大家好,很高兴为大家介绍我们的新工作--Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression,后面我们简称TransDiff。 Paper: https://arxiv.org/pdf/250Soul居然也有科研部门啊


 大家好,很高兴为大家介绍我们的新工作–Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression,后面我们简称TransDiff。
大家好,很高兴为大家介绍我们的新工作–Marrying Autoregressive Transformer and Diffusion with Multi-Reference Autoregression,后面我们简称TransDiff。







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/10.jpg)



才发现还有这篇。从benchmark来看,我们应该还是有不小的优势。
[g=haobang] 这个架构和iclr 2025的NOVA视频生成好像啊
请问和orthus区别是?
觉得soul不好用可以去github下面留言吗
[g=wozuimei] 1-step AR里面的diffusion也是单步的吗,这个是怎么做到的
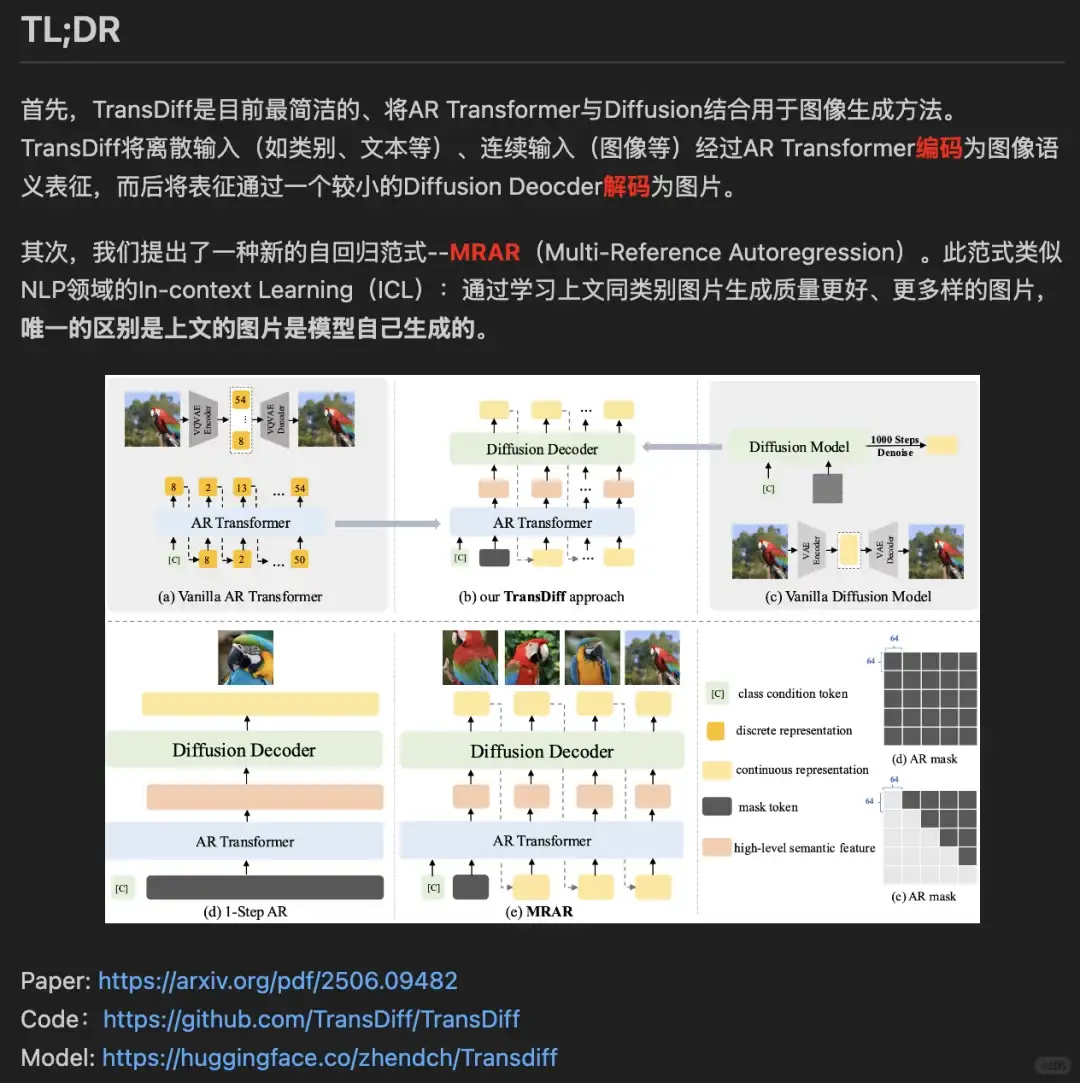
是的。 训练中,ar的输入是同类别其他图片。推理中是之前生成的图片。
我也刚看到这篇论文。Orthus应该还是Mar的衍生方法:在语言模型上嫁接个diffloss的头,做的是t2i任务。 然后Mar和我们方法的具体区别,可以参考第4张图哈
这个soul是我想的那个嘛
你猜对了
和transfusion比主要进步在哪呢?
也有的。 今年还有一篇cvpr,不过体量和声量都刚开始起步 不过7月可以关注我们语音和视频全双工工作,效果也是比较领先 哈哈 预告下
回复不能超过300字,我图片回复哈 有问题随时交流
[g=zhuakuang] 这个ar的unit是什么呀 是reference image吗
和acdit对比怎么样呢
哦哦 你说的是的,但是可能不全对哈。 我解释下,智源的NOVA是完整参考了MAR,所以Diffusion也是和MAR一样的n层MLP。这种结构就会带来一个问题:不仅Diffusion需要N步解码,Transformer也需要多次迭代(MAR是256,NOVA是128)。而我们的结构,由于使用了更复杂(但参数量增加不多的Dit结构)的Diffusion Decoder,可以一次生成的,当然也可以参考第4图的第二个问题哈。不知道是不是解释清楚哈
没 ,1Step AR指的是 ar transformer, diffusion还是多步,但是diffusion相对较小。