什么是RAG 大模型很聪明,但也有短板👇 📌 上下文长度有限 比如 deepseek-r1 满血版的上下文上限是 128K tokens,不能无限输入文本,超过了它就处理不了 📌 知识可能过时 如果模型是基于 2024 年前的数据训练的,你问它 2025 年发生的事,它可能会一本正经地胡说八道,即产生“模型全局理解任务怎么办




 什么是RAG
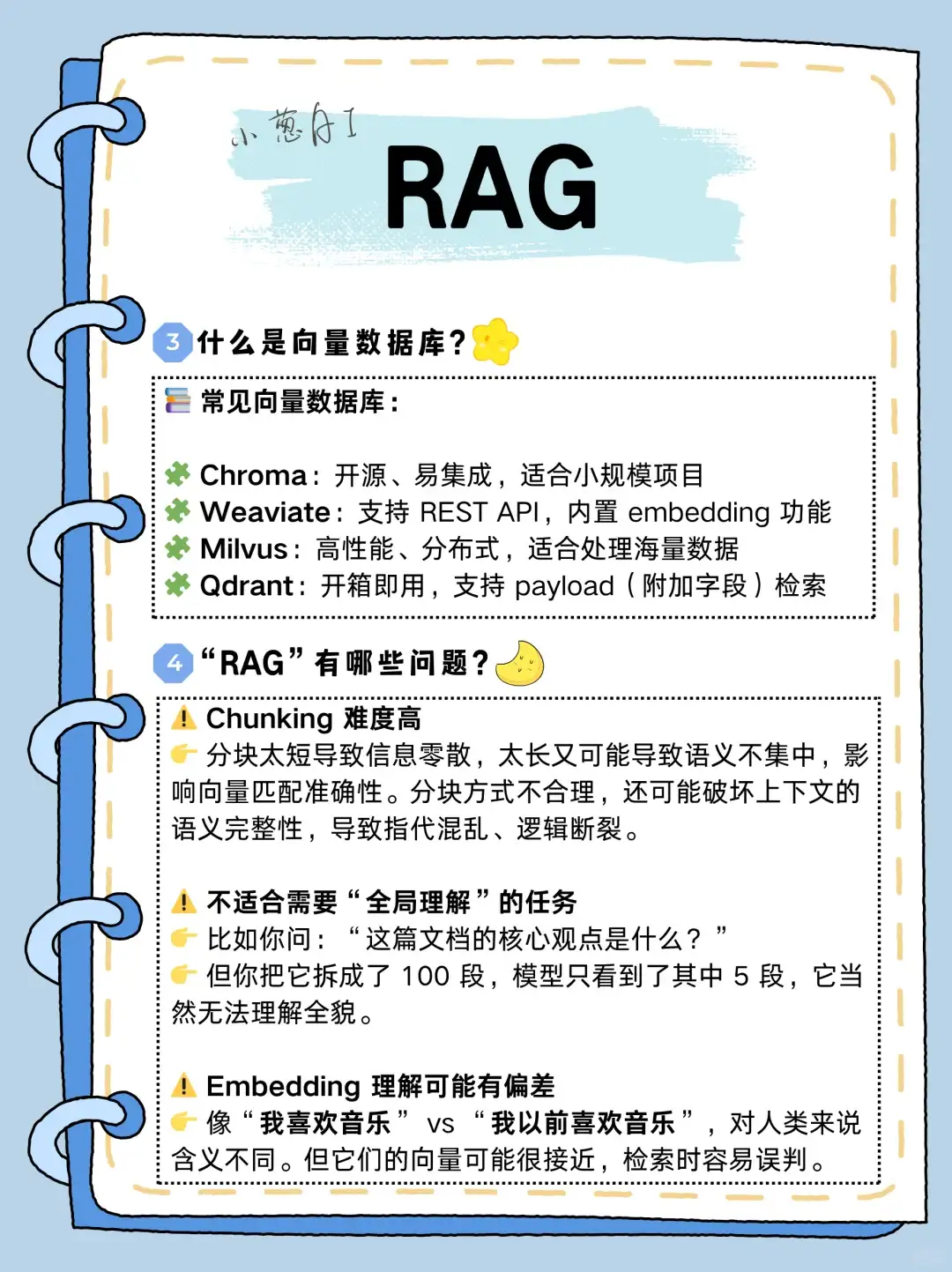
什么是RAG









问题的向量和答案的向量进行匹配嘛
好问题!你说的这种,实则是调用了搜索引擎工具,去查实时网页,再结合网页信息让模型回答问题。听起来和 RAG 很像,都是“先查资料再回答”。但严格来说,这更偏向于是模型的工具调用能力,不是传统那种自己建知识库、做向量检索的 RAG。也可以理解为:搜索引擎已经帮你做了索引,所以你不用自己建知识库了。广义上算是 RAG 的一种更灵活实现方式吧~
RAG 是先把用户的问题变成向量,然后用这个向量去找相关的文档或资料(这些文档也都转成了向量),找到之后再把这些资料 + 问题一起发给大模型,让它来生成回答~所以匹配的是 ‘问题和资料’ 的向量,不是问题和答案直接匹配哈
谢谢武大学弟支持,AI相关问题随时交流~
召回后加入一下重排试试
实则用纯Prompt也能做,但有两个坑:一、模型没学过的知识(列如公司内部的),它就容易瞎编。二、当然你也可以手动找相关资料塞进Prompt,但太麻烦了,RAG就是把这流程(检索和生成)自动化了
这个系列是通俗易懂科普AI知识点,之后会开个系列专门讲解真实开源项目,和一些案例,谢谢提议
能不能介紹幾個從0到1的RAG項目呢?
感谢宝子提议,之后会开个开源项目分享系列(博主也一直在看各种开源项目)
谢谢亲的提议~我实则一直想开些新的系列,照顾到不同类型的读者!就是目前还在上班,更新可能没那么快,我会尽量抓紧安排起来哈~
谢谢讲解!期待博主能出一些适合新手的教程
有没有案例呢
博主老师,所以DeepSeek-R1也使用了RAG吗?他在回答问题之前也会去检索网页,RAG算是一种改善的算法吗?
学长,虚心学习,帖子写的真好
RAG任务效果可以用prompt替代吗?
那知识库怎么做可以提高精准度呢?
这个是可以调的哈,列如你可以把retriever召回文档的数量调大一点。同时也可以看看是不是一开始切文档的时候切得太大了,导致向量库里存的条目很少,每条内容又特别多,这样匹配的时候就容易不准。还有种可能是你的问题本身和知识库里的内容匹配度不高,可以试试让大模型先把你的问题扩展成几个更具体、语义更清晰的问题,再用这些问题去向量库里匹配相关文档。如果你调高召回数量之后又担心超过上下文长度,那可以加个rerank做精排,或者让大模型先把召回到的内容做成总结或摘要,再作为上下文扔给大模型生成回答。 [g=touxiao]
想让它回答问题时用许多知识库文件回答我,但每次只引用几篇,想问问怎么解决 [g=wunai]
[g=juhua][g=juhua] 不好意思刚看错你的问题了。目前还没有特别成熟的方案(虽然有不少探索方向和研究,也有一些靠堆资源、牺牲速度换准确率的预处理方法),但总的来说,目前的RAG架构还是不太擅长处理这类问题。