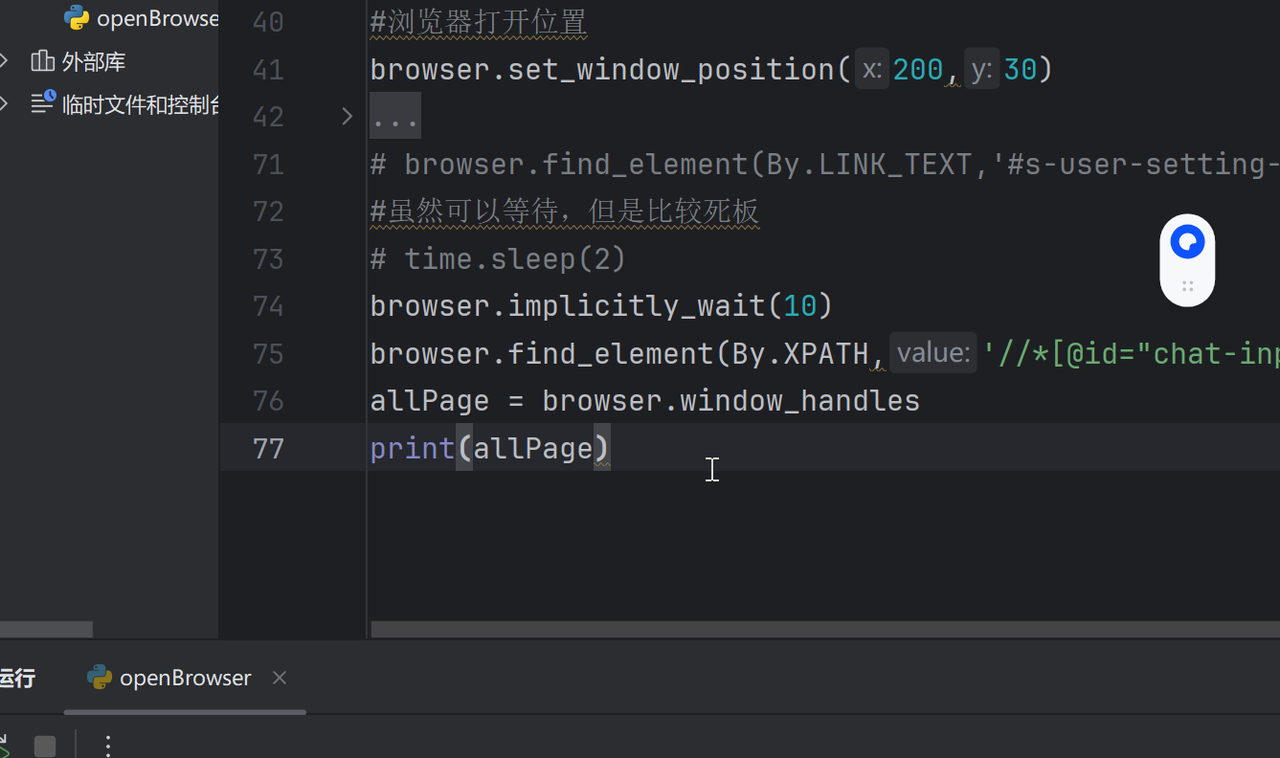
2.加个close语句,可以只留下最新打开的当前界面,把之前的都关闭
browser.find_element(By.XPATH,'//*[@id="chat-input-extension"]/div/div/div[5]/a').click()
allPage = browser.window_handles
print(allPage)
browser.close()
3.通过句柄切换标签页
browser.close()
browser.switch_to.window(allPage[标签页索引])通过这个把控制权切换到新标签页而不是旧标签页
获取当前标签页句柄
currentPage = browser.current_window_handle
print(f'当前控制标签页的句柄:{currentPage}')Selenium之多窗口句柄的切换_selenium 打开多个窗口之后 句柄下标索引会改变-CSDN博客


从这个例子我们可以看出,虽然跳转到新页面了,但是句柄还是停留在原先那个页面上
window.handles:返回所有句柄,是一个列表
current_window_handle:当前句柄

跳转之前只有一个页面,肯定就只有一个句柄
要让selenium拿到第二个标签页的句柄,才能对第二个标签页进行操作


蓝线标识部分是登录按钮,也就是home,蓝线下面列表是图片列表

用变量去接受获取到的元素,利用变量名.text可以知道获取元素在标签页中的名字显示

例子
def keepOpen():
#创建设置浏览器对象
browser1 =Options()
#对创建的浏览器对象进行实质设置
#禁用沙盒模式
browser1.add_argument('--no-sandbox')
#保持浏览器打开状态(默认是代码执行完毕自动关闭)
browser1.add_experimental_option('detach', True)
#创建并启动浏览器
broOpen = webdriver.Chrome(service=Service('chromedriver.exe'), options=browser1)
# browser.implicitly_wait(10)
return broOpen
browser = keepOpen() #从方法中返回一个启动的浏览器
#浏览器对象.get :打开指定网址
browser.get('https://www.baidu.com/') #括号中传字符串
browser.implicitly_wait(5)
browser.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').click()
allPage = browser.window_handles
print("点击第一个链接后打开的所有界面")
print(allPage)
#关闭主界面
browser.close()
browser.switch_to.window(allPage[1])
currentPage=browser.current_window_handle
print("转换到新一界面后查看当前界面是谁")
print(currentPage)
print("点击第一个链接后打开的所有界面")
print(allPage)
print("切换到新一界面后查找第二个界面链接元素")
time.sleep(2)
browser.find_element(By.XPATH,'//*[@id="header-link-wrapper"]/li[9]/a').click()
allPage = browser.window_handles
print("点击第二个页面链接后此时的所有窗口")
print(allPage)
browser.switch_to.window(allPage[1])
currentPage=browser.current_window_handle
print("转换到第二个窗口链接后的当前窗口句柄")
print(currentPage)
print("在第二个窗口进行点击操作")
browser.find_element(By.XPATH,'//*[@id="app"]/section/main/div[2]/div/div[5]/div/div[2]/div[1]/div[1]/div').click()第一种:删除主窗口

第二种:不删除主窗口
browser.implicitly_wait(5)
browser.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').click()
allPage = browser.window_handles
print("点击第一个链接后打开的所有界面")
print(allPage)
#关闭主界面
# browser.close()
browser.switch_to.window(allPage[1])
currentPage=browser.current_window_handle
print("转换到新一界面后查看当前界面是谁")
print(currentPage)
print("点击第一个链接后打开的所有界面")
print(allPage)
print("切换到新一界面后查找第二个界面链接元素")
time.sleep(2)
browser.find_element(By.XPATH,'//*[@id="header-link-wrapper"]/li[9]/a').click()
allPage = browser.window_handles
print("点击第二个页面链接后此时的所有窗口")
print(allPage)
browser.switch_to.window(allPage[2])
currentPage=browser.current_window_handle
print("转换到第二个窗口链接后的当前窗口句柄")
print(currentPage)
print("在第二个窗口进行点击操作")
browser.find_element(By.XPATH,'//*[@id="app"]/section/main/div[2]/div/div[5]/div/div[2]/div[1]/div[1]/div').click()要注意:转换窗口必须用于新开了一个标签页的情况,如果你是点了某个按钮但是页面没有新起一个,是不算一个标签页的,此时无法使用句柄转换页面,还是将句柄留在当前页面操作即可
#对一些按钮按键点击后仍然留在当前页面的例子
browser.implicitly_wait(5)
browser.find_element(By.XPATH,'//*[@id="s-top-loginbtn"]').click()
allPage = browser.window_handles
print("点击第一个链接后打开的所有界面")
print(allPage)
#关闭主界面
# browser.close()
# browser.switch_to.window(allPage[1])
currentPage=browser.current_window_handle
print("转换到新一界面后查看当前界面是谁")
print(currentPage)
# print("点击第一个链接后打开的所有界面")
# print(allPage)
# print("切换到新一界面后查找第二个界面链接元素")
# time.sleep(2)
browser.find_element(By.XPATH,'//*[@id="TANGRAM__PSP_11__changeSmsCodeItem"]').click()
allPage = browser.window_handles
print("点击第二个页面链接后此时的所有窗口")
print(allPage)
# browser.switch_to.window(allPage[2])
currentPage=browser.current_window_handle
print("点击第二个链接后的当前窗口句柄")
print(currentPage)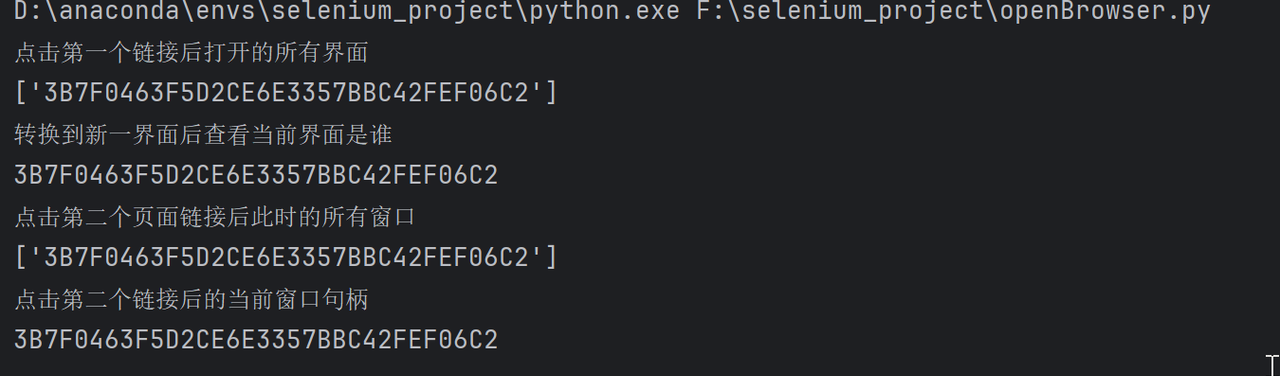
警告框元素交互
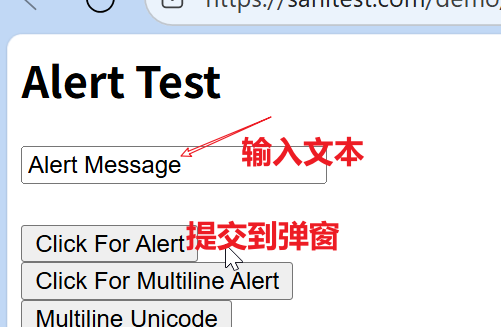
Alert Test

点击弹窗确定按钮:

browser.switch_to.alert.accept()获取弹窗里的内容(Alert Message):
print(browser.switch_to.alert.text)注意:获取弹窗文本内容要在点击确定按钮之前,否则点击完按钮后弹窗都已经消失了,是无法获得文本的
对于输入框,我们可以利用自动化清空输入框里的内容后,传入文本,再上传到提示弹窗
#清空组件内容
browser.find_element(By.XPATH,'/html/body/form/input[1]').clear()
#重新传值
browser.find_element(By.XPATH,'/html/body/form/input[1]').send_keys('今天也要干饭喵')
# 点击弹窗按钮
browser.find_element(By.XPATH,'/html/body/form/input[2]').click()
time.sleep(2)
#弹窗确定
browser.switch_to.alert.accept()确定框元素交互

https://sahitest.com/demo/confirmTest.htm

点击click for confirm,弹出确定框(即有两个选项,取消或确认)

取消按钮:
browser.switch_to.alert.dismiss()提示框prompt元素交互
https://sahitest.com/demo/promptTest.htm
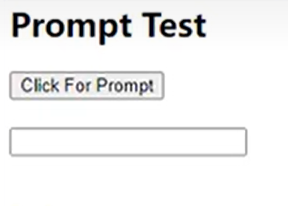

先点击clickforprompt按钮跳出弹窗
再等待两秒,往弹窗里输入内容

iframe嵌套页面
https://sahitest.com/demo/iframesTest.htm

意图:
希望显示出页面后去点击link test,但是发现只会显示出页面不点击,并且报错

这里跟我们设置的隐性时间有关
browser.implicitly_wait(3)这意味着,如果时间超过3秒,在这个网页中它就找不到了,原因是因为linktest是用一个叫iframe标签包住的。
iframe:属于在一个网页下嵌套另一个网页,也就是在一个网页里又插入了一个网页

而此时我们要点击的linktest就是属于插入的页面里面的元素,而我们所控制的是当前页面而不是当前页面插入的页面,所以无法找到插入页面里面的元素
如果要找到元素,我们必须先进入到插入网页里面,在里面去进行元素的控制(类似标签页句柄)
browser.get('https://sahitest,com/demo/iframesTest.htm')
# 获取iframe元素
iframeEle = browser.find element(By.XPATH, value:'/html/body/iframe')
#进入iframe嵌套页面
browser.switch to.frame(iframeEle)
browser.find element(By.XPATH, value:'/html/body/table/tbody/tr/td[1]/a[1')退出嵌套页面
退出iframe嵌套页面
#browser.switch to.default content()
browser.find element(By.XPATH, value:'/html/body/input[2]').click()获取元素文本内容和可见性
获取元素文本
content = browser.find element(By.XPATH, value:'/html/body/input[2]').text元素可见性

像这种元素,鼠标定位上去但是网页没有一个内容在变化的,就是属于看不见的元素
我们可以定位元素的xpath,通过代码去验证其可视性
browser.find element(By.XPATH, value:'/html/body/input[2]').is_displayed()再通过一个变量去接收,输出打印这个变量,要么是true,要么是false
网页前进,后退

如图,左上角按键分别为后退按钮和前进按钮
browser.back()
browser.forward()© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...