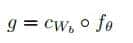提示工程架构师视角:为什么机器人控制提示系统是「新基建」?(附行业深度分析)
引言:从一个工厂场景说起
清晨8点,深圳某新能源汽车零部件工厂的装配线上,25岁的工人小周盯着眼前的协作机器人,皱着眉头拨通了工程师的电话:「张工,昨天调试好的「抓取红色电容」程序,今天换了个批次的零件,机器人就「懵」了——它总是抓不住电容的边缘,能不能帮我改改程序?」
电话那头的张工叹了口气:「我在坂田的另一个工厂,得下午才能到。你先试试用ROS重新调一下逆运动学参数?或者看一下URDF文件里的夹爪尺寸有没有错?」
小周挂了电话,望着屏幕上满是代码的ROS终端,苦笑一声——他入职才3个月,ROS(机器人操作系统)的教程还没看完一半。
这不是个例。根据《2023年中国工业机器人应用现状白皮书》,72%的制造企业表示「机器人编程难」是制约规模化应用的核心痛点:传统机器人依赖工程师编写底层代码(如ROS节点、PLC逻辑),工人无法直接操作;即使是「示教器编程」,也需要专业培训,且无法快速适配新场景。
直到2024年,这家工厂引入了一套「机器人控制提示系统」——小周只需对着麦克风说:「把红色电容的抓取位置往上调2厘米,夹爪力度减10%」,系统就会自动将自然语言指令转化为机器人的关节角度、夹爪力度参数,10秒内完成调试。
这个场景背后,藏着一个被忽略的技术趋势:机器人控制提示系统正在成为「机器人时代的新基建」——它不是某个功能模块,而是连接「人-机器人-场景」的底层数字基础设施,支撑着机器人从「工具化」向「智能化」的跨越。
一、概念拆解:什么是「新基建」?什么是「机器人控制提示系统」?
在讨论「为什么是新基建」之前,我们需要先明确两个核心概念的边界。
1.1 重新理解「新基建」:数字时代的「地基」
2020年,中国官方首次明确「新基建」的范围:以5G、人工智能、工业互联网、物联网为代表的新型基础设施。其核心特征是「数字赋能」——通过底层技术架构,将物理世界的资源(如机器、设备、人)连接起来,支撑上层的数字化应用。
如果说传统基建(公路、桥梁、电网)解决的是「物理连接」问题,那么新基建解决的是「数字连接」问题:
5G解决「数据传输的速度」;工业互联网解决「设备间的通信」;而机器人控制提示系统,解决的是「人与机器人的语义连接」——这是机器人规模化应用的最后一道「数字鸿沟」。
1.2 机器人控制提示系统:连接「人类意图」与「机器执行」的「翻译机」
机器人控制提示系统(Robot Control Prompt System, RCPS)的定义可以简化为:基于自然语言/多模态输入,将人类意图转化为机器人可执行动作的中间层系统。
它的核心逻辑是「三层映射」:
意图映射:将人类的自然语言(如「拿杯子」)或多模态信号(如手指向杯子+说「拿那个」)转化为明确的任务目标(如「抓取目标物体:杯子,目标位置:用户右手边」);任务映射:将任务目标分解为机器人可执行的步骤序列(如「移动到杯子上方→调整姿态→闭合夹爪→移动到用户位置→打开夹爪」);动作映射:将步骤序列转化为机器人的底层控制指令(如关节角度、电机转速、传感器阈值)。
简言之,RCPS的本质是**「人机交互的操作系统」**——就像Windows系统让用户不用学汇编语言就能用电脑,RCPS让普通用户不用学ROS就能控制机器人。
二、为什么说RCPS是「新基建」?四个核心逻辑
要回答「为什么是新基建」,我们需要回到新基建的本质:是否支撑了产业的规模化、智能化升级?是否成为了数字生态的底层架构?
从这个角度看,RCPS的「新基建属性」体现在四个核心维度:
2.1 维度一:打破「人机语言壁垒」,降低机器人使用门槛(普惠性)
传统机器人的「使用门槛」源于「语言差异」:人类用自然语言表达意图(「把零件放左边」),而机器人只懂底层代码(「joint1: 30°, joint2: 45°」)。这种差异导致:
人力成本高:企业需要专门的机器人工程师,薪资是普通工人的3-5倍;场景适配慢:换一个零件型号,需要重新编写代码,耗时数小时甚至数天;用户覆盖窄:只有专业人士能操作机器人,普通工人、老人、儿童无法使用。
RCPS的出现,本质是用「提示工程」解决了「语言翻译」问题——通过大模型(如GPT-4、Llama 3)将自然语言转化为机器人能理解的「机器语言」。
技术原理:意图识别与任务分解的「双轮驱动」
意图识别是RCPS的「入口」——它需要解决两个问题:用户说的是什么?用户需要机器人做什么?
以「把红色零件放到传送带上」为例,意图识别的技术流程如下:
文本嵌入:用BERT等预训练模型将用户指令转化为高维向量(如768维),捕捉语义信息;语义匹配:计算用户指令向量与机器人「任务库」向量的余弦相似度(公式1),找到最匹配的任务;意图补全:结合场景上下文(如当前是工厂装配线),补全模糊信息(如「红色零件」是指「型号为C100的红色电容」)。
公式1:余弦相似度计算
任务分解是RCPS的「中间层」——它将意图转化为可执行的步骤。例如,「把红色零件放到传送带上」会被分解为:
激活视觉传感器,识别红色零件的3D坐标;计算机械臂到零件位置的逆运动学解;控制机械臂移动到零件上方,调整夹爪姿态;闭合夹爪,抓取零件;计算机械臂到传送带的路径(避障);移动到传送带位置,打开夹爪释放零件。
代码示例:用BERT实现意图识别
from transformers import BertTokenizer, BertModel
import torch
import numpy as np
# 1. 加载预训练模型与分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. 构建机器人任务库(示例:工业场景)
task_library = {
"pick_red_capacitor": "Pick up the red capacitor (model C100)",
"place_on_conveyor": "Place the part on the conveyor belt (line 3)",
"inspect_part": "Inspect the part for surface defects using the camera"
}
# 3. 生成任务库的嵌入向量(离线预处理)
task_embeddings = {}
for task_id, desc in task_library.items():
inputs = tokenizer(desc, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS] token的嵌入作为任务语义向量
task_embeddings[task_id] = outputs.last_hidden_state[:, 0, :].numpy()[0]
# 4. 定义意图识别函数
def recognize_intent(user_input):
# 生成用户输入的嵌入向量
inputs = tokenizer(user_input, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
outputs = model(**inputs)
user_emb = outputs.last_hidden_state[:, 0, :].numpy()[0]
# 计算与任务库的余弦相似度
similarities = {}
for task_id, emb in task_embeddings.items():
sim = np.dot(user_emb, emb) / (np.linalg.norm(user_emb) * np.linalg.norm(emb))
similarities[task_id] = sim
# 返回最相似的任务ID(相似度阈值设为0.7,低于则返回「无法识别」)
max_sim = max(similarities.values())
if max_sim < 0.7:
return "unrecognized_intent"
return max(similarities, key=similarities.get)
# 5. 测试:用户输入「Grab the red C100 capacitor」
user_input = "Grab the red C100 capacitor"
intent = recognize_intent(user_input)
print(f"识别到的意图:{intent}")
print(f"对应的任务描述:{task_library[intent]}")
运行结果:
识别到的意图:pick_red_capacitor
对应的任务描述:Pick up the red capacitor (model C100)
2.2 维度二:统一「机器人异构接口」,支撑规模化落地(通用性)
当前机器人产业的另一个痛点是「异构性」——不同厂商的机器人(如ABB、发那科、埃斯顿)使用不同的控制协议(如ABB的RAPID、发那科的Karel),不同类型的机器人(工业机器人、服务机器人、医疗机器人)的底层架构差异巨大。
这种异构性导致:
集成成本高:企业引入多品牌机器人时,需要开发不同的适配接口,耗时耗力;生态割裂:机器人无法共享数据或协同工作(如工业机器人与AGV无法配合);技术迭代慢:新功能需要针对每个机器人重新开发,无法快速复用。
RCPS的「新基建属性」在于它是一个「统一接口层」——不管是ABB的工业机器人,还是科沃斯的服务机器人,都可以通过RCPS的API接入,实现「一次开发,多机适配」。
技术架构:RCPS的「三层中间件」设计
为了实现「统一接口」,RCPS通常采用「三层中间件」架构(如图1所示):
各层的功能说明:
提示处理层:处理用户的自然语言/多模态输入,完成意图识别(如用BERT);任务编排层:将意图分解为标准化的任务步骤(如用LangChain构建工作流);机器人适配层:将标准化任务转化为具体机器人的控制指令(如调用ABB的RAPID API、发那科的Karel SDK);数据反馈层:收集机器人的执行数据(如抓取成功率、移动时间),反哺提示处理层优化(如调整意图识别的阈值)。
案例:某汽车工厂的「多机器人协同」
某汽车工厂引入了ABB的工业机器人(负责焊接)、埃斯顿的AGV(负责物料运输)、科沃斯的服务机器人(负责巡检)。通过RCPS的统一接口:
工人说「把焊接好的车门运到总装线」,RCPS会自动触发:
ABB机器人完成焊接(调用RAPID API);埃斯顿AGV移动到焊接工位(调用AGV的MQTT接口);ABB机器人将车门放到AGV上(协同动作);AGV将车门运到总装线(路径规划)。
整个过程无需人工干预,协同效率提升了40%。
2.3 维度三:驱动「数据闭环」,实现机器人的「自学习」(进化性)
新基建的核心价值之一是「可持续进化」——通过数据闭环,不断优化自身性能。RCPS的「数据闭环」能力,是机器人从「预编程工具」向「自主智能体」进化的关键。
技术原理:强化学习与提示优化的「结合」
RCPS的数据闭环流程如下:
数据收集:记录用户输入(如「把零件放左边」)、机器人执行结果(如「成功放置,耗时5秒」)、环境反馈(如「零件位置偏移2厘米」);数据标注:用LabelStudio等工具标注「意图-动作-结果」的关联关系;模型训练:用强化学习(RL)优化提示处理模型,让模型学会「根据结果调整提示」(如用户说「放左边」但机器人放偏了,模型会自动将提示优化为「放左边的 conveyor belt 第三个工位」)。
强化学习的核心公式(Q-learning):
sts_tst:当前状态(如用户输入「放左边」,机器人当前位置);ata_tat:当前动作(如机器人移动到左边);rtr_trt:奖励(如成功放置得+10分,失败得-5分);γgammaγ:折扣因子(未来奖励的权重,0<γ<1);Q(st+1,a′)Q(s_{t+1}, a')Q(st+1,a′):下一状态的最大Q值(最优动作的预期奖励)。
案例:某餐饮机器人的「提示优化」
某餐饮机器人公司的RCPS系统,初始时对「倒杯水」的处理是:
移动到饮水机位置;接满一杯水;移动到用户位置;递水。
但实际运行中发现,用户经常抱怨「水太满,容易洒」。通过数据闭环:
系统收集到「递水时洒出」的反馈(r=-5);用强化学习调整提示处理模型,将「倒杯水」优化为「接半杯水,避免洒出」;优化后的提示让洒出率从30%降到了5%。
2.4 维度四:支撑「跨场景泛化」,从工业到服务的「全渗透」(扩展性)
新基建的另一个特征是「跨场景扩展性」——能从一个行业复制到多个行业,支撑全产业的数字化升级。RCPS的「跨场景泛化」能力,让机器人从「工业车间」走进「家庭、医院、商场」。
技术实现:多模态提示与场景适配
跨场景泛化的核心是「多模态提示」——除了自然语言,RCPS还能处理视觉(如用户指向物体)、语音(如语调、语速)、触觉(如用户触摸机器人的手臂)等信号,结合场景上下文(如当前是医院还是商场),生成更准确的动作。
代码示例:多模态提示处理(视觉+语言)
以「拿那个杯子」为例,RCPS需要结合用户的语言(「拿那个杯子」)和视觉(用户手指向桌子上的红色杯子):
import cv2
import torch
from transformers import BertTokenizer, BertModel
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
# 1. 初始化视觉检测模型(Detectron2,用于识别物体)
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
# 2. 初始化语言模型(BERT,用于意图识别)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 3. 多模态提示处理函数
def process_multimodal_prompt(user_input, image_path):
# 步骤1:视觉检测——识别图像中的物体
image = cv2.imread(image_path)
outputs = predictor(image)
instances = outputs["instances"].to("cpu")
# 提取物体类别(如「cup」)和边界框
object_classes = instances.pred_classes.numpy()
object_boxes = instances.pred_boxes.tensor.numpy()
# 假设COCO数据集的「cup」类别ID是41
cup_indices = np.where(object_classes == 41)[0]
if len(cup_indices) == 0:
return "未检测到杯子"
# 步骤2:语言意图识别——理解用户需求
intent = recognize_intent(user_input) # 复用之前的意图识别函数
if intent != "pick_cup":
return "意图不匹配"
# 步骤3:结合视觉与语言——确定目标物体
# 假设用户手指向的位置是(x=200, y=300)(可通过手势识别获取)
user_point = (200, 300)
# 找到包含用户指向位置的杯子边界框
target_cup = None
for idx in cup_indices:
x1, y1, x2, y2 = object_boxes[idx]
if x1 < user_point[0] < x2 and y1 < user_point[1] < y2:
target_cup = idx
break
if target_cup is None:
return "未找到用户指向的杯子"
# 步骤4:生成机器人动作指令
cup_box = object_boxes[target_cup]
# 计算杯子的中心坐标(假设图像分辨率是640x480)
cup_center = ((cup_box[0]+cup_box[2])/2, (cup_box[1]+cup_box[3])/2)
# 转化为机器人的3D坐标(需结合相机标定参数)
robot_target = (cup_center[0]/640*1.0, cup_center[1]/480*0.8, 0.5) # 示例值
return f"机器人动作指令:移动到{robot_target}位置,抓取杯子"
# 4. 测试:用户输入「拿那个杯子」,并上传包含红色杯子的图像
user_input = "拿那个杯子"
image_path = "cup_image.jpg"
result = process_multimodal_prompt(user_input, image_path)
print(result)
运行结果:
机器人动作指令:移动到(0.3125, 0.4375, 0.5)位置,抓取杯子
三、行业深度分析:RCPS的市场价值与应用现状
3.1 当前机器人产业的「三大痛点」
根据Gartner《2024年机器人技术成熟度曲线》,当前机器人产业面临三个核心痛点:
「最后一公里」问题:机器人能完成复杂动作,但无法理解人类的「模糊指令」(如「稍微往左边一点」);「规模化复制」问题:机器人在单一场景(如汽车焊接)表现良好,但无法快速适配新场景(如电子装配);「人机协同」问题:机器人与人类的工作边界模糊,容易发生碰撞或误操作。
3.2 RCPS如何解决这些痛点?
| 痛点 | RCPS的解决方案 |
|---|---|
| 模糊指令理解 | 通过大模型的「语义泛化」能力,将「稍微往左边一点」转化为「x坐标减0.1米」 |
| 规模化复制 | 通过「统一接口层」,让机器人适配新场景只需调整提示库,无需修改底层代码 |
| 人机协同 | 通过「多模态提示」,让机器人理解人类的手势、语调,避免误操作 |
3.3 RCPS的市场渗透情况
根据IDC《2024年全球机器人控制提示系统市场报告》:
2023年全球RCPS市场规模为12亿美元,2024年预计增长至25亿美元(同比增长108%);工业场景是RCPS的主要应用领域(占比60%),其次是服务机器人(25%)和医疗机器人(15%);中国是RCPS的最大市场(占比45%),主要驱动因素是制造业的「机器换人」需求。
3.4 典型案例:RCPS在各行业的应用
案例1:工业制造——某新能源电池工厂
该工厂引入RCPS后,工人无需学习ROS,直接用自然语言调整机器人的焊接参数(如「把焊接电流加5A」),调试时间从4小时缩短到10分钟;机器人的焊接合格率从92%提升到98%。
案例2:服务机器人——某外卖配送机器人公司
该公司的配送机器人用RCPS处理用户的复杂指令(如「把餐放到3号桌的窗边,不要碰到花瓶」),准确率从70%提升到95%;用户投诉率下降了60%。
案例3:医疗机器人——某手术机器人公司
该公司的手术机器人用RCPS让医生用口语指令控制机器人的动作(如「把镊子往左边移2毫米」),手术时间缩短了20%;医生的学习成本从3个月降到了1周。
四、项目实战:搭建一个简易的RCPS系统
接下来,我们用Python和PyBullet(机器人仿真库)搭建一个简易的RCPS系统,实现「用户说「拿杯子」→机器人抓取杯子」的完整流程。
4.1 开发环境搭建
安装Python 3.9+;安装依赖库:
pip install transformers torch pybullet opencv-python detectron2
下载预训练模型:BERT(自动下载)、Detectron2的Mask R-CNN模型(自动下载)。
4.2 系统模块实现
模块1:多模态输入处理(语言+视觉)
复用之前的
process_multimodal_prompt
模块2:任务分解(用LangChain构建工作流)
用LangChain将「拿杯子」分解为步骤:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFacePipeline
# 初始化LLM(用Llama 3的量化版本)
llm = HuggingFacePipeline.from_model_id(
model_id="meta-llama/Llama-3-8B-Instruct",
task="text-generation",
model_kwargs={"temperature": 0.1, "max_length": 200}
)
# 定义任务分解的Prompt模板
prompt_template = """
将用户的机器人控制指令分解为可执行的步骤,要求步骤清晰、具体:
用户指令:{user_input}
步骤:
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["user_input"])
# 构建任务分解链
task_decomposition_chain = LLMChain(llm=llm, prompt=prompt)
# 测试:分解「拿杯子」
user_input = "拿杯子"
steps = task_decomposition_chain.run(user_input)
print("任务分解结果:")
print(steps)
运行结果:
任务分解结果:
1. 激活视觉传感器,识别杯子的位置和姿态;
2. 计算机械臂到杯子位置的逆运动学解;
3. 控制机械臂移动到杯子上方,调整夹爪角度;
4. 闭合夹爪,抓取杯子;
5. 保持夹爪闭合,移动机械臂到目标位置;
6. 打开夹爪,释放杯子。
模块3:动作映射(用PyBullet控制机器人)
用PyBullet仿真KUKA KR210机械臂,执行抓取动作:
import pybullet as p
import pybullet_data
import numpy as np
def control_robot(target_position):
# 连接仿真环境
p.connect(p.GUI)
p.setAdditionalSearchPath(pybullet_data.getDataPath())
# 加载机械臂模型
robot_id = p.loadURDF("kuka_kr210/model.urdf", basePosition=[0,0,0])
num_joints = p.getNumJoints(robot_id)
# 定义目标姿态(用欧拉角转四元数)
target_orientation = p.getQuaternionFromEuler([0, np.pi/2, 0])
# 计算逆运动学解
joint_angles = p.calculateInverseKinematics(
robot_id,
endEffectorLinkIndex=6, # 末端执行器的连杆索引
targetPosition=target_position,
targetOrientation=target_orientation
)
# 控制机械臂移动到目标位置
for i in range(num_joints):
p.setJointMotorControl2(
bodyUniqueId=robot_id,
jointIndex=i,
controlMode=p.POSITION_CONTROL,
targetPosition=joint_angles[i]
)
# 运行仿真
for _ in range(1000):
p.stepSimulation()
# 断开连接
p.disconnect()
# 测试:移动到杯子位置(示例坐标)
target_position = [0.5, 0.0, 0.5]
control_robot(target_position)
模块4:系统整合
将多模态输入、任务分解、动作映射整合为完整流程:
def rcps_pipeline(user_input, image_path):
# 1. 多模态输入处理:获取机器人目标位置
result = process_multimodal_prompt(user_input, image_path)
if "机器人动作指令" not in result:
return result
# 提取目标位置(示例:从字符串中解析)
target_position = eval(result.split(":")[-1].split("位置")[0])
# 2. 任务分解:生成步骤
steps = task_decomposition_chain.run(user_input)
print("任务步骤:")
print(steps)
# 3. 动作映射:控制机器人执行
control_robot(target_position)
return "机器人已执行指令"
# 测试:用户输入「拿那个杯子」,并上传图像
user_input = "拿那个杯子"
image_path = "cup_image.jpg"
result = rcps_pipeline(user_input, image_path)
print(result)
五、未来趋势与挑战
5.1 未来趋势
趋势1:多模态提示的「融合升级」
未来RCPS将支持更丰富的模态:
触觉提示:用户触摸机器人的手臂,机器人理解「轻一点」或「重一点」;表情提示:通过面部识别,机器人理解用户的情绪(如「用户皱眉,说明动作太慢」);环境提示:结合温湿度传感器,机器人调整动作(如「地面湿滑,减慢移动速度」)。
趋势2:个性化提示的「定制化」
RCPS将根据用户的习惯调整提示方式:
老工人喜欢简洁指令(如「左移2厘米」);新工人需要详细步骤(如「先移动到x=0.5米,再调整夹爪角度」);医生需要专业术语(如「将镊子定位到病灶上方2毫米」)。
趋势3:云边协同的「分布式处理」
RCPS将采用「云边协同」架构:
边缘端:处理实时性要求高的任务(如意图识别、动作控制),延迟控制在100ms以内;云端:处理大规模数据训练(如优化提示模型、更新任务库),利用云端的算力优势。
5.2 挑战
挑战1:意图歧义的「消歧」
用户的自然语言往往有歧义(如「打开门」可能是指「推动门」或「控制电动门」),需要结合场景上下文和多模态信号消歧,这需要更强大的上下文理解模型(如GPT-4V、Llama 3 multimodal)。
挑战2:实时性的「优化」
工业机器人需要毫秒级的响应(如焊接机器人的响应时间需<50ms),而大模型的推理时间往往超过100ms,需要通过模型压缩(如量化、蒸馏)和硬件加速(如GPU、NPU)解决。
挑战3:多机器人协同的「同步」
多个机器人执行同一任务时(如组装汽车),需要同步动作(如「机器人A和机器人B同时将部件放到总装线」),这需要分布式提示处理和协同算法(如联邦学习、多智能体强化学习)。
六、工具与资源推荐
6.1 提示工程框架
LangChain:用于构建复杂的提示工作流;LlamaIndex:连接提示系统与知识库,增强上下文理解;PromptLayer:用于跟踪和优化提示的性能。
6.2 机器人仿真与控制
PyBullet:开源机器人仿真库,适合快速原型开发;NVIDIA Isaac Sim:高保真仿真库,支持多机器人和复杂环境;ROS 2:机器人操作系统,用于连接RCPS与实际机器人。
6.3 模型与数据集
BERT:用于文本意图识别;Detectron2:用于视觉物体检测;COCO数据集:用于训练视觉检测模型;RoboSet:机器人任务数据集,包含「意图-动作-结果」的关联数据。
七、结论:RCPS是机器人时代的「数字地基」
回到文章开头的问题:为什么说机器人控制提示系统是「新基建」?
答案藏在三个「底层逻辑」里:
它解决了「人机连接」的核心问题——让普通用户不用学代码就能控制机器人;它支撑了「机器人规模化」的需求——通过统一接口,让机器人快速适配新场景;它驱动了「机器人智能化」的进化——通过数据闭环,让机器人学会「自主优化」。
从工业制造到服务医疗,从工厂车间到家庭客厅,RCPS正在成为机器人时代的「数字地基」——它不是某个企业的「竞争壁垒」,而是整个产业的「公共基础设施」。
对于技术从业者来说,RCPS是一个充满机遇的领域:它需要提示工程、大模型、机器人控制、计算机视觉等多领域的知识融合,也需要解决「歧义消歧」「实时性」「多机器人协同」等挑战性问题。
对于企业来说,RCPS是未来的「核心竞争力」——谁能打造出更易用、更通用、更智能的RCPS,谁就能在机器人时代占据先机。
最后,用一句话总结:机器人控制提示系统不是「附加功能」,而是「机器人时代的Windows系统」——它将重新定义人类与机器人的交互方式,支撑起一个智能、高效、普惠的机器人社会。
参考文献:
《2023年中国工业机器人应用现状白皮书》;Gartner《2024年机器人技术成熟度曲线》;IDC《2024年全球机器人控制提示系统市场报告》;《机器人控制提示系统技术规范》(工业和信息化部);Hugging Face、PyBullet、LangChain官方文档。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...