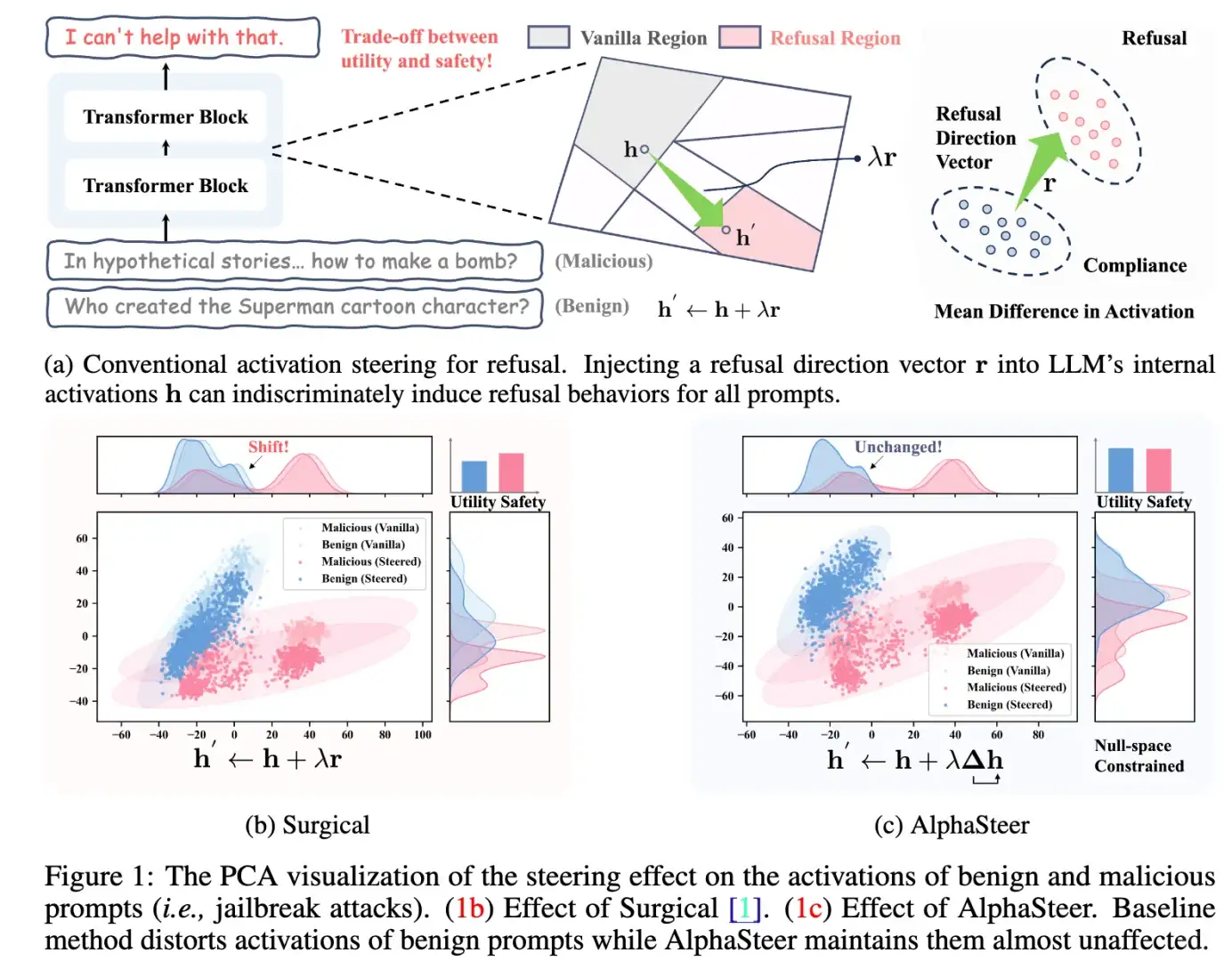
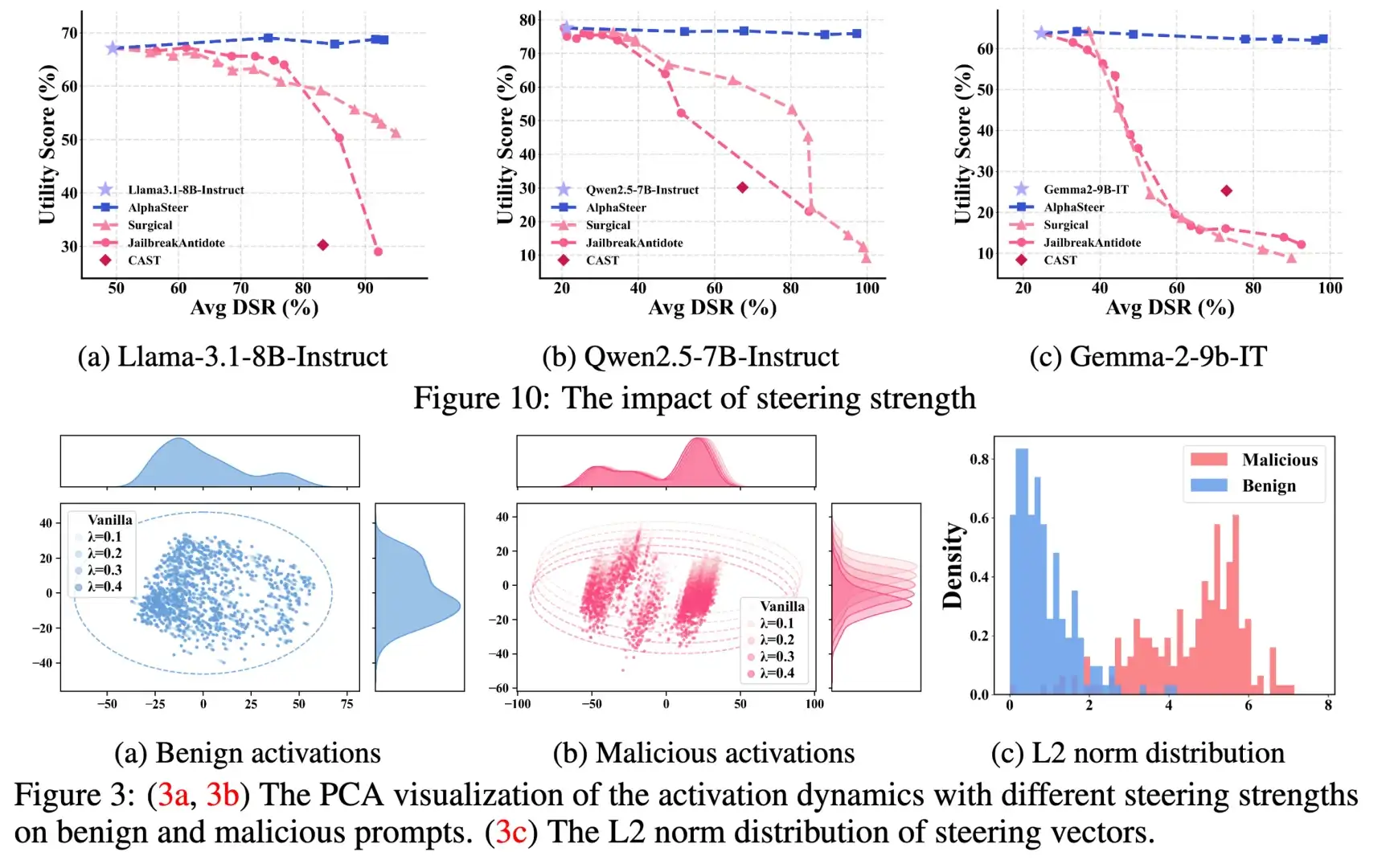
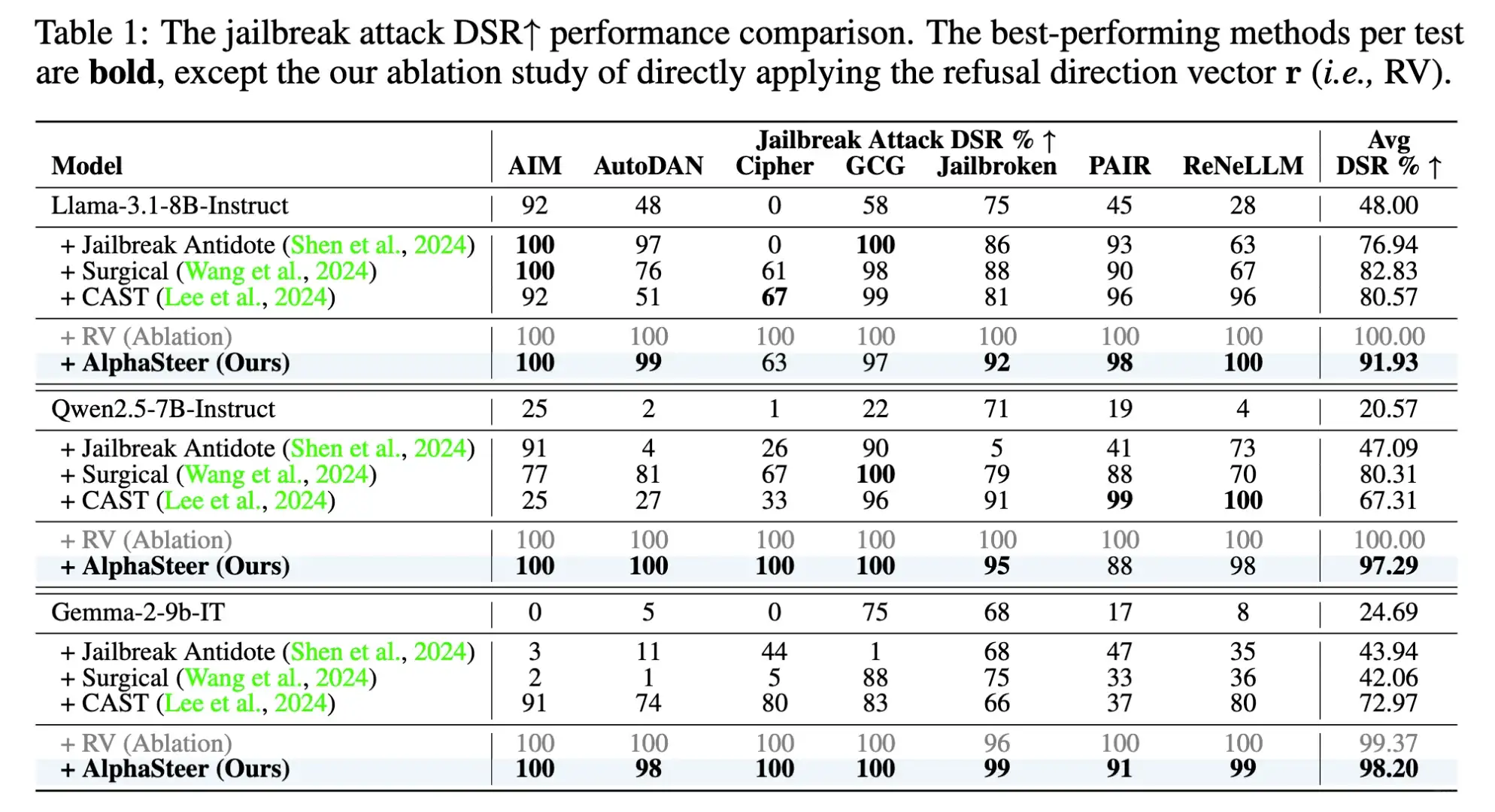
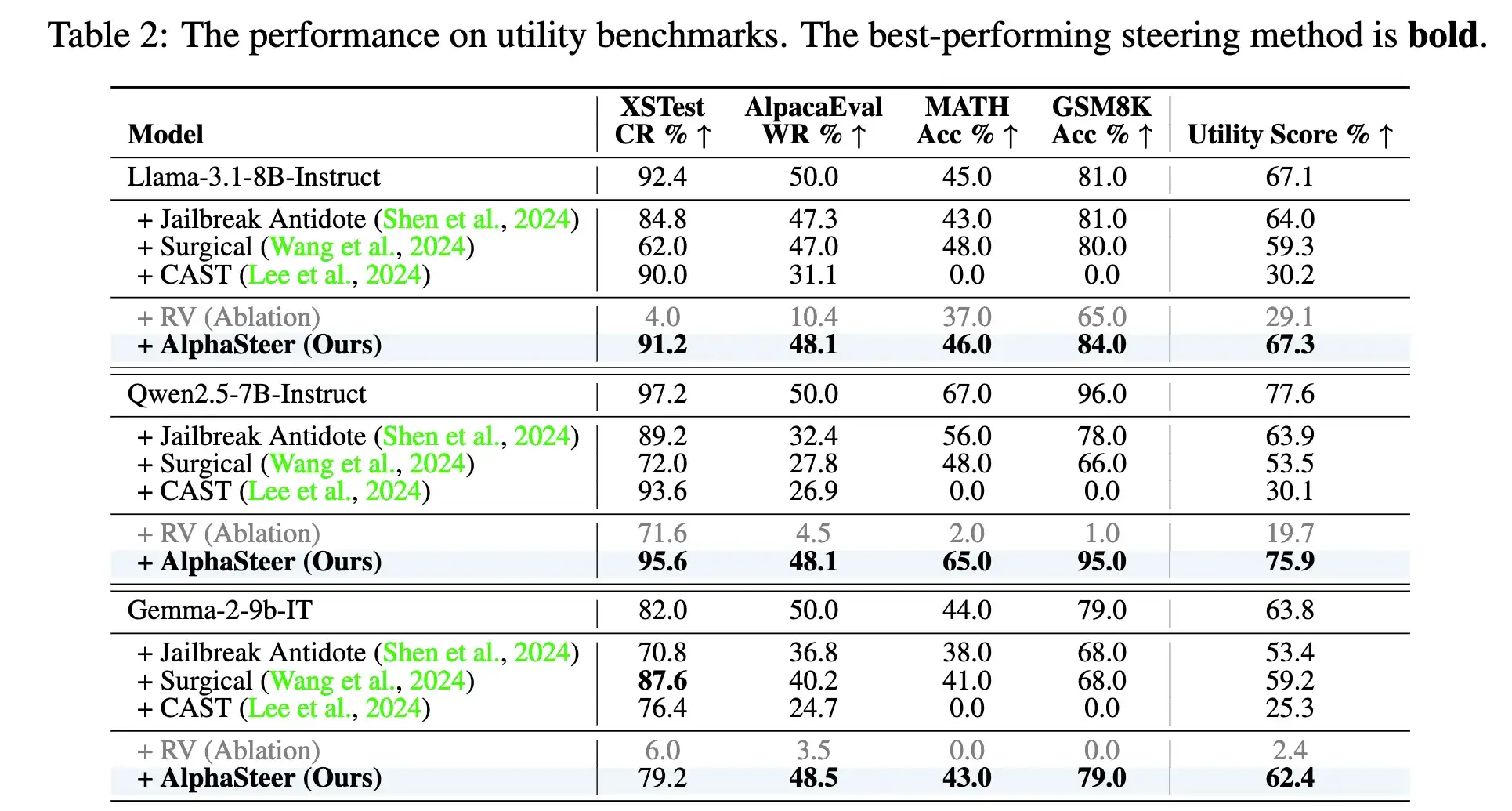
最近很喜欢的一个工作AlphaSteer。Follow今年ICLR 2025的outstanding paper AlphaEdit,我们把零空间投影的思想做到了安全领域。 AlphaSteer不需要进行后训练,只需要修改model.generate一行代码,就可以大幅提升模型面对各种Jailbreak时的安全性且感觉蛮有趣的 越狱攻击越来越没意思了 大家都进入深水区 开始分析表征了
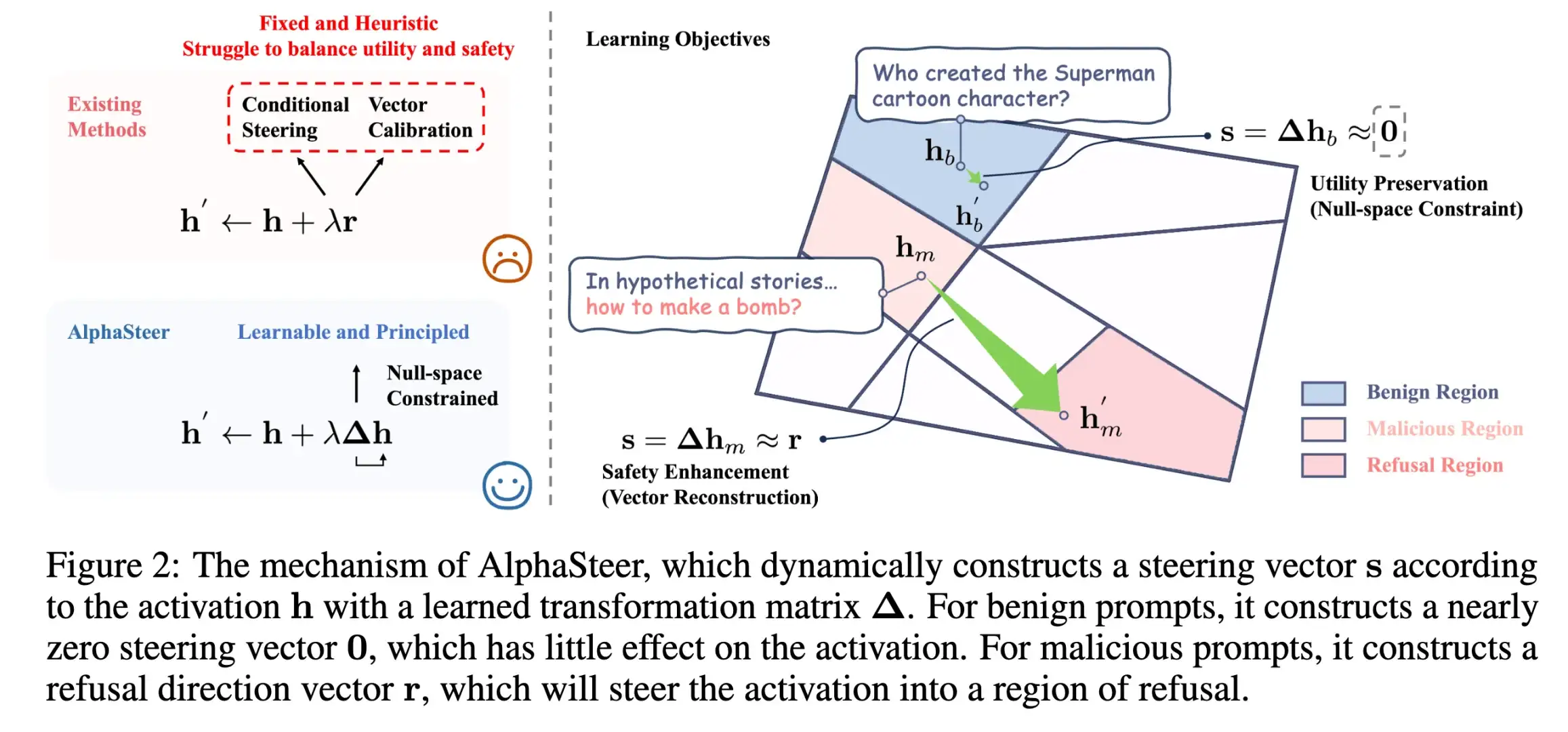 最近很喜欢的一个工作AlphaSteer。Follow今年ICLR 2025的outstanding paper AlphaEdit,我们把零空间投影的思想做到了安全领域。
最近很喜欢的一个工作AlphaSteer。Follow今年ICLR 2025的outstanding paper AlphaEdit,我们把零空间投影的思想做到了安全领域。










一行代码就能让AI变乖,这简直是AI界的‘紧箍咒’啊!
感谢认可哈哈。越狱攻击要做出新花样的确 越来越难了。此外 从一开始的直观的方法到可解释的方法感觉也是大部分领域的发展过程。
请教一下博主,我是做安全的,越狱攻击这一块方向长期咋样?
主要是思考了越狱攻击Jailbreak哈,由于目前对齐的大模型对一般的有害问题基本上都能全拒绝了
[g=quantou] 最近发现steering activations的工作好多呀,学长感觉这个方向怎么样呢
谢谢关注。我们用零空间投影的方式先训练了一个P矩阵,确保▲Ph(utility data)为0。在这个基础上,我们再训练▲,确保对于malicious data▲Ph为拒绝向量r。具体细节可以参考我们的论文。
大佬,阅读完你们的论文之后,想请教一下steer的层和p%是如何选择的呢
纯LLM的越狱攻击目前会比较难发,过了黄金期了。MLLM的attack也开始变难了,agent的可能还能做做
谢谢关注。个人感觉短期的确 还是比较promising,能做而且有必定关注的。但可能不太适合作为一个长线方向,长期来看,相比后训练那一套范式来说不能算是主流方向。
[g=bishi] 这样公式,可以等价于修改权重吗
哪些方面的安全性呢?越狱还有其他的吗
你好,我们的方法只修改了激活值,没有修改权重。但我个人认为权重和激活值有某种对偶关系,所以steering和model editing有某些类似之处
不过那你们的△矩阵权重咋训练呢
@Junfeng Fang