
前言
hadoop版本:3.3.6。Hadoop官方文档推荐对应的JDK版本为JDK8或JDK11,我用的是JDK11。
一定要注意版本兼容问题,否则后面配置的时候会出现各种问题。
Hadoop官网 https://hadoop.apache.org/ 太慢用官方提供的镜像下载https://downloads.apache.org/hadoop/common/
https://hadoop.apache.org/ 太慢用官方提供的镜像下载https://downloads.apache.org/hadoop/common/
JDK下载【需要登陆才能下】
1. Windows目录介绍【找一个盘符空间大一点的】

software目录下

Virtual Machines目录下新建这三个目录,用于存放创建的虚拟机的位置。
2. 软件准备与安装
软件准备
Centos镜像和VMware Workstation 17 https://pan.baidu.com/s/1owomk-YRdWEpdhSW_v2mgQ?pwd=rmt3
https://pan.baidu.com/s/1owomk-YRdWEpdhSW_v2mgQ?pwd=rmt3

安装
VMware Workstation Pro安装【这部分由于平台限制可以看我的飞书文档】
下载并安装好VMware Workstation虚拟软件工具,安装成功后打开VMware Workstation工具,进入VMware Workstation主界面。
一、准备集群环境
1. 创建一台安装Linux操作系统的虚拟机Hadoop1;
安装虚拟机
1. 点击创建虚拟机,然后选择自定义(高级)

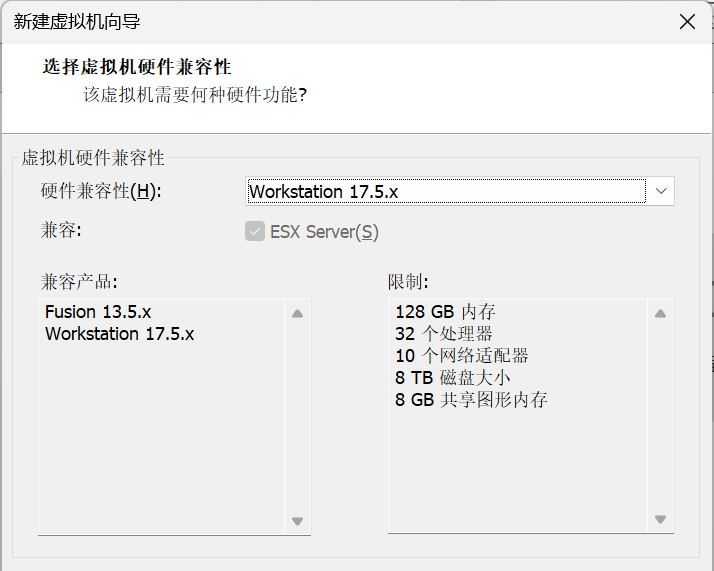
2. 在选择虚拟机硬件兼容性界面,选择硬件兼容性为Workstation 17.5.x(一般默认就可以,它会自动识别)
3. 在安装客户机操作系统界面,选择安装来源为稍后安装操作系统。
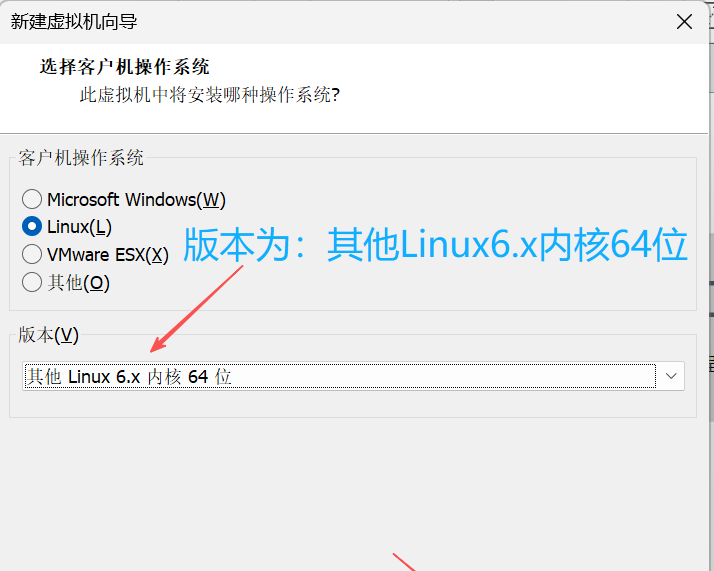
4. 在选择客户机操作系统界面,选择客户机操作系统为Linux。
5. 在命名虚拟机界面,将虚拟机名称填写为Hadoop1。
注:位置是虚拟机本地的存储位置,这就是为什么你创建的虚拟机的配置也有限制的一个原因,因为它实际上还是用本地计算机的硬件设施,只是它有一个“超分”机制,使得它表面上看起来能使用更多的资源。
【这个属于全虚拟化。全虚拟化的特点是虚拟机完全模拟底层硬件,客户操作系统无需进行修改就能够直接运行 。VMware 通过二进制翻译(BT,Binary Translation)和直接执行的模式来达成全虚拟化,可对任何基于 x86 的操作系统进行虚拟化 。同时,自 VMware Workstation 6.0 版本开始,其引入了如 Intel 的 VT-x 和 AMD 的 AMD-V 等硬件辅助虚拟化技术,用于对全虚拟化进行优化,让性能得以提升 。】
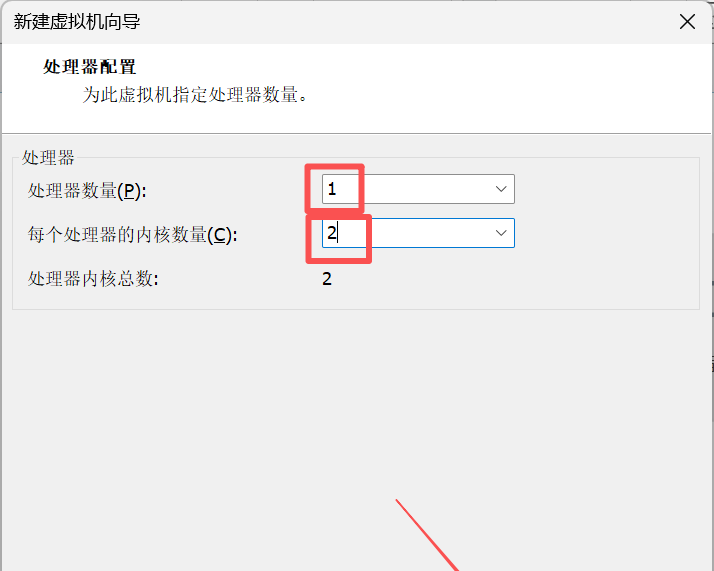
6. 在处理器配置界面,处理数量选择为1,每个处理器的内核数量设置为2。
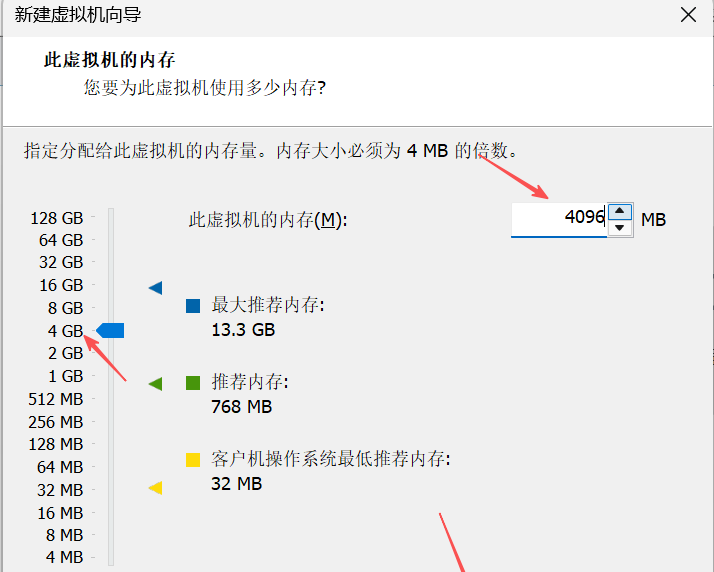
7. 在此虚拟机的内存界面,将此虚拟机的内存设置为4096MB(就是4GB,1GB=1024MB)。
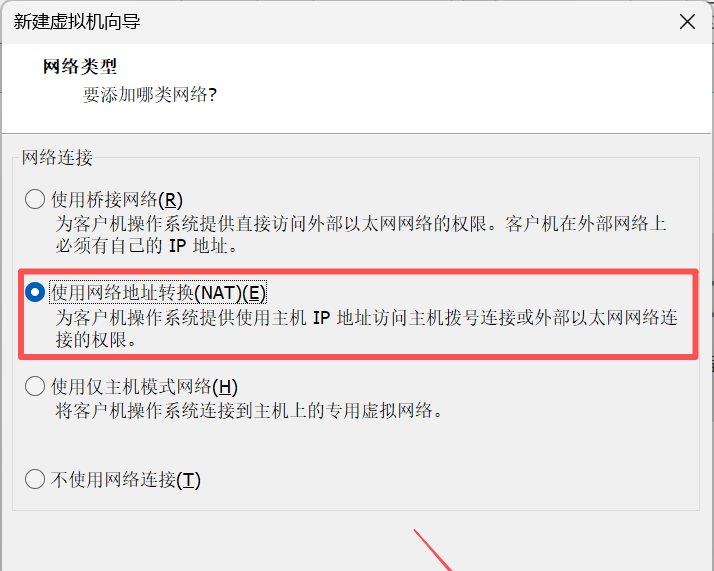
8. 在网络类型界面,选择网络连接为使用网络地址转换(NAT)。
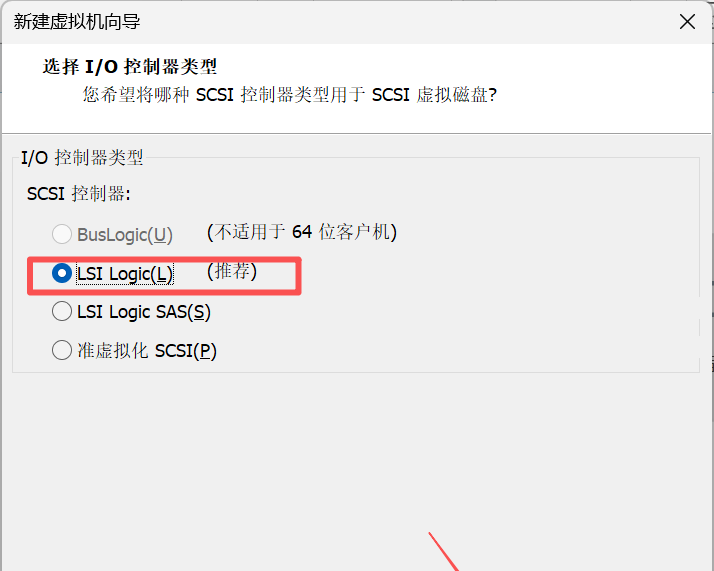
9. 在选择I/O控制器类型界面,选择I/0控制器类型为LSILogic。
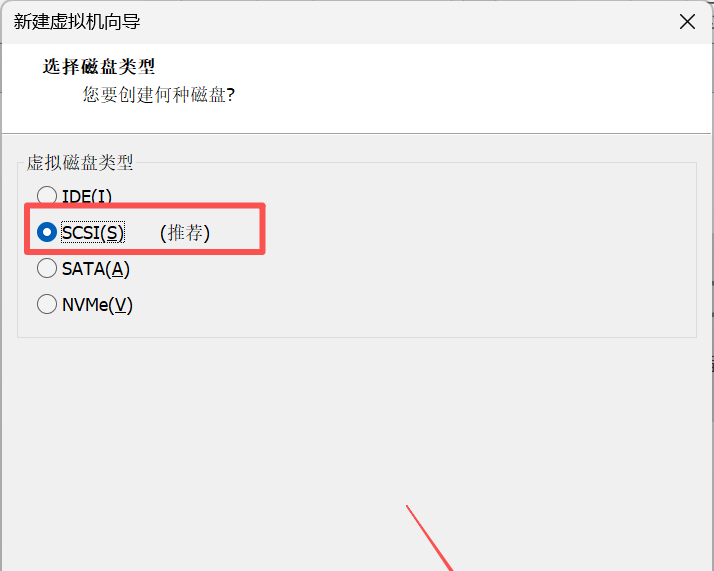
10. 在选择磁盘类型界面,选择虚拟磁盘类型为SCSI(是一种系统级别的接口标准。特点:支持多设备连接,数据传输速度较快,可靠性高)。
11. 在选择磁盘界面,选择磁盘为创建新虚拟磁盘。
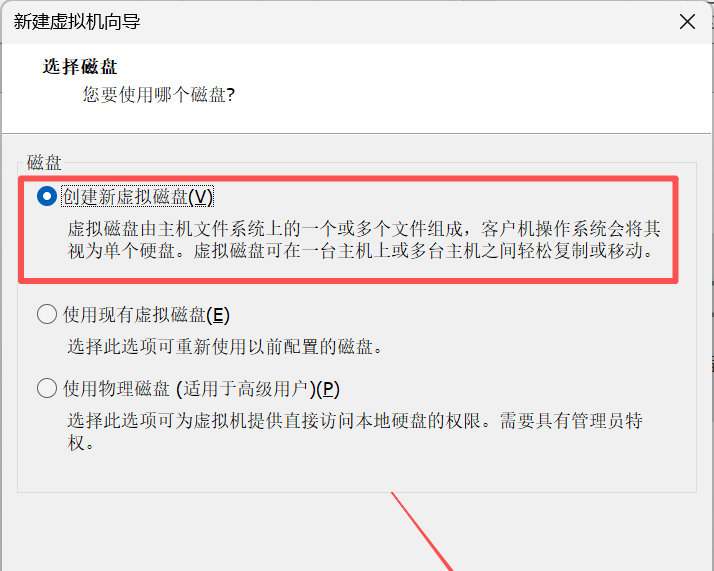
说明:
创建新虚拟磁盘
特点:虚拟磁盘由主机文件系统上的一个或多个文件组成。
使用现有虚拟磁盘
特点:可重新使用以前配置的磁盘。
使用物理磁盘(适用于高级用户)
特点:可为虚拟机提供直接访问本地硬盘的权限。
12. 在指定磁盘容量界面,将最大磁盘大小设置为30.0。
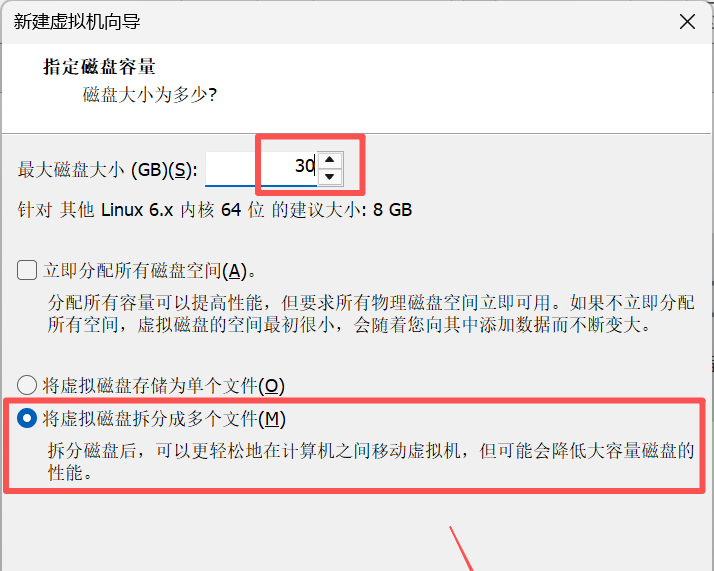
说明:
立即分配所有磁盘空间(A)
特点:会立即从物理磁盘中分配所设置的最大磁盘容量,虚拟磁盘性能会提高,但需要物理磁盘有足够的立即可用空间(要求也高)。
将虚拟磁盘存储为单个文件(O)
特点:虚拟磁盘以一个单独的文件形式存储在主机文件系统中,管理简单。
将虚拟磁盘拆分成多个文件(M)
特点:虚拟磁盘会被拆分成多个文件存储,但是性能会大大降低。适合经常移动虚拟机、复制虚拟机使用。
13. 在指定磁盘文件界面,将磁盘文件命名为Hadoop1.vmdk。
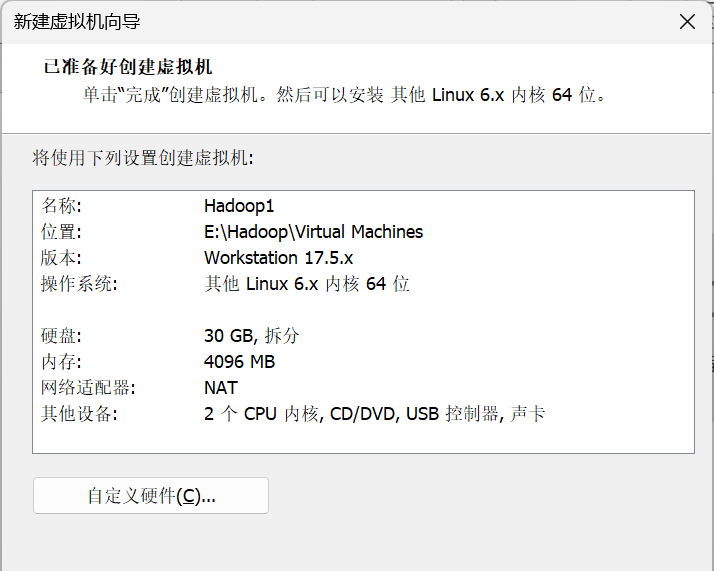
14. 在已准备好创建虚拟机界面,可以查看虚拟机的相关配置参数。
15. 虚拟机Hadoop1创建完成后的效果。
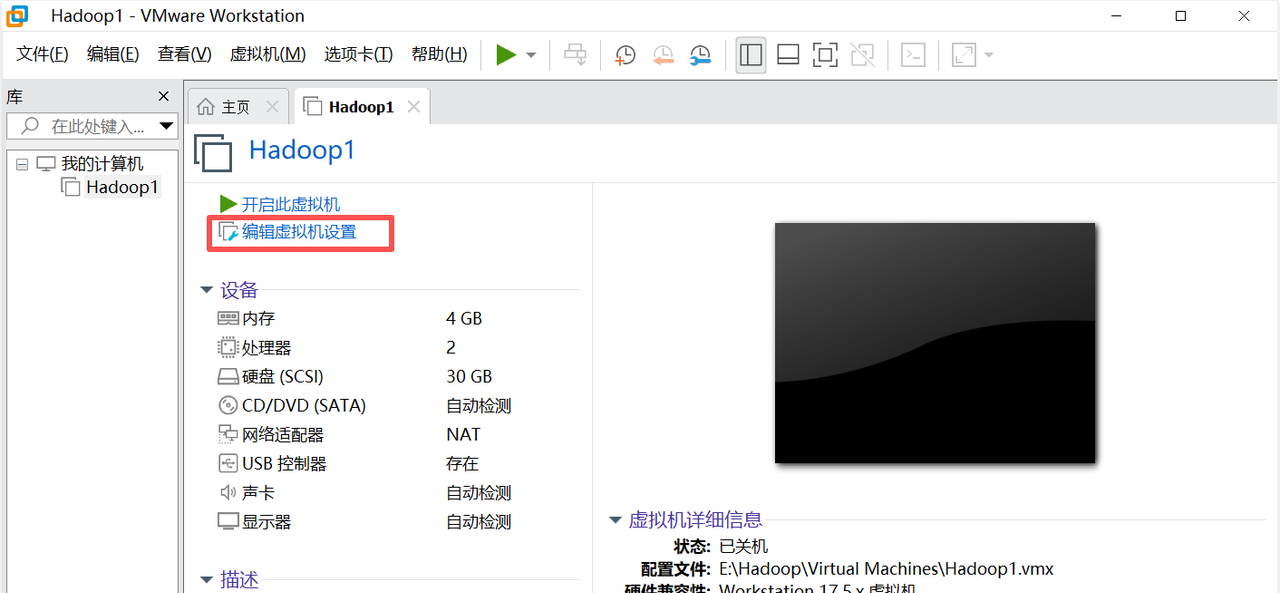
在虚拟机中安装Linux操作系统
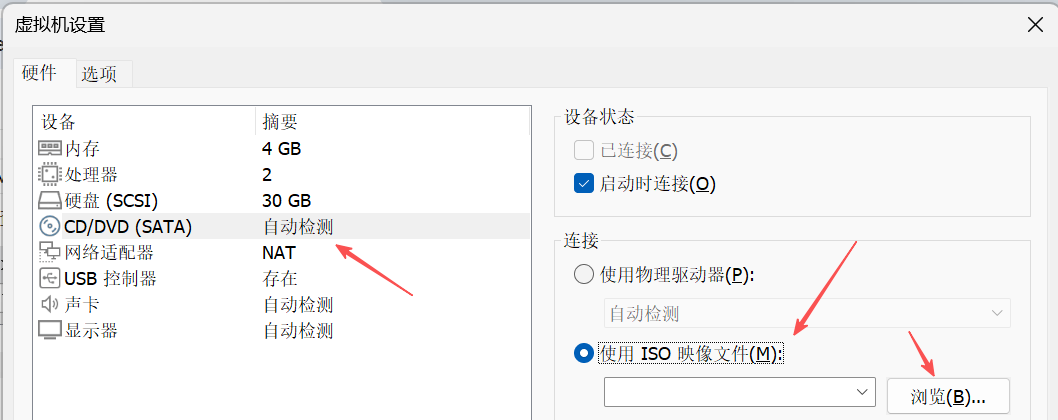
1. 在虚拟机设置对话框,勾选使用ISO镜像文件。
2. 去到之前的Hadoop目录下的SolftWare目录下的CentOS_9目录下选择CentOS-Stream-9-latest-x86 64-dvd1.iso镜像文件打开。
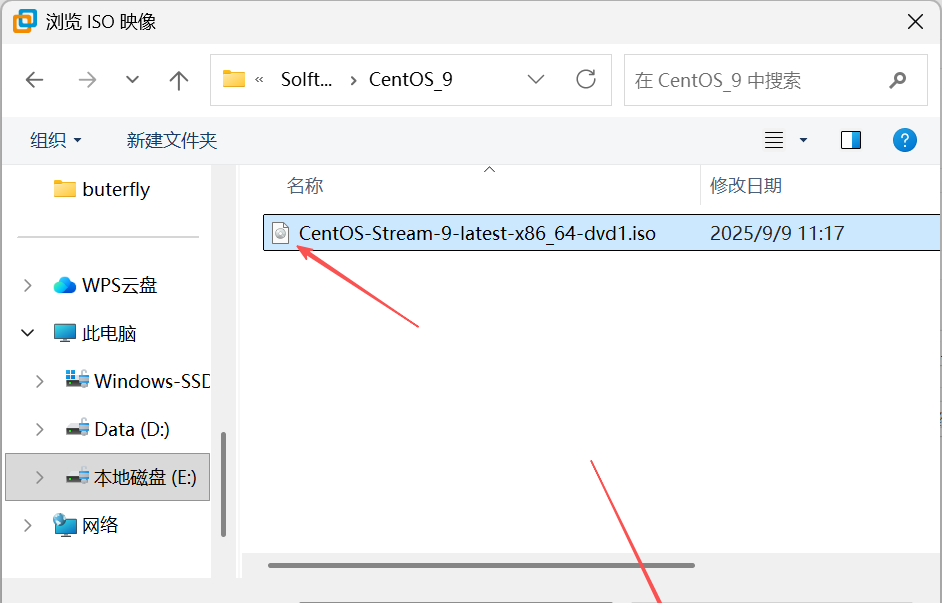
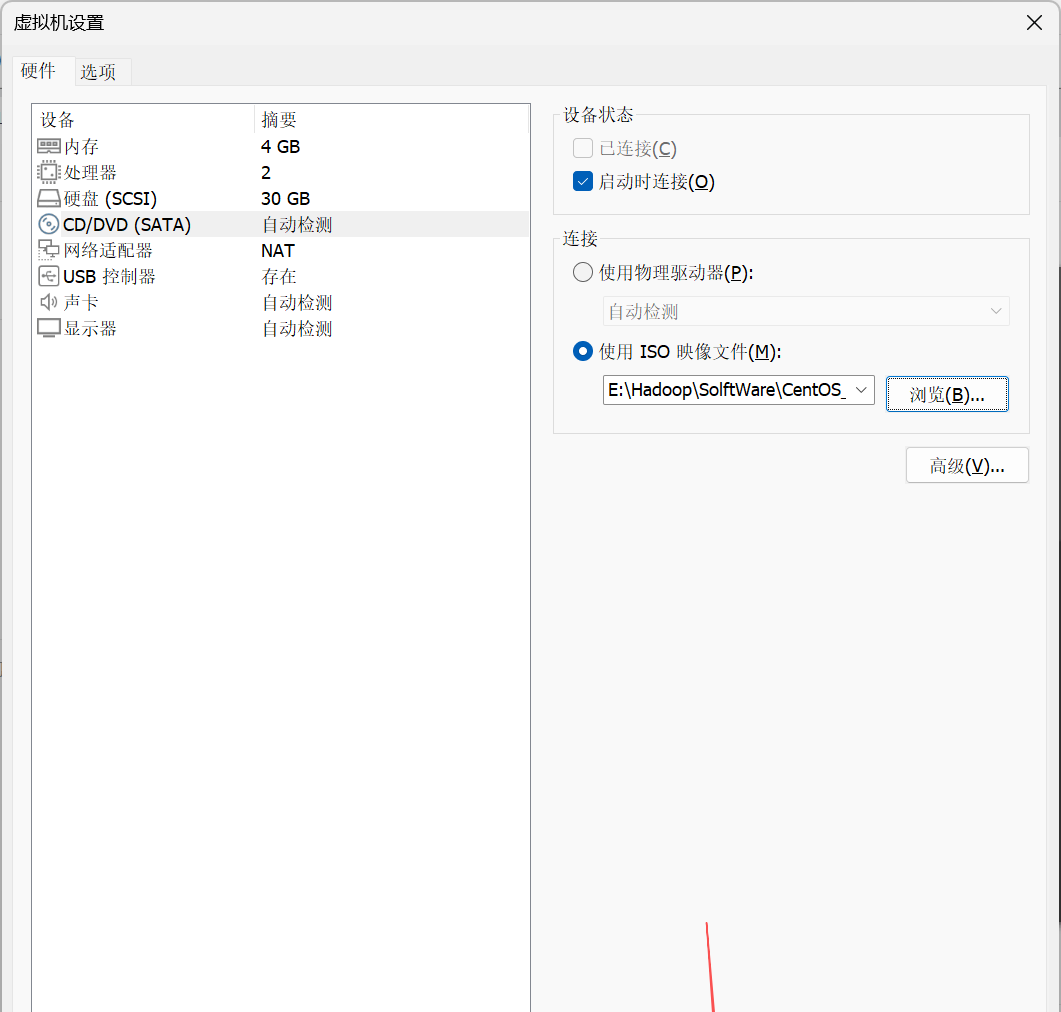
注明:
CentOS-Stream-9-latest-x86 64-dvd1.iso是用于安装、恢复 CentOS Stream 9 操作系统,以及进行软件测试的镜像文件,包含系统运行所需的全部组件,可通过引导、复制文件等过程完成系统部署与使用。
3. 回到主界面启动虚拟机Hadoop1,初次启动虚拟机Hadoop1之后会进入CentOS Stream 9的安装引导界面。

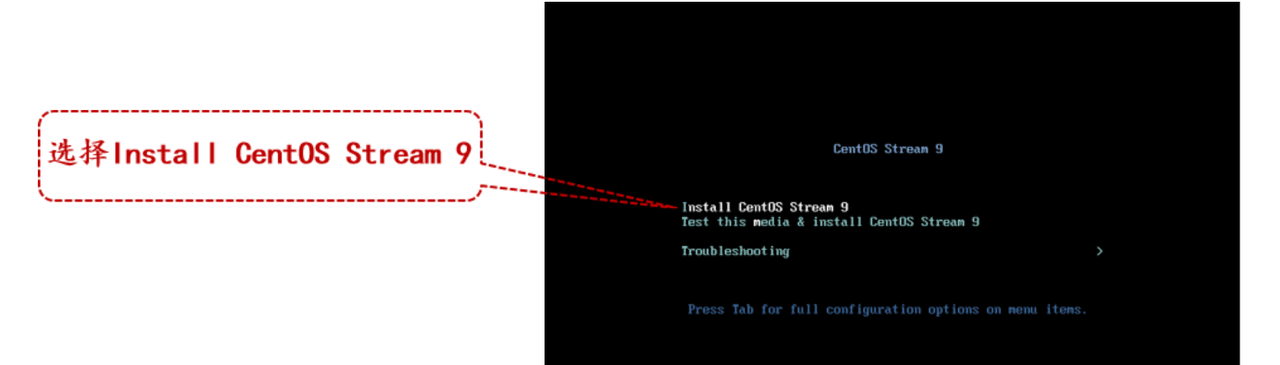
注明:选择的时候按上下键选择。
注明:系统初始化服务并完成各项启动前的准备工作。
4. 在欢迎使用CENTOS STREAM 9界面,选择用简体中文(中国)做为 CentOs Stream 9 操作系统的语言。
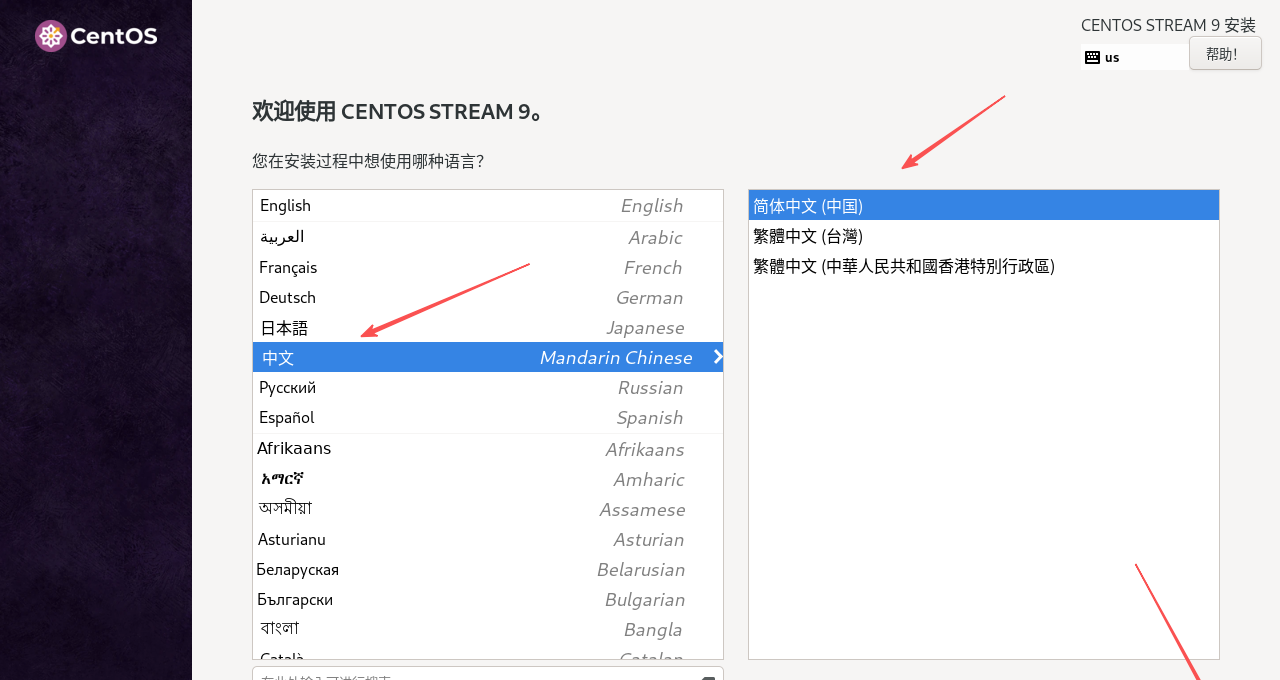
5. 在安装信息摘要界面,可以修改CentOs Stream 9的相关配置。
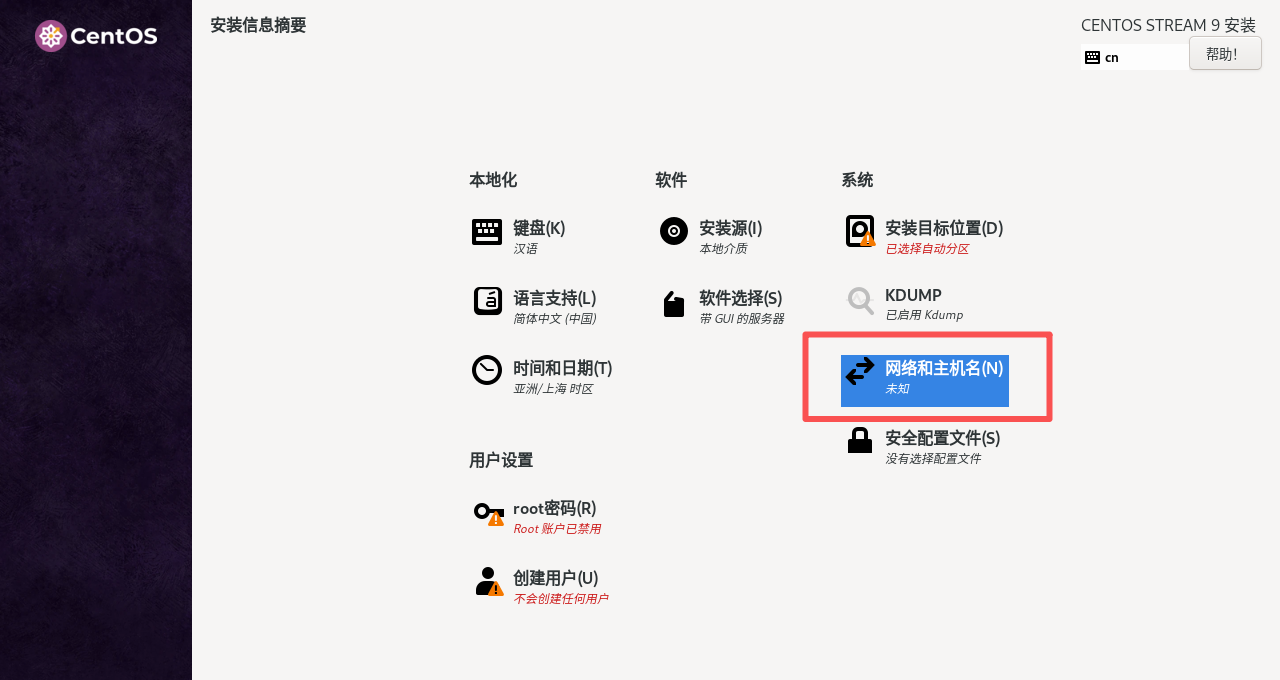
6. 在网络和主机名界面,确认以太网(ens33)为打开状态。改好后点击应用,再点击完成。
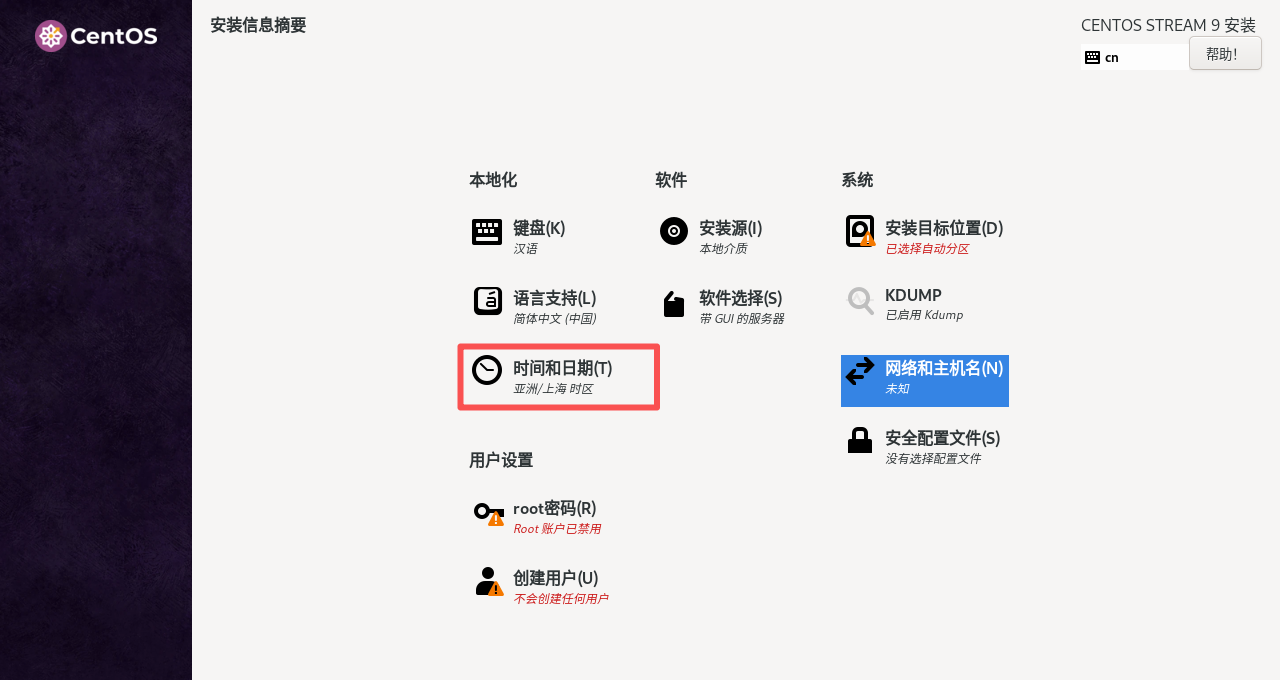
7. 在时间和日期界面,确认“地区”和“城市”分别为“亚洲”和“上海”,然后点击完成。

注明:这里的网络时间(就是同步时间)点击不了是因为我们之前的网络没有配置(网络连接问题),所以点不了,但是没关系,后面到这里弄。
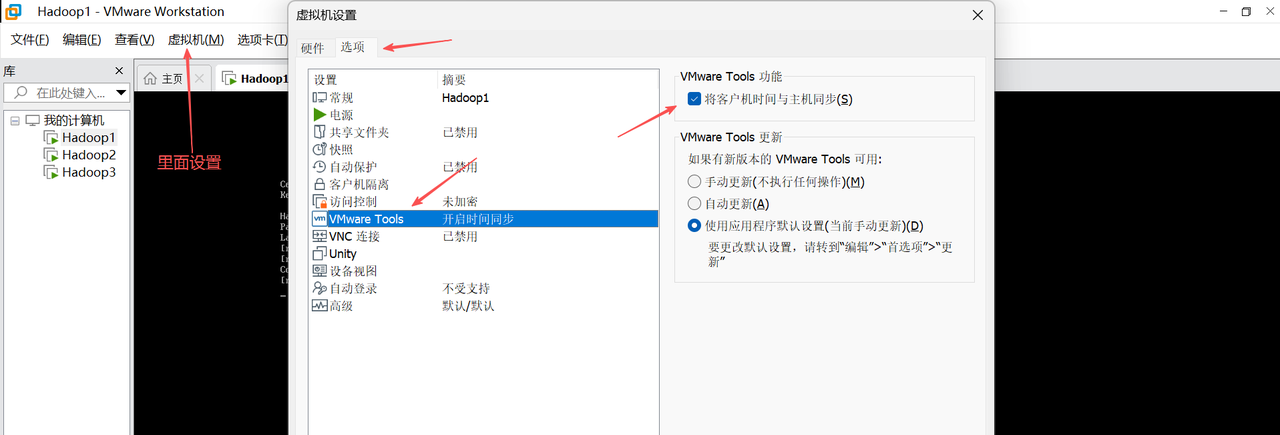
8. 在安装目标位置界面配置CentOS Stream 9的磁盘分区,选择存储配置为自动,点击完成。
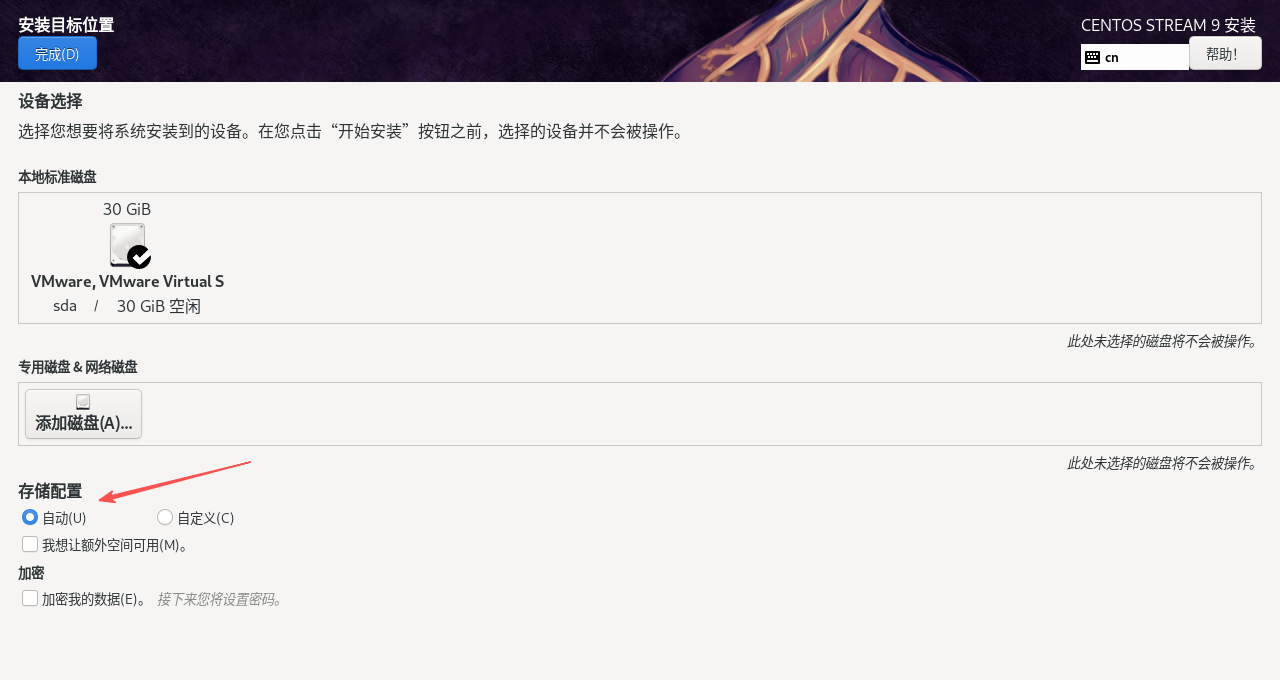
9. 在软件选择界面配置CentOS Stream 9的基本环境,选择基本环境为Minima Install,即最小化安装,点击完成。
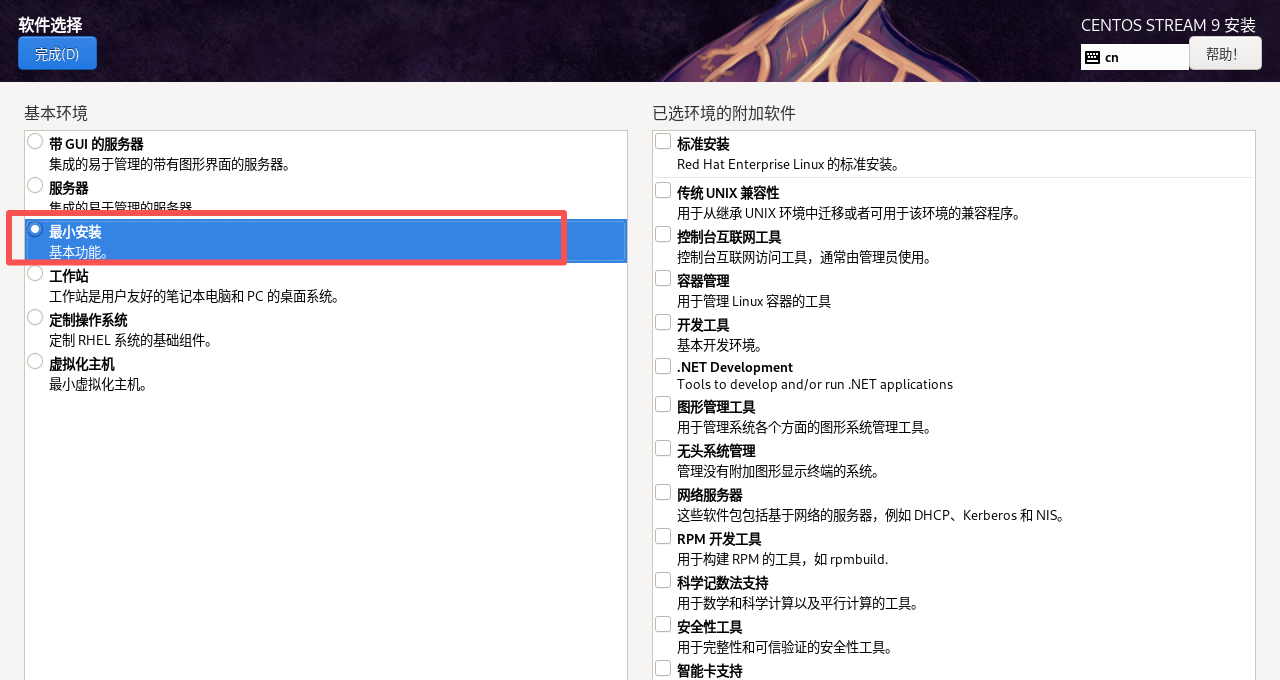
注明:最小安装是仅选取操作系统运行所需的最基础软件包进行安装的方式。
10. 在ROOT密码界面,配置用户root的密码。
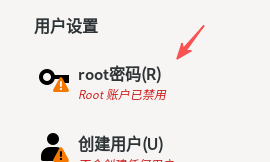

注意:这里root密码填写完后,用户也就创建了,也就是root用户。
11. 安装进度
在安装进度界面开始安装CentOS Stream 9。
注明:
架构区分的关键本质:操作系统与硬件的 “指令交互桥梁”,不同架构 CPU 的指令集(如 X86 的复杂指令集 CISC、ARM/RISC-V 的精简指令集 RISC)不同,操作系统需针对性编译内核与驱动,才能实现硬件控制、功能运行,跨架构直接运行系统会因指令不兼容导致失败。
基于 X86 架构操作系统的典型特征:广泛适配个人电脑(PC)、主流服务器,支持复杂的多任务处理、图形化界面,常见系统包括 Windows(如 Windows 10/11)、Linux(如 CentOS、Ubuntu 的 x86_64 版本)、macOS(仅适配 Apple 搭载 Intel 芯片的 Mac 设备);
ARM 架构,核心特点是低功耗、高能效比,广泛用于移动设备(手机、平板)、嵌入式设备(智能手表、路由器)、部分轻量级笔记本 / 服务器,适配的操作系统包括 Android(手机端主流)、iOS(苹果手机 / 平板专属)、ARM 版 Windows(如 Windows 11 on ARM)、ARM 版 Linux(如 Ubuntu Server for ARM);
RISC-V 架构,核心特点是开源、可定制化,无需支付架构授权费用,适用于嵌入式设备(传感器、物联网终端)、边缘计算设备、部分高性能计算场景,适配的操作系统包括 RISC-V 版 Linux(如 Fedora RISC-V、Debian RISC-V)、RISC-V 版 FreeBSD 等,目前处于快速发展阶段,生态逐步完善;
Power 架构,核心特点是高性能、高稳定性,主要用于企业级服务器、大型机、高性能计算(HPC)领域,适配的操作系统包括 AIX(IBM 专属 Unix 系统)、PowerLinux(基于 Linux 的 Power 架构版本)、IBM i(IBM 小型机专属系统);
MIPS 架构,核心特点是指令集精简、成本低,早期广泛用于路由器、机顶盒等嵌入式设备,目前在部分物联网设备、工业控制设备中仍有应用,适配的操作系统包括 MIPS 版 Linux(如 OpenWrt 的 MIPS 版本)、VxWorks(实时操作系统)。
待CentOS Stream 9安装完成后,单击重启系统按钮开始使用CentOS Stream 9。
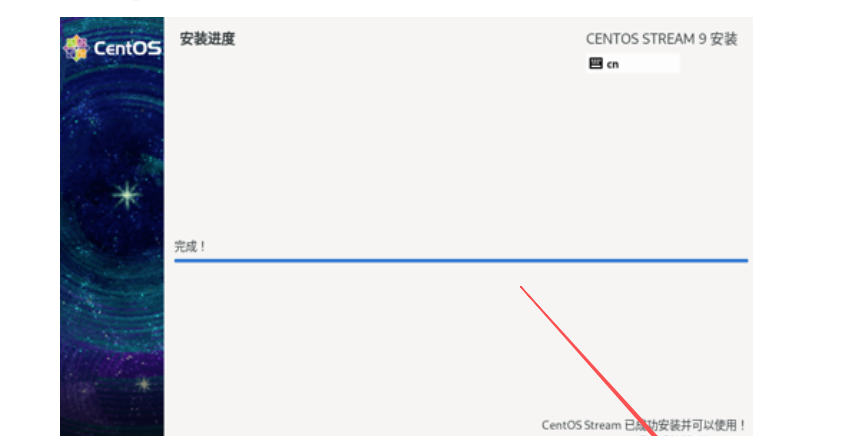
12. 虚拟机Hadoop1的登录界面:待重启完成后会进入虚拟机Hadoop1的登录界面,输入用户名和密码,然后按enter即可登录虚拟机Hadoop1。

2. 基于已创建的虚拟机,通过克隆的方式创建另外两台虚拟机Hadoop2和Hadoop3
1. 关闭虚拟机:点击右上角的“虚拟机”->“电源”->“关闭客户机”即可实现关闭虚拟机。如果跳出以下这个,点击关机即可,如果嫌麻烦,可以点击不再显示此消息,下次就不会出现了

然后就变成这个样子了。
2. 在VMware Workstation的主界面选择并右击虚拟机Hadoop1,依次选择“管理”->“克隆”选项进入欢迎使用克隆虚拟机向导界面。

3. 在克隆源界面,选择虚拟机中的当前状态。

4. 在克隆类型界面,选择选择克隆方法为创建完整克隆。
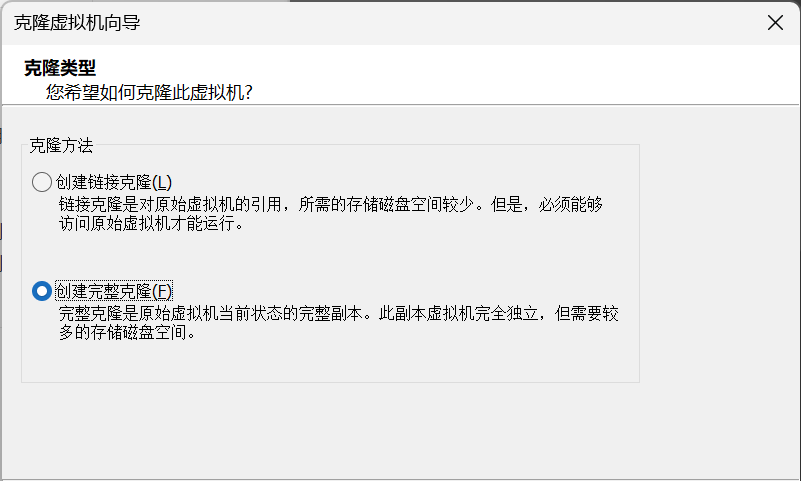
注明:
创建链接克隆:基于对原始虚拟机的引用,所需存储磁盘空间少,但必须能访问原始虚拟机才能运行(原始虚拟机不一定要开机,但是一定得保持存在并能被克隆虚拟机访问)。
创建完整克隆:是原始虚拟机当前状态的完整副本,副本虚拟机完全独立,但需要较多的存储磁盘空间。
5. 在“新虚拟机名称”界面,自定义虚拟机名称和虚拟机存储位置。
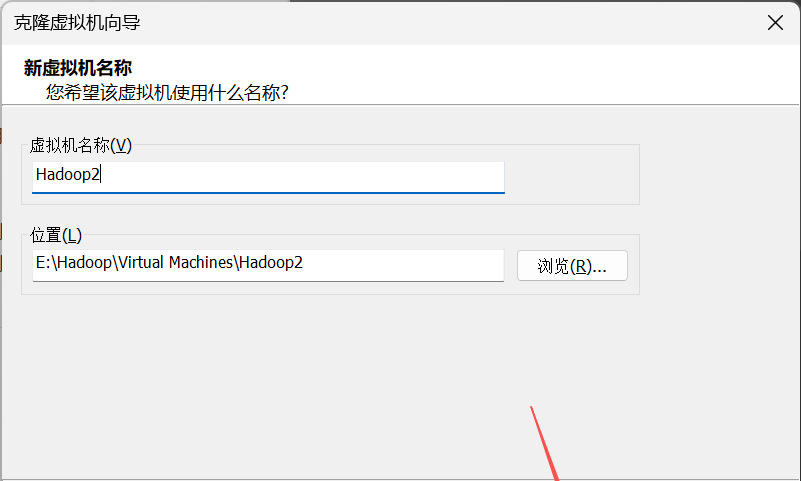
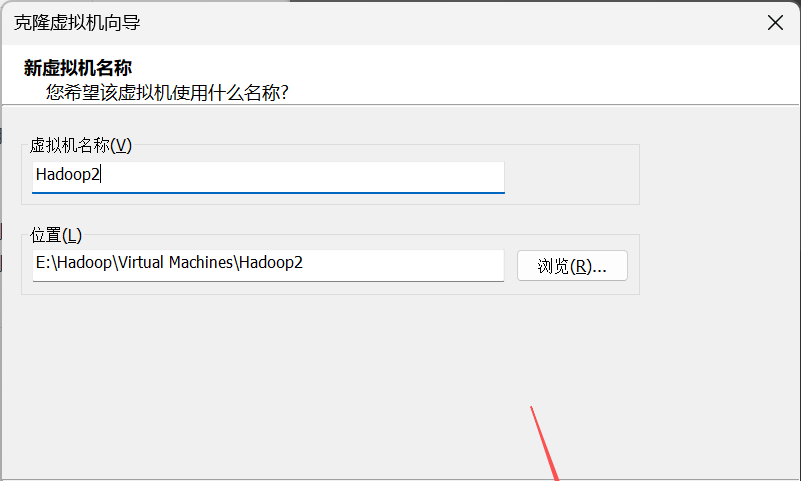
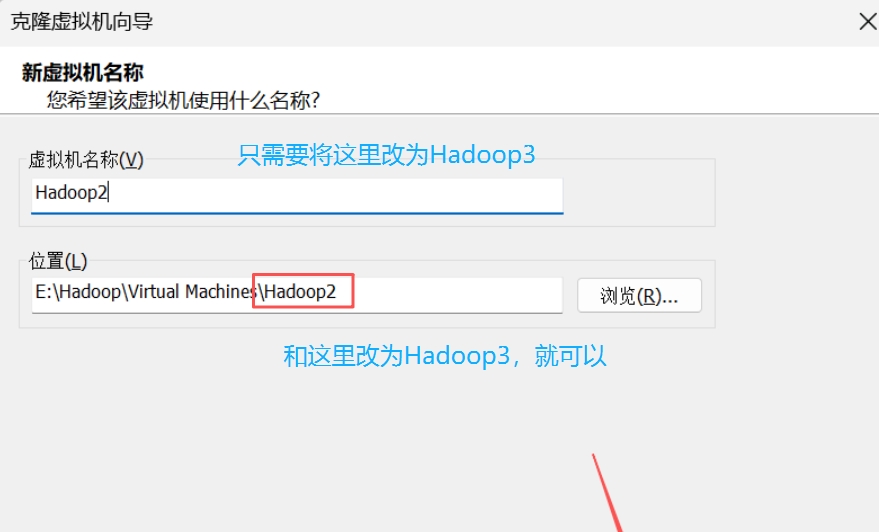
6. 第三台虚拟机Hadoop3也是一样,只是在虚拟机名称和位置这里改一下就行。
## 3. 配置虚拟机
配置3台虚拟机的主机名和IP映射、配置网络参数、配置SSH远程登录、配置免密登录功能
3.1 配置虚拟机主机名和IP映射。
1. 修改主机名
分别将虚拟机Hadoop2和Hadoop3的主机名修改为hadoop2和hadoop3。
hostnamectl set-hostname Hadoop2
hostnamectl set-hostname Hadoop3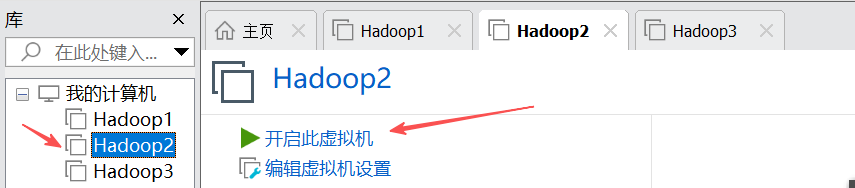
因为是克隆,这些都是一样的(包括用户名(根用户,都一样的:root)和密码:123),所以我们才需要改一下主机名,用户名和密码不用改。
在Hadoop2上执行以下命令:hostnamectl set-hostname Hadoop2

在Hadoop3上执行以下命令:hostnamectl set-hostname Hadoop3

注意:重启之后才会生效。使用命令reboot,按enter键之后即可实现重启。Hadoop2和Hadoop3都要做。

2. 配置VMware Workstation网络
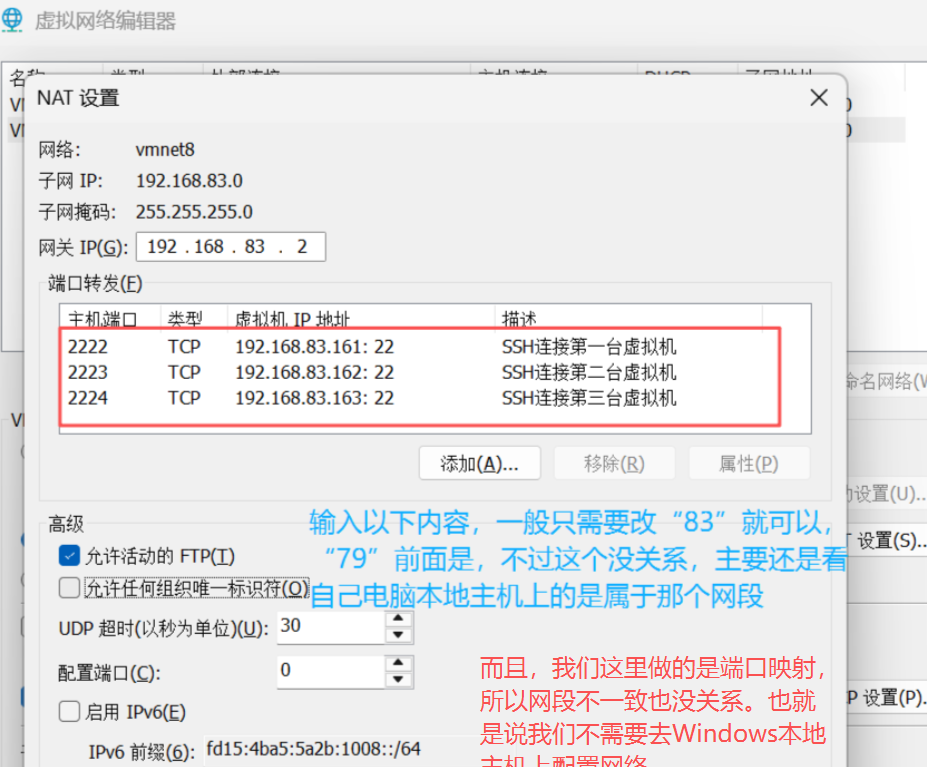
在VMware Workstation主界面,依次单击“编辑”->“虚拟网络编辑器”选项,配置VMware Workstation网络。
注意:Hadoop1、Hadoop2和Hadoop3都要做一遍。
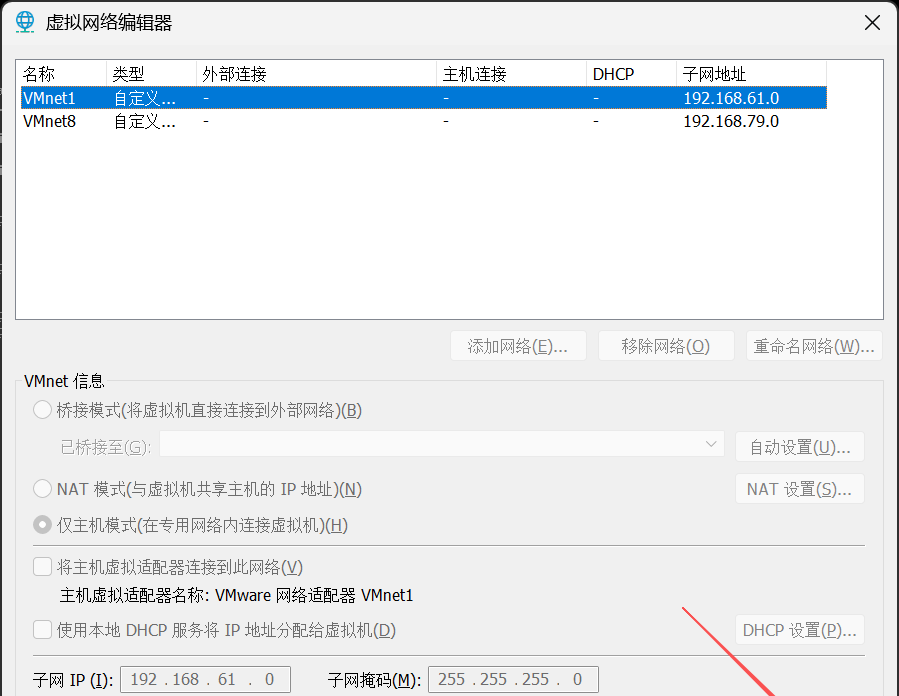
进去之后点击“更改设置”,有弹框跳出来就选择是,进入可编辑权限。
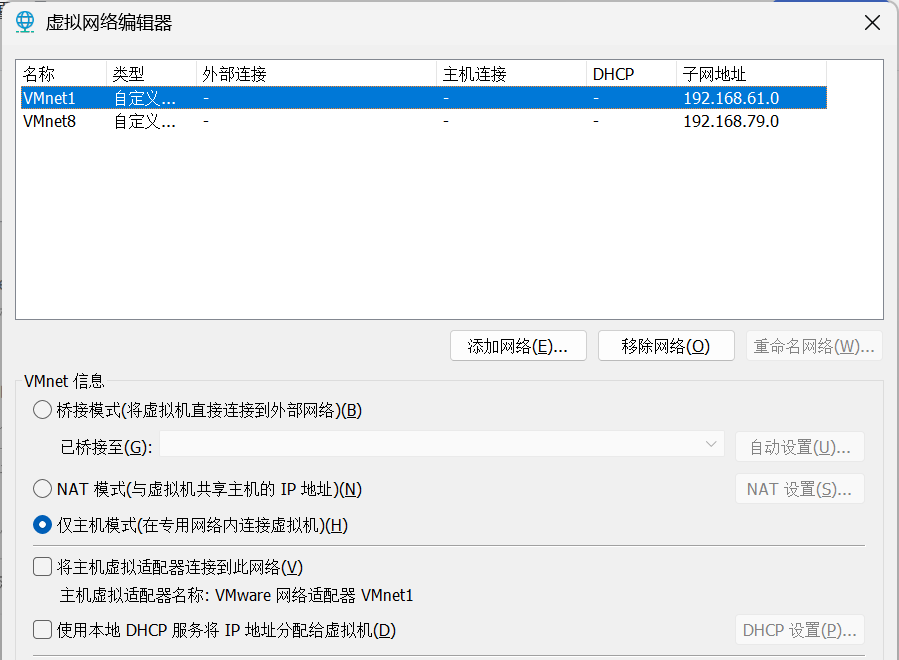
点击VMnet8—NAT模式,按照以下勾选。
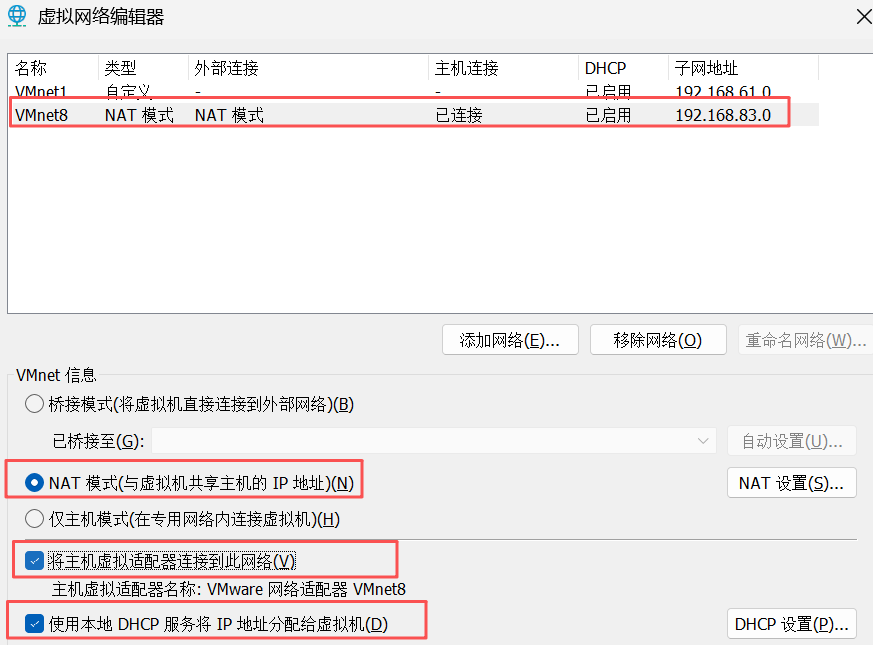
说明:
NAT 模式 (与虚拟机共享主机的 IP 地址)(N)
特点:虚拟机借助主机的网络连接访问外部网络,默认情况下外部网络无法直接访问虚拟机(需手动配置端口映射才能实现)。主机相当于一个网关,负责转发虚拟机与外部网络的通信数据。
将主机虚拟适配器连接到此网络 (V)
特点:把主机上的虚拟网络适配器(这里是 VMware 网络适配器 VMnet8)和当前配置的虚拟网络(VMnet8 对应的网络)连接起来。
使用本地 DHCP 服务将 IP 地址分配给虚拟机 (D)
特点:开启 VMware 自带的 DHCP(动态主机配置协议)服务,由该服务自动为连接到该虚拟网络的虚拟机分配 IP 地址。
子网 IP (I): 192.168.83.0
特点:定义了当前虚拟网络(VMnet8)所在的子网网段,表示该虚拟网络中的设备都处于 192.168.79.0/24 这个子网范围内(结合子网掩码 255.255.255.0 来看)。
3. 修改映射文件
分别在虚拟机Hadoop1、Hadoop2和Hadoop3执行 vi /etc/hosts 命令编辑映射文件hosts。
输入以下内容:
vi/etc/hosts
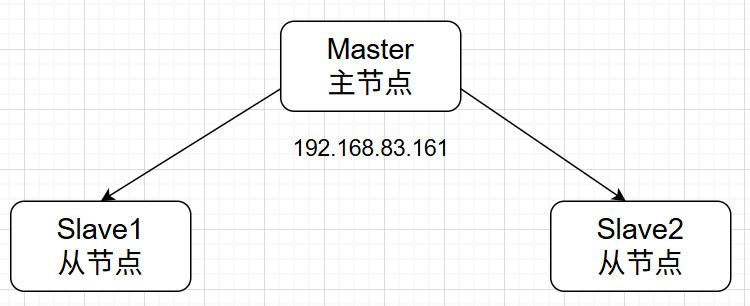
192.168.83.161 Hadoop1
192.168.83.162 Hadoop2
192.168.83.163 Hadoop3注意:
执行命令前得先启动虚拟机,三台都要并登录。
把里面原来的东西都清除掉。


3.2 配置虚拟机的网络参数
1. 分别编辑虚拟机Hadoop1、Hadoop2、Hadoop3的网络配置文件ens33.nmconnection。
# 没台虚拟机都要使用这个命令才能进入编辑
vi /etc/NetworkManager/system-connections/ens33.nmconnection
2. 修改网络配置文件中[ipv4]下方参数method的值为manual,表示使用静态IP。在[ipv4]下方添加参数address1和dns,参数address1用于指定IP地址和网关参数dns用于指定域名解析器。
# Hadoop1
address1=192.168.83.161/24,192.168.83.2
dns=114.114.114.114
# Hadoop2
address1=192.168.83.162/24,192.168.83.2
dns=114.114.114.114
# Hadoop3
address1=192.168.83.163/24,192.168.83.2
dns=114.114.114.114Hadoop1

Hadoop2
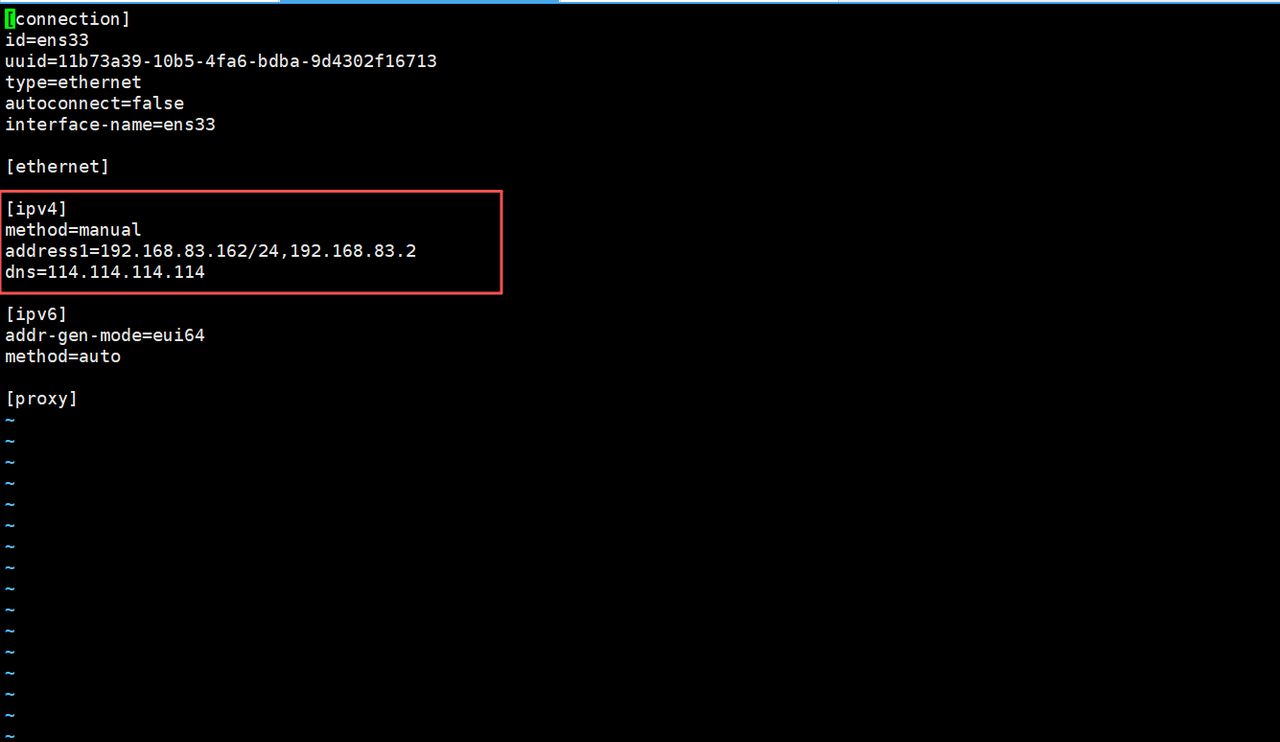
Hadoop3

3. 修改虚拟机Hadoop2和Hadoop3[只针对他俩进行设置就可以]的uuid,uuid的作用是使分布式系统中的所有元素都有唯一的标识码。
sed -i "/uuid=/cuuid=`uuidgen`" /etc/NetworkManager/system-connections/ens33.nmconnection
# 或者
sed -i "/uuid=/cuuid=$(uuidgen)" /etc/NetworkManager/system-connections/ens33.nmconnection4. 分别在虚拟机Hadoop1、Hadoop2、Hadoop3中执行“nmclic reload”命令重新加载网络配置文件,以及执行“nmcli c up ens33”命令重启ens33网卡,使修改后的网络配置文件生效。id a命令查看网络配置是否生效。
nmcli c reload # 重新加载网络配置文件
nmcli c up ens33 # 重启网卡
ip a # 查看是否生效,出现以下内容即生效Hadoop1
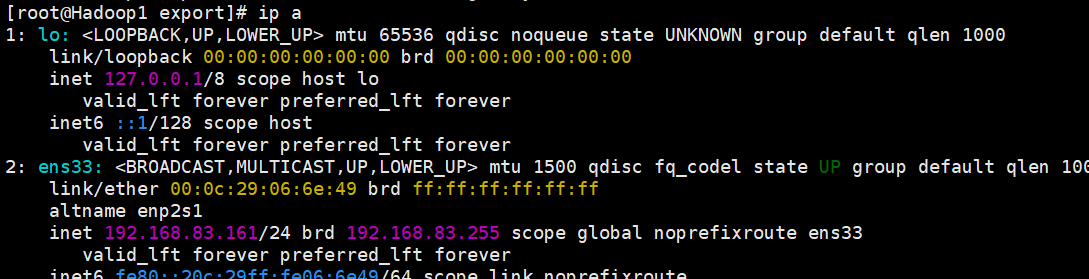
Hadoop2
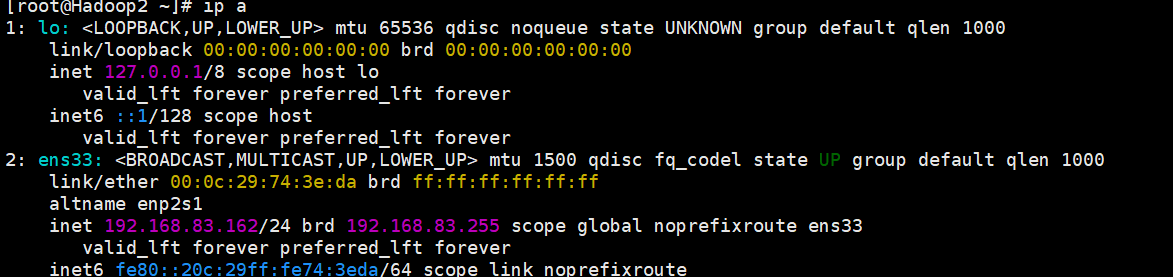
Hadoop3
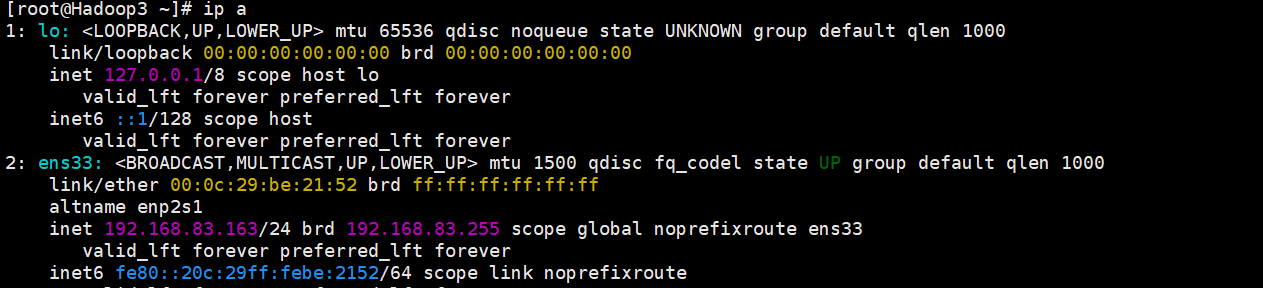
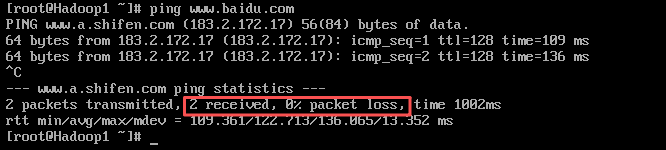
5. 检测网络连接
保证个人计算机连网状态,分别对Hadoop1、Hadoop2、Hadoop3执行“ping www.baidu.com”命令,检测虚拟机的网络连接是否正常,检测完成后可以通过组合键“Ctrl +C”退出检测。
Hadoop1
Hadoop2

Hadoop3
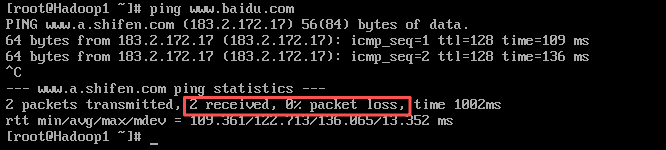
都完全接收,丢包率都为0,即没问题。
3.3 配置虚拟机SSH远程登录【Hadoop1、Hadoop2、Hadoop3都要弄,操作是一样的】
1. 查看是否安装和开启SSH服务在虚拟机中,分别执行“rpm -qa l grep ssh”和“ps -ef | grep sshd”命令,查看当前虚拟机是否安装了SSH服务,以及SSH服务是否启动。
rpm -qa l grep ssh #检查是否安装了SSH服务
ps -ef | grep sshd #检查SSH服务是否启动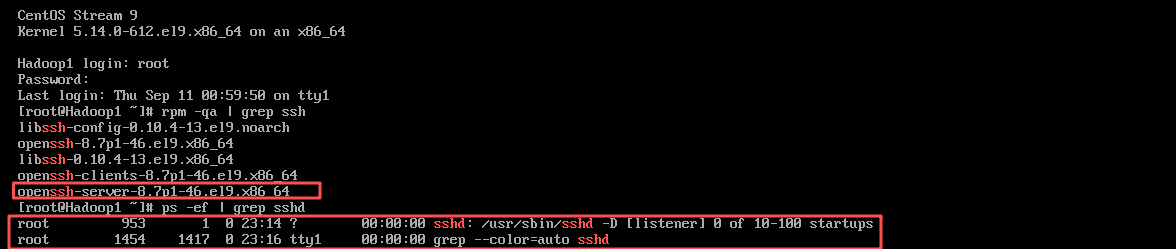
systemctl status sshd # 查看ssh服务的状态
systemctl enable sshd # 设置开机自启ssh服务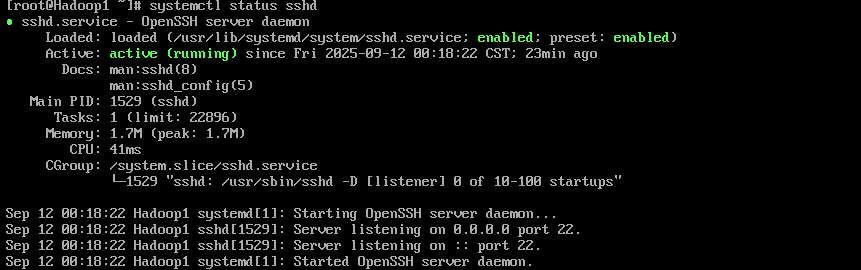
扩展:
管道(
)的作用是将前一个命令的输出,作为后一个命令的输入,实现 “多命令协作过滤 / 处理数据” 的效果。
|
:查询系统已安装的所有软件包
rpm -qa
:是 Red Hat Package Manager(红帽软件包管理器)的缩写,用于管理 Linux 系统(如 CentOS、RHEL 等)的软件包(安装、查询、卸载等)。
rpm
:
-q的缩写,代表 “查询” 模式。
query
:
-a的缩写,代表 “所有”。
all组合起来,
的作用是列出系统中已经安装的所有软件包(会输出大量软件包名称,格式通常为
rpm -qa)。
软件包名-版本号-发布号.架构
:筛选包含 “ssh” 的行
grep ssh
:是文本过滤工具,用于在输入的文本中查找匹配指定 “模式”(这里是字符串
grep)的行。
ssh
:查看系统中所有进程
ps -ef
:是 Process Status(进程状态)的缩写,用于查看系统中的进程信息。
ps
:
-e的缩写,代表 “所有进程”(等同于
every)。
-A
:
-f的缩写,代表 “完整格式”,会输出进程的用户、PID(进程 ID)、父进程 ID、启动时间、命令路径等详细信息。
full format组合起来,
的作用是列出系统中所有进程的详细信息。
ps -ef
2. 修改SSH服务配置文件
默认情况下,CentOS Stream 9不允许用户root进行远程登录,在虚拟机Hadoop2中执行“vi/etc/ssh/sshd_config”命令编辑配置文件sshd_config。
vi/etc/ssh/sshd_config #修改ssh配置文件
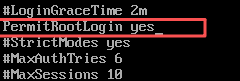
注意:改了之后按”esc”->”:”输入”wq”,再按enter键即可实现保存退出。
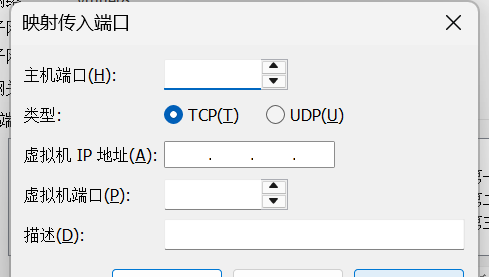
3. 然后点击编辑->虚拟网络编辑器->更改设置->NAT模式->NAT设置->端口转发->添加。
添加步骤如下:
主机端口:选择一个未被占用的主机端口,比如
2222
# 验证端口是否被占用命令(在Windows命令行上)
# 如:netstat -ano | findstr ":2222"
# 如果没有任何输出即可证明没有被占用
netstat -ano | findstr ":目标端口号" 类型:选择
TCP
虚拟机 IP 地址:填写第一台虚拟机的 IP 地址(如
192.168.83.161
虚拟机端口:填写
22
描述:可以填写便于识别的描述,如 “SSH 连接第一台虚拟机”。
填写完成后,点击 “确定” 保存规则。
4. 三台虚拟机都弄好之后,开始执行生效命令【在每台虚拟机上】:
systemctl restart sshd # 重启SSH服务
快速打开远程连接工具Xshell。下载链接(免费版本-家庭学校)https://www.xshell.com/zh/free-for-home-school/【安装步骤都是傻瓜式的,跟着默认走就好了】
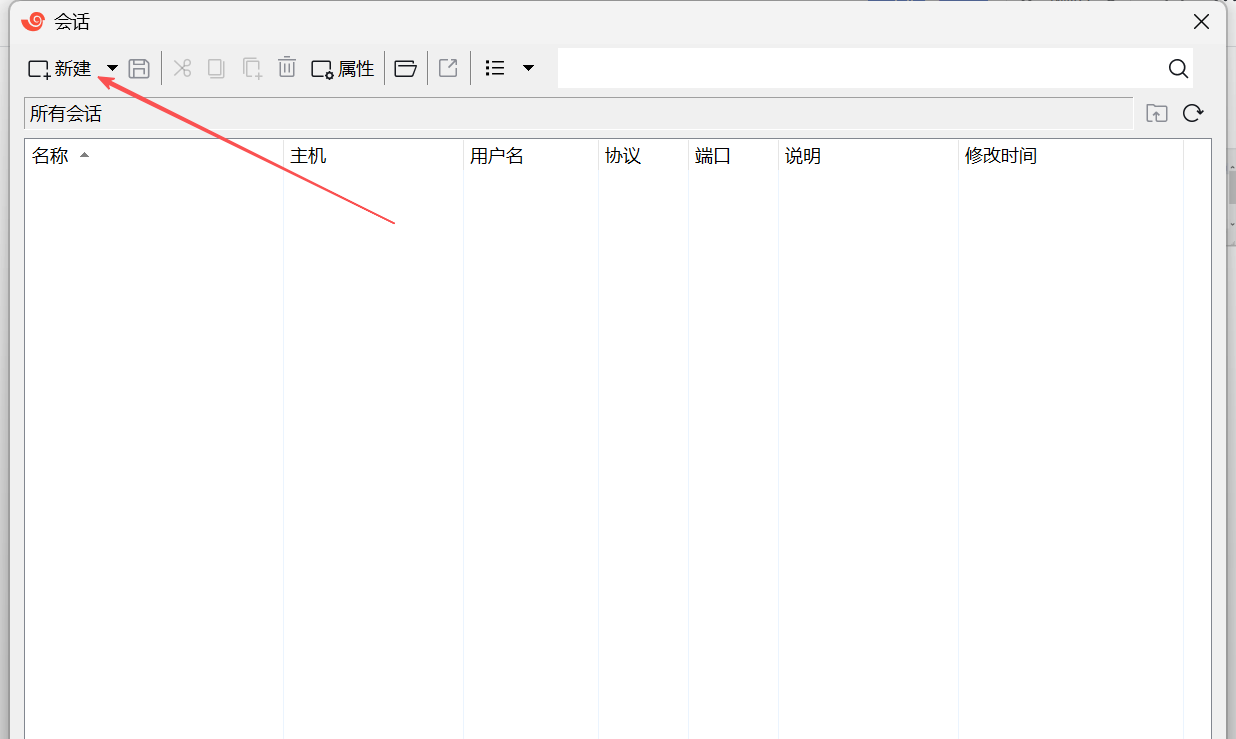
打开之后点击新建
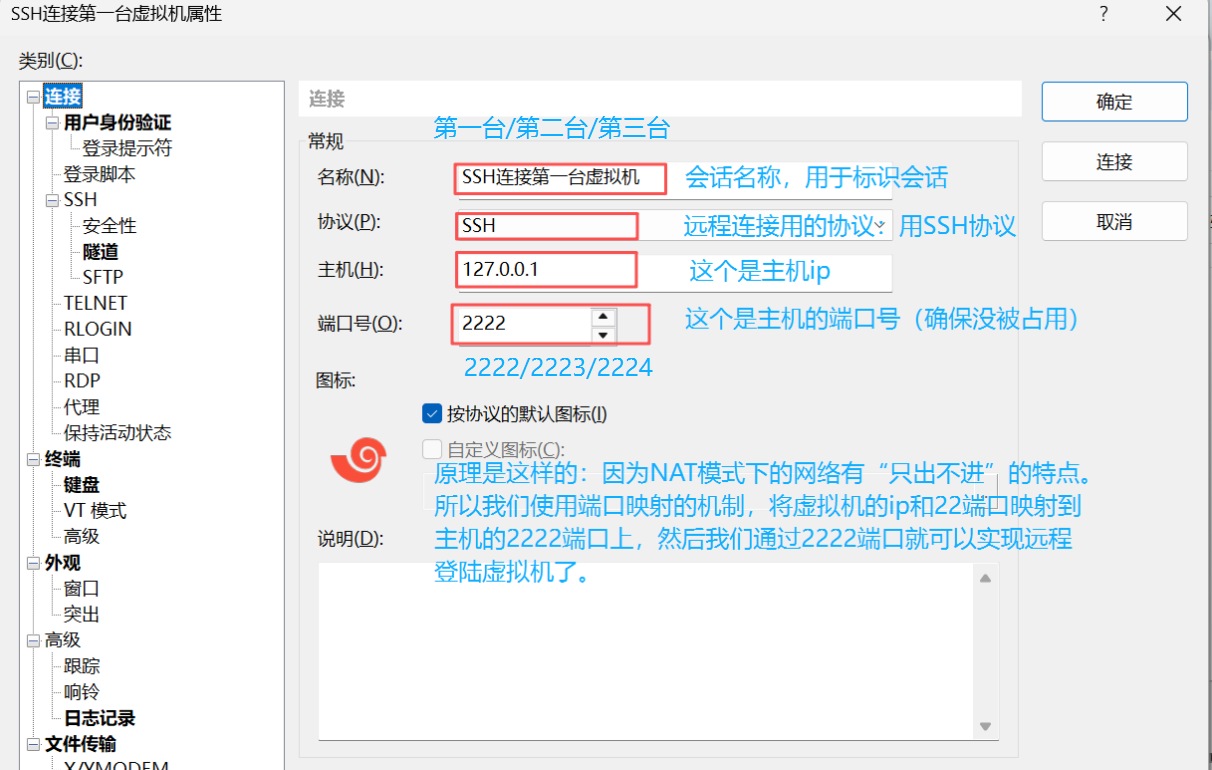
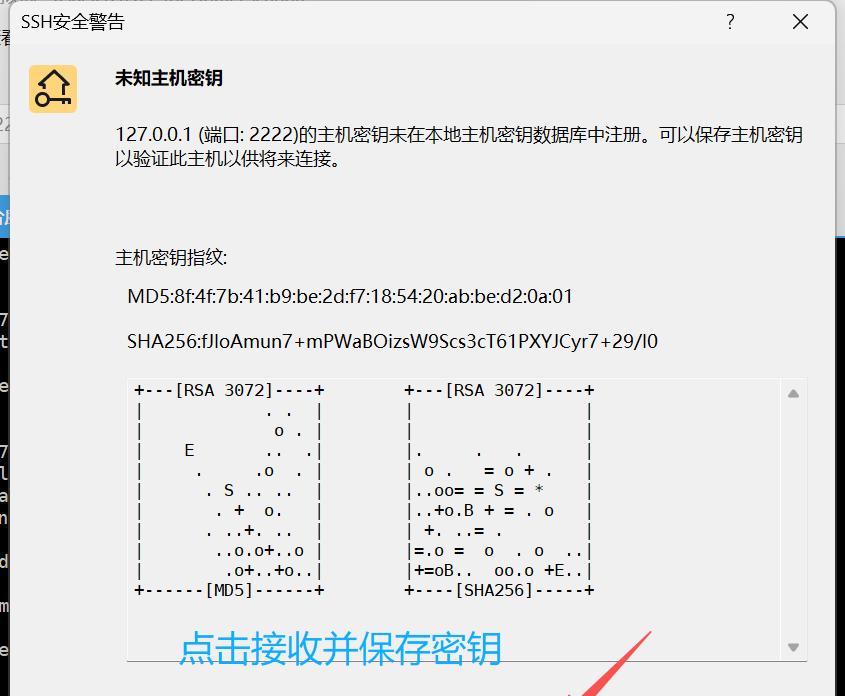
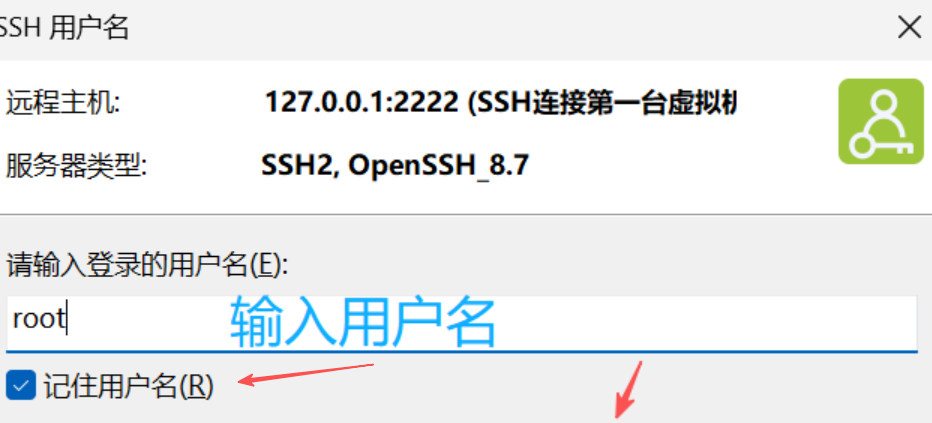
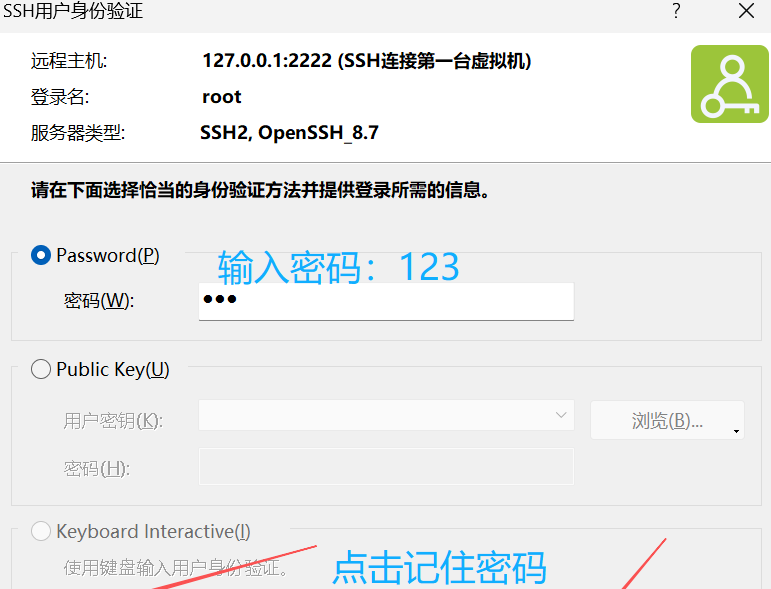
登陆成功

注意:
Hadoop2、Hadoop3也是一样的步骤进行远程登陆。
新建会话直接点击文件->新建即可。
3.4 配置虚拟机SSH免密登录功能
1. 生成秘钥
在虚拟机Hadoop1中执行“ssh-keygen -trsa”命令,生成密钥
ssh-keygen -trsa # 生成密钥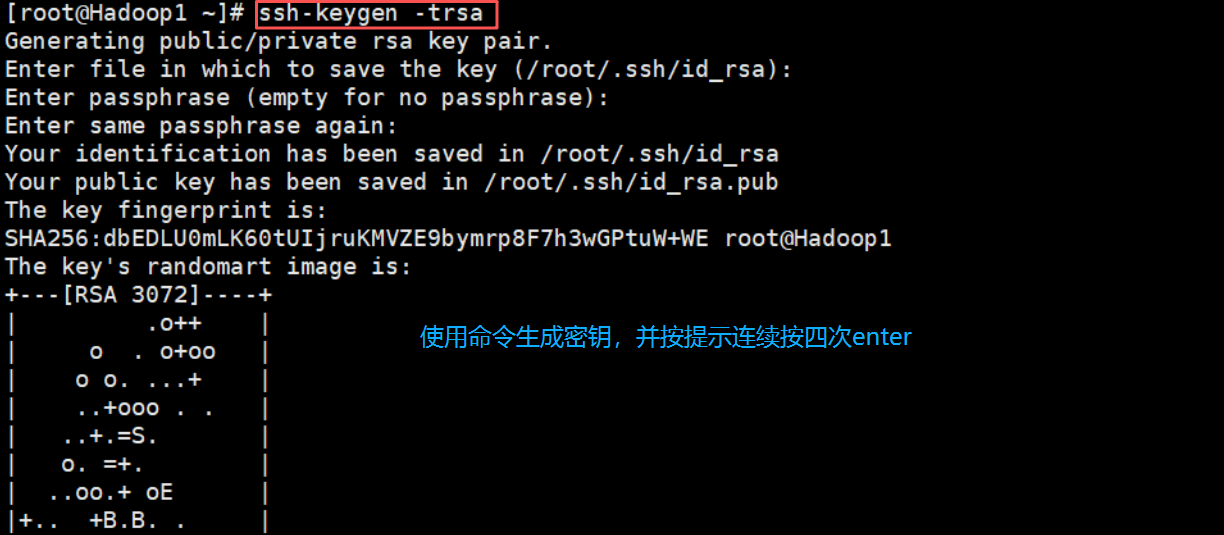
2. 查看秘钥文件
在虚拟机Hadoop1中执行“cd /root/.ssh/”命令进入存储密钥文件的目录在该目录下执行ll”命令查看密钥文件。
cd /root/.ssh/ # 进入存储密钥文件
ll # 查看密钥文件
3. 复制公钥文件
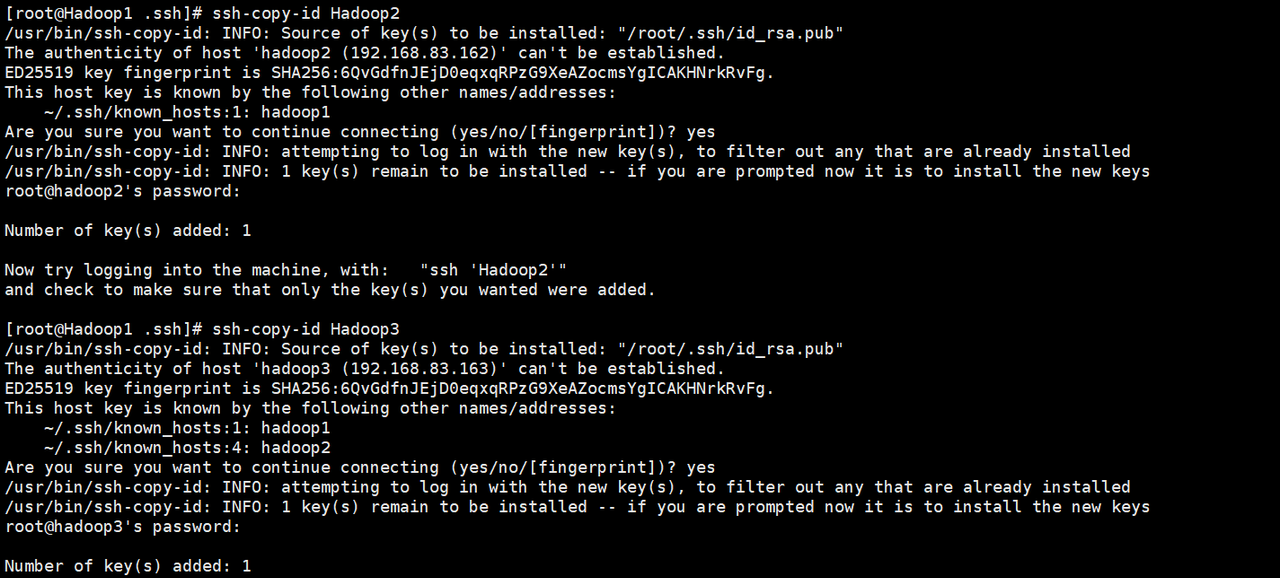
将虚拟机Hadoop1生成的公钥文件复制到集群中相关联的所有虚拟机,实现通过虚拟机Hadoop1可以免密登录虚拟机Hadoop1、Hadoop2和Hadoop3。
ssh-copy-id Hadoop1
ssh-copy-id Hadoop2
ssh-copy-id Hadoop3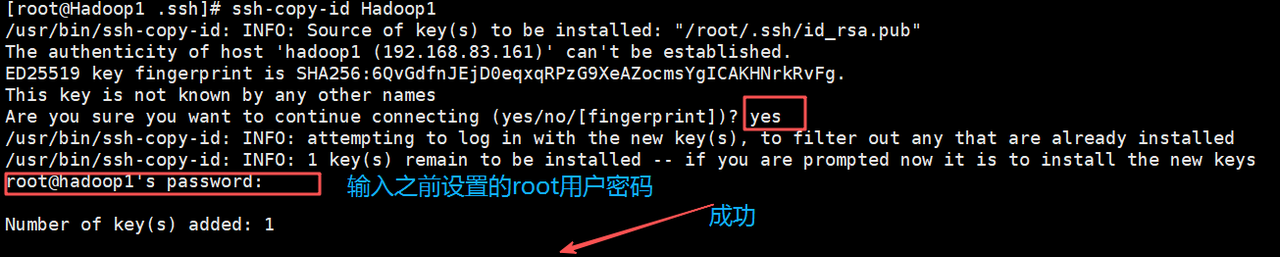
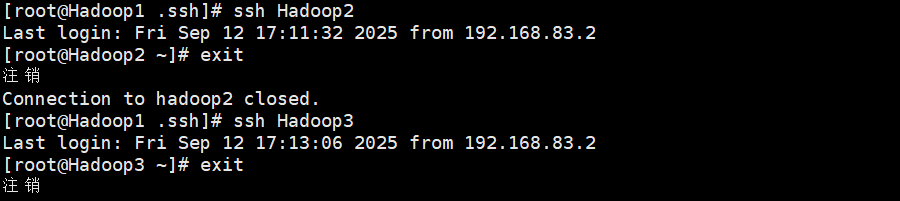
测试,没问题(exit命令是退出的意思)
4. 安装JDK
4.1 创建目录和添加权限
分别在虚拟机Hadoop1、Hadoop2和Hadoop3的根目录下创建以下目录作为约定。
mkdir -p /export/data/ # 创建存放数据的目录
mkdir -p /export/servers/ # 创建存放安装程序的目录
mkdir -p /export/software/ # 创建存放安装包的目录Hadoop1
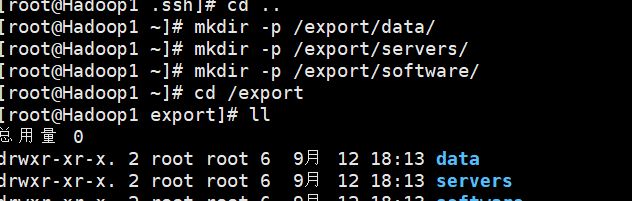
Hadoop2

Hadoop3
分别给他们添加权限(可读可写可改=》最高权限)
# 三台都要做一遍
chmod -R 777 /export/data/
chmod -R 777 /export/servers/
chmod -R 777 /export/software/Hadoop1
Hadoop2
Hadoop3
注意:这个命令可以全部复制了之后粘贴上去,按enter就全部执行了。
4.2 上传JDK安装包以及查看是否成功(这里提供两种方法)
####方法一:通过lrzsz软件包中的工具rz从本地上传文件到Linux服务器。
在虚拟机Hadoop1 /export/software目录执行“rz”命令,将JDK安装包。
cd /export/software # 进入安装包目录
yum install lrzsz # 下载lrzsz 软件包
rz #上传安装包命令注意:在 Linux 系统中执行
rz
lrzsz
rz
lrzsz


成功

提示:如果中途出错建议多试几次,只要是前面已经设置了文件夹的最高权限的。
#### 方法二:Xftp 就是用图形化拖拽的方式,替代命令行的 `rz/sz` 或 `scp`
Xftp下载地址https://www.xshell.com/zh/free-for-home-school/【没错,就是和Xshell在一块的那个】
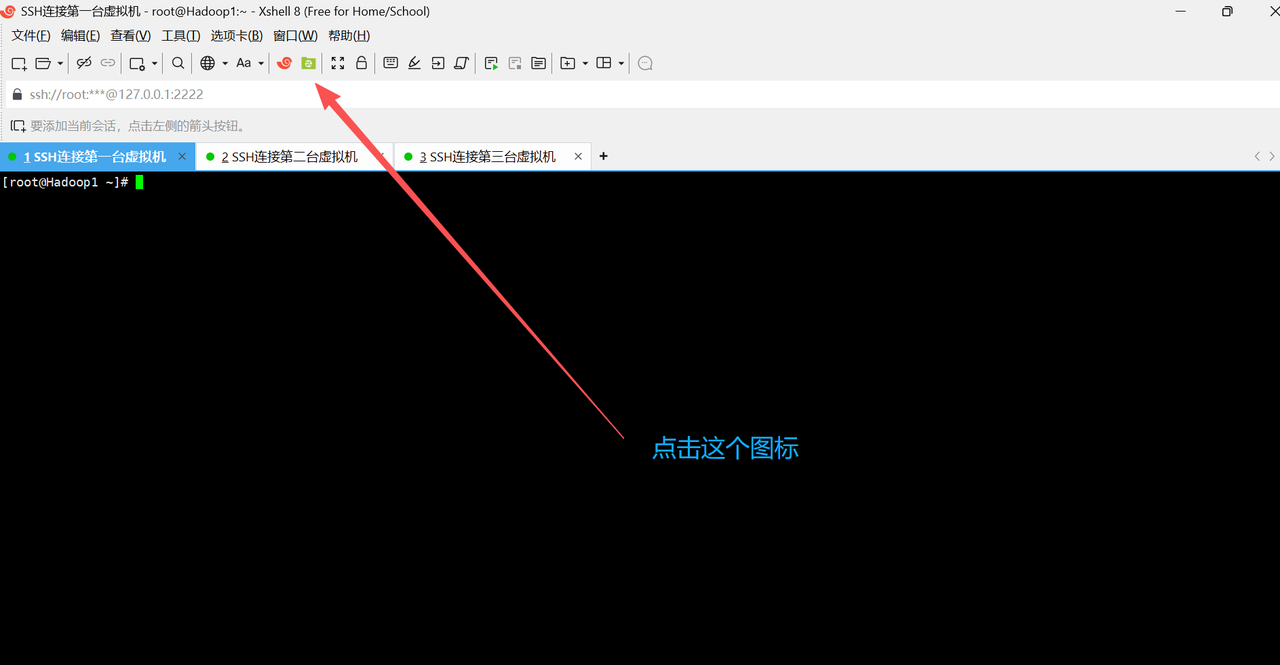
下载好之后,回到Xshell这里
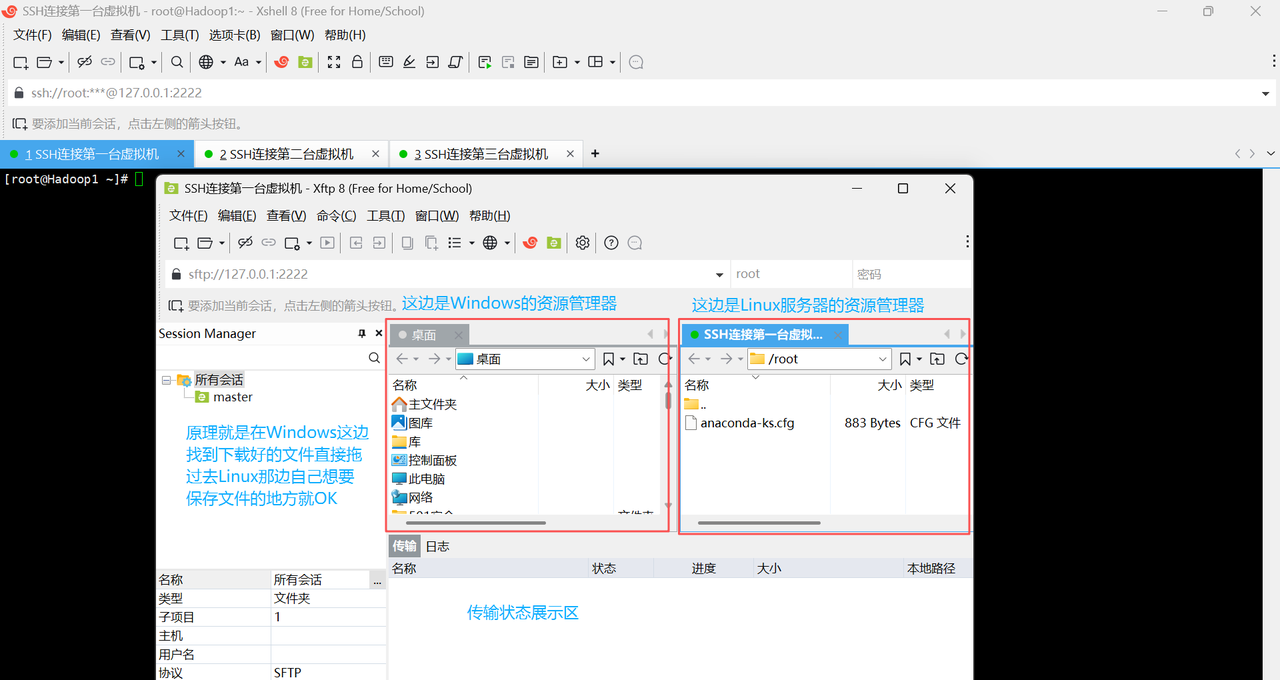
注意:
这里不用使用命令进入哪个目录下,因为它是和电脑上的操作差不多的。但是之前在服务器上创建的文件的权限还是要保证。还有一点就是要保证Xshell和Xftp都要保证是新版本,这个不用担心,点了之后默认跟着走,等更新完了就好了。
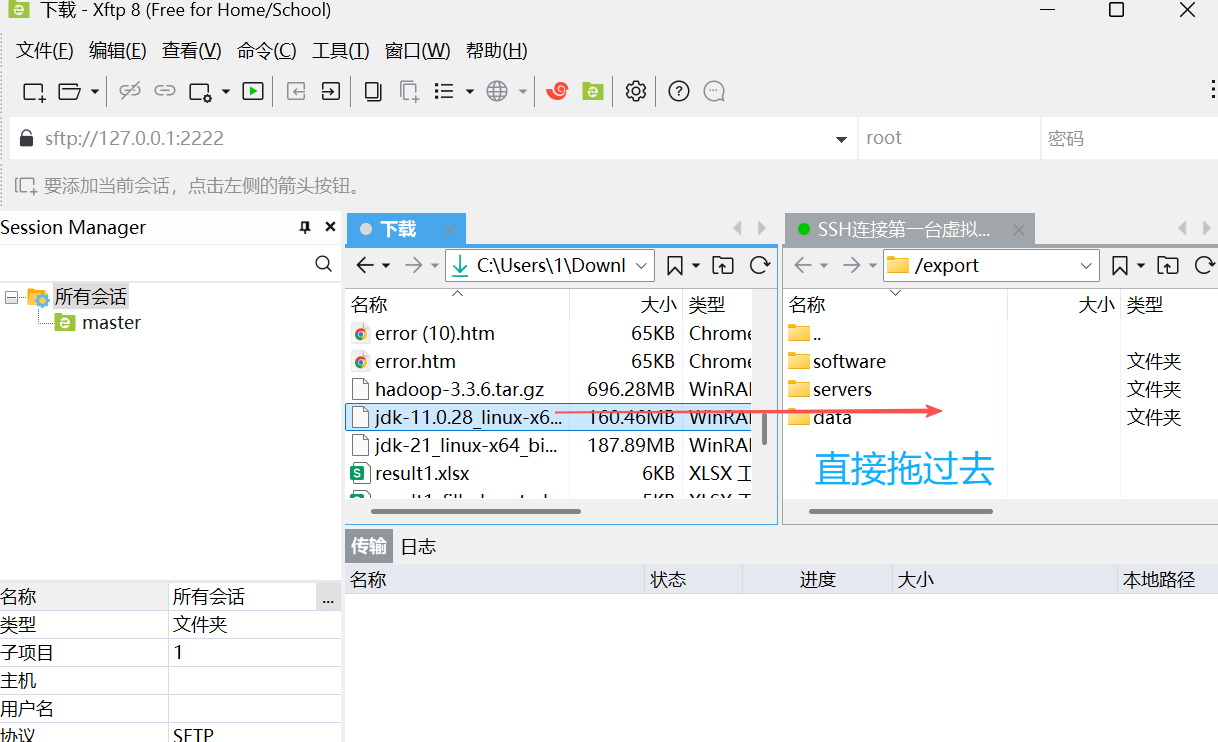
注意这里需要保证有文件夹的权限和写入者的权限【之前已经设置过】
成功

注明:这里因为刚刚已经上传过,所以我随便找了个目录(/export)上传在那里作为演示。
4.3 安装JDK
在虚拟机Hadoop1中,以解压方式安装JDK,将JDK安装到/export/servers目录。
cd /export/software # 进入安装包目录
tar -zxvf jdk-11_linux-x64_bin.tar.gz(这个要换成你jdk安装包的全名) -C /export/servers # 解压到指定目录/export/servers下成功
4.4 配置JDK系统环境变量
在虚拟机Hadoop1执行“vi/etc/profile”命令编辑环境变量文件profile,在该文件的底部添加配置JDK系统环境变量的内容。
# 进入并编辑文件
vi /etc/profile
# 复制配置
export JAVA_HOME=/export/servers/jdk-11.0.28
export PATH=$PATH:$JAVA_HOME/bin
# 生效命令
source /etc/profile注意

开始操作

4.5 验证JDK是否安装成功
在虚拟机Hadoop1执行“java -version”命令查看JDK版本号,验证当前虚拟机是否成功安装JDK。
java -version # 查看JDK版本号
4.6 分发JDK安装目录
通过scp命令将虚拟机Hadoop1的JDK安装目录分发至虚拟机Hadoop2和Hadoop的/export/servers/日录。
# 向虚拟机Hadoop2分发JDK安装目录
scp -r /export/servers/jdk-11.0.28 root@Hadoop2:/export/servers/
# 向虚拟机Hadoop3分发JDK安装目录
scp -r /export/servers/jdk-11.0.28 root@Hadoop3:/export/servers/成功

Hadoop2

Hadoop3

4.7 分发系统环境变量文件
通过scp命令将虚拟机Hadoop1的系统环境变量文件profile分发至虚拟Hadoop2和Hadoop3的/etc目录。
# 向虚拟机Hadoop2分发系统环境变量文件
scp /etc/profile root@Hadoop2:/etc
# 向虚拟机Hadoop2分发系统环境变量文件
scp /etc/profile root@Hadoop3 :/etc
# 然后分别到Hadoop2和Hadoop3中执行生效命令
source /etc/profile成功

看,成功咯


二、基于完全分布式模式部署Hadoop
其实整个原理是这样的:就是你对你下载好的安装包进行解压,解压好了之后对里面的相关配置文件进行配置,配置为,使用启动命令启动,就算是把这个集群配置好了。
扩展说明:
独立模式
独立模式是一种在单台计算机的单个JVM进程中模拟Hadoop集群的工作模式,此模式部署的Hadoop通常用于快速安装体验Hadoop的功能并不适用于实际生产环境。
伪分布式模式
伪分布式模式是一种在单台计算机的不同JVM进程中运行Hadoop集群的工作模式,此模式部署的Hadoop通常用于在开发环境中进行测试和调试,并不适用于实际生产环境。
完全分布式模式
完全分布式模式是一种在多台计算机的JVM进程中运行Hadoop集群的工作模式,Hadoop集群的每个守护进程都运行在不同的计算机中,此模式部署的Hadoop通常作为实际生产环境的基础。
部署前的安排
基于完全分布式模式部署Hadoop,需要将Hadoop中HDFS和YARN的相关服务运行在不同的计算机中,我们使用已经部署好的3台虚拟机Hadoop1、Hadoop2和Hadoop3。为了避免在使用过程中造成混淆,先规划HDFS和YARN的相关服务所运行的虚拟机。
1. 上传Hadoop和安装Hadoop
1.1 上传Hadoop【我这里使用Xftp,步骤之前做过】
1.2 安装Hadoop
以解压方式安装Hadoop,将Hadoop安装到虚拟机Hadoop1的/export/servers目录。

# 解压命令
tar -zxvf/export/software/hadoop-3.3.6.tar.gz -C /export/servers 
2. 配置Hadoop系统环境变量
虚拟机Hadoop1执行“vi /etc/profile”命令配置系统环境变量文件profile,在该文件的底部添加如下内容。
提示:这里的做法和上面配置JDK的一模一样,只是配置内容不一样。
vi /etc/profile # 进入配置文件
# 去到最后一行粘贴以下内容
export HADOOP_HOME=/export/servers/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使配置生效
source /etc/profile

3. 验证Hadoop系统环境变量是否配置成功
在虚拟机Hadoop1的任意目录执行“hadoop version”命令查看当前虚拟机中Hadoop的版本号。
hadoop version # 查看Hadoop版本号(验证配置)成功

4. 修改Hadoop配置文件hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
4.1 配置Hadoop运行时环境
在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录,执行“vi hadoop-env.sh”命令,在hadoop-env.sh文件的底部添加下述内容。
cd /export/servers/hadoop-3.3.6/etc/hadoop/
vi hadoop-env.sh
# 加入以下内容
export JAVA_HOME=/export/servers/jdk-21.0.8 # 指定Hadoop使用的JDK(就是jdk文件夹名称)
export HDFS_NAMENODE_USER=root # 指定管理NameNode服务的用户root
export HDFS_DATANODE_USER=root # 指定管理DataNode服务的用户root
export HDFS_SECONDARYNAMENODE_USER=root # 指定管理SecondNameNode服务的用户root
export YARN_RESOURCEMANAGER_USER=root # 指定管理ResourceManager服务的用户root
export YARN_NODEMANAGER_USER=root # 指定管理NodeManager服务的用户root提醒:粘贴在配置文件中时,把中文注释去掉。注意保存退出。

4.2 配置Hadoop
在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录执行“vi core-site.xml”命令添加如下内容。
vi core-site.xml # 进入编辑状态
<configuration>
<!-- 指定HDFS的默认文件系统,Hadoop1为主机名,9000为端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hadoop1:9000</value>
</property>
<!-- Hadoop临时文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.6</value>
</property>
<!-- Hadoop Web界面的静态用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 允许root用户代理的主机(*表示所有主机) -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 允许root用户代理的用户组(*表示所有用户组) -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- HDFS回收站文件保留时间(单位:分钟),1440分钟=24小时 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>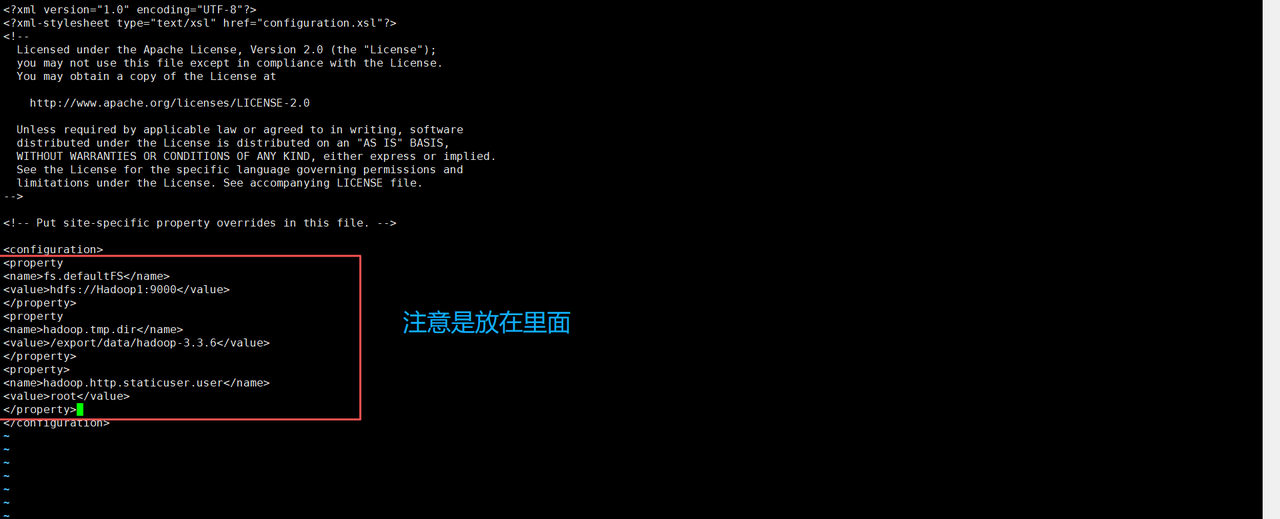
4.3 配置HDFS
在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录执行“vi hdfs-site.xml”命令添加如下内容。
vi hdfs-site.xml # 进入可编辑状态
<property>
<name>dfs.replication</name>
<value>2</value>
<!--指定HDFS的副本数为2-->
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Hadoop2:9868</value>
<!-- 指定SecondaryNameNode服务运行在虚拟机Hadoop2 -->
</property>4.4 配置MapReduce
在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录执行“vi mapred-site.xml”命令添加如下内容。
vi mapred-site.xml # 进入可编辑状态
# 加入以下内容。在<configuration>和</configuration>中。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!-- 指定MapReduce任务运行在YARN之上 -->
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Hadoop1:10020</value>
<!-- 指定MapReduce历史服务的通信地址 -->
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Hadoop1:19888</value>
<!-- 指定通过Web Ul访问MapReduce历史服务的地址 -->
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
<!-- 指定MapReduce任务的运行环境 -->
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
<!-- 指定MapReduce任务中Map阶段的运行环境 -->
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
<!-- 指定MapReduce任务中Reduce阶段的运行环境 -->
</property>4.5 配置YARN
1. 在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录执行“vi yarn-site.xml”命令添加如下内容。
vi yarn-site.xml # 进入可编辑状态
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
<!-- 指定ResourceManager服务运行在虚拟机Hadoop1 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!-- 指定NodeManager运行的附属服务 -->
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<!-- 指定是否启动检测每个任务使用的物理内存 -->
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<!-- 指定是否启动检测每个任务使用的虚拟内存 -->
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<!-- 指定是否开启日志聚合功能 -->
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
<!-- 指定日志聚合的服务器 -->
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<!-- 指定日志聚合后日志保存的时间 -->
</property>
</configuration>4.6 配置Hadoop从节点服务器
在虚拟机Hadoop1的/export/servers/hadoop-3.3.6/etc/hadoop/目录执行“vi workers”命令,**将workers文件默认的内容修改为如下内容**。
vi workers # 进入可编辑状态
# 加入以下内容
Hadoop2
Hadoop3
5. 分发Hadoop安装目录
使用scp命令将虚拟机Hadoop1的Hadoop安装目录分发至虚拟机Hadoop2和Hadoop3中存放安装程序的目录。
# 向虚拟机Hadoop2中分发存放安装程序的目录
scp -r /export/servers/hadoop-3.3.6 root@Hadoop2:/export/servers
# 向虚拟机Hadoop3中分发存放安装程序的目录
scp -r /export/servers/hadoop-3.3.6 root@Hadoop3:/export/servers成功

6. 分发系统环境变量文件
使用scp命令将虚拟机Hadoop1的系统环境变量文件profile分发至虚拟机Hadoop2和Hadoop3的/etc目录。
# 向虚拟机Hadoop2中分发/etc目录
scp /etc/profile root@Hadoop2:/etc
# 向虚拟机Hadoop3中分发/etc目录
scp /etc/profile root@Hadoop3:/etc
#生效命令(分别在Hadoop2和Hadoop3执行)
source /etc/profile成功

Hadoop2

Hadoop3

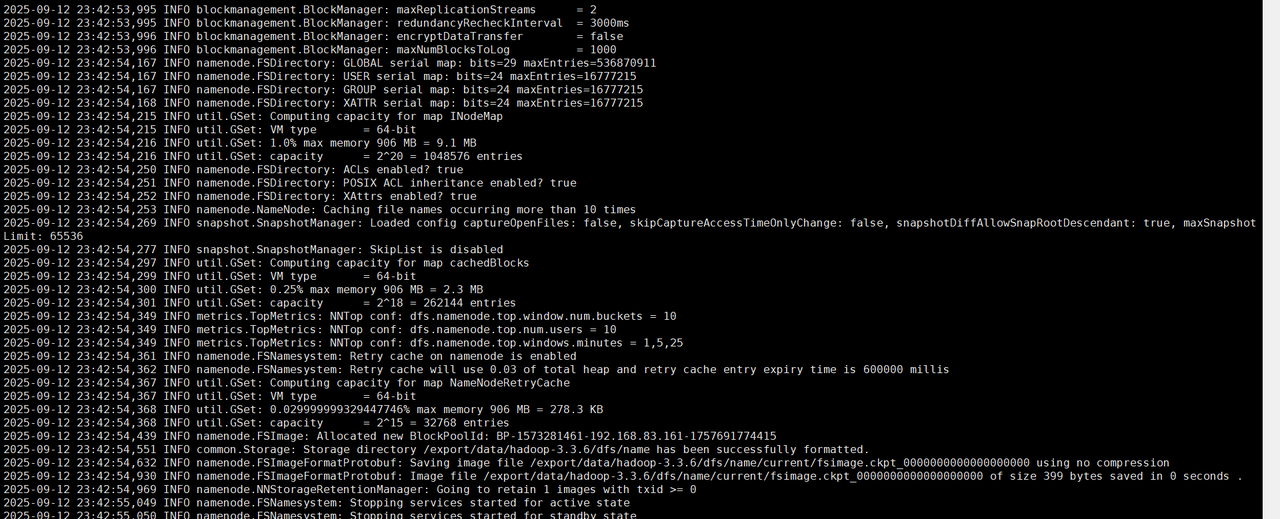
7. 格式化HDFS文件系统
在虚拟机Hadoop1执行“hdfs namenode -format”命令,对基于完全分布式模式部署的Hadoop进行格式化HDFS文件系统的操作。
注意:格式化HDFS文件系统的操作只在初次启动Hadoop集群之前进行。
hdfs namenode -format # 格式化命令成功
8. 启动Hadoop
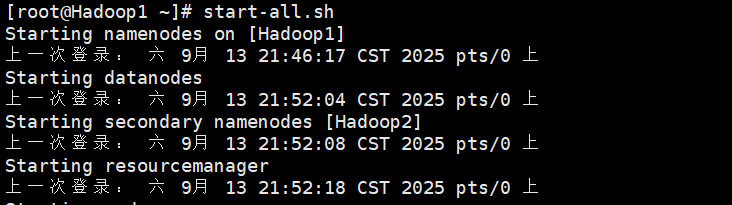
在虚拟机Hadoop1中执行命令启动Hadoop
# 启动HDFS
start-dfs.sh
# 启动YARN
start-yarn.sh
# 或者直接start-all.sh
# 关闭Hadoop
stop-dfs.sh
stop-yarn.sh
# 或是直接stop-all.sh成功
9. 查看Hadoop运行状态
Hadoop1

Hadoop2
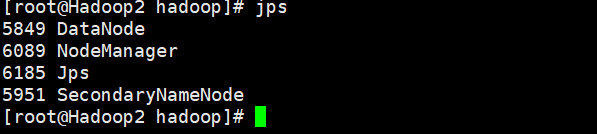
Hadoop3
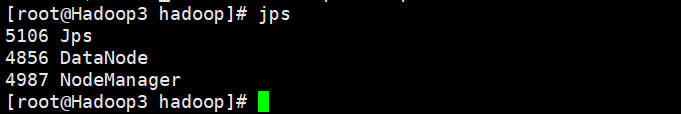
三、通过Web UI查看Hadoop运行状态
Hadoop启动成功后,我们可以通过Hadoop提供的Web UI管理HDFS和YARN,Hadoop默认占用服务器的9870和8088两个端口,用于用户访问HDFS和YARN的WebUI,我们可以在本地计算机的浏览器中输入NameNode和ResourceManager服务所运行的服务器IP地址或主机名,以及9870或8088端口访问HDFS或YARN的Web UI。
1. 关闭3台虚拟机的防火墙
关闭虚拟机Hadoop1、Hadoop2和Hadoop3的防火墙,分别在3台虚拟机中运行如下命令关闭防火墙并禁止防火墙开启启动。
作用:防火墙是一种网络安全设备,用于监控和控制进出网络或主机的网络流量。它依据预先设定的规则,允许或阻止特定的网络连接和数据包通过。在虚拟机环境中,防火墙默认会阻止外部对虚拟机内服务端口(比如 Hadoop 的 9870 和 8088 端口 )的访问,这是出于安全考虑,防止未经授权的访问。
systemctl stop firewalld # 关闭防火墙2. 配置端口映射
去到VMware Workstation 中,点击编辑->虚拟网络编辑器->更改设置->NAT模式->NAT设置,端口转发处,点击添加,一个一个的把信息填上去。就是前面步骤里做远程登陆时做的步骤,一样的操作。
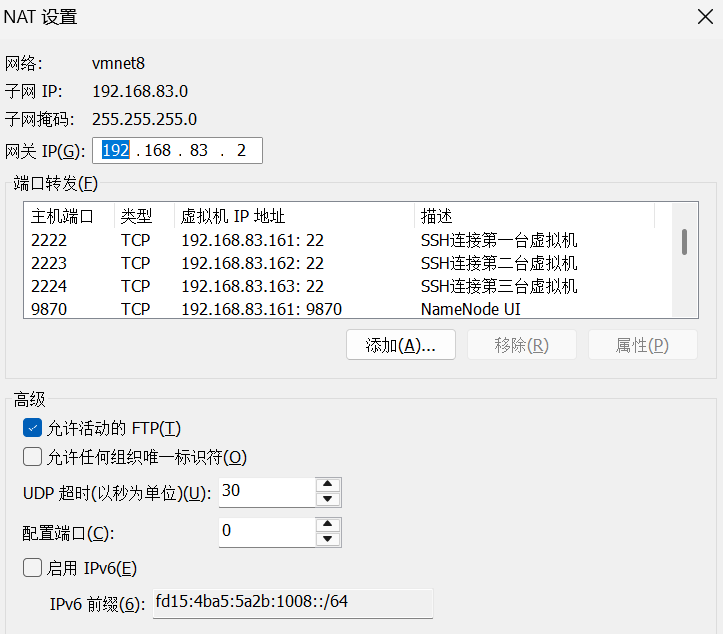
#主机端口 虚拟机IP 虚拟机端口 描述
9870 192.168.83.161 9870 NameNode UI
8088 192.168.83.161 8088 ResourceManager UI
19888 192.168.83.161 19888 JobHistory UI
9864 192.168.83.162 9864 DataNode1 UI
9865 192.168.83.163 9864 DataNode2 UI(为了避免冲突需用不同主机端口9865)3. 通过Web UI查看Hadoop运行状态
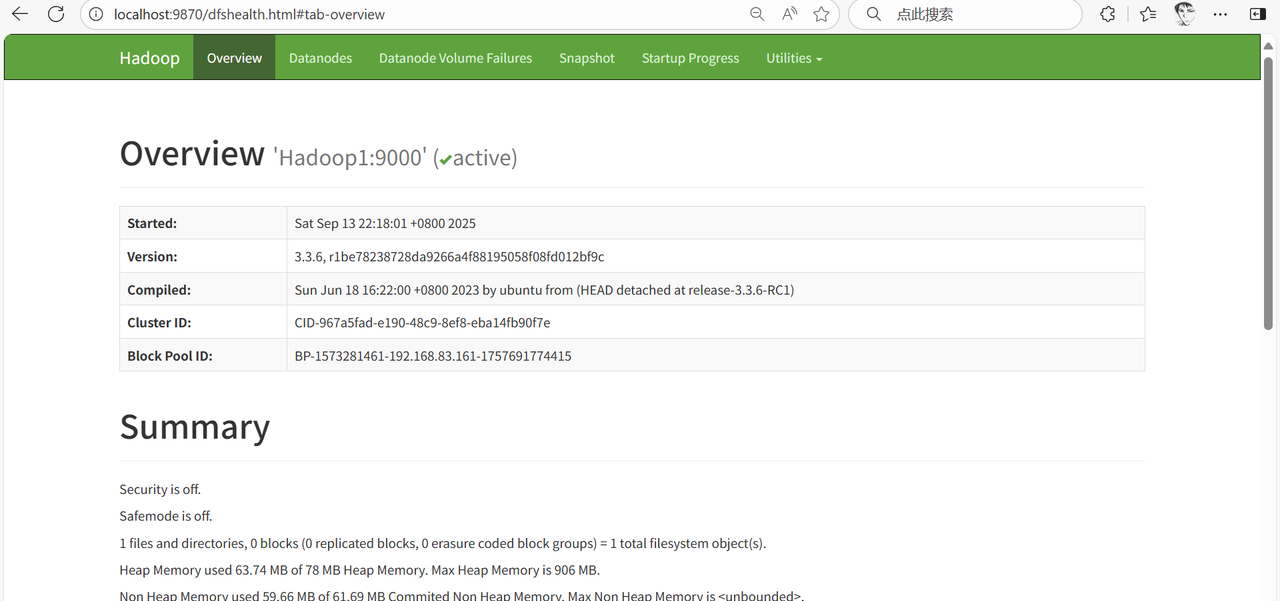
1. 在本地计算机的浏览器输入http://localhost:9870查看HDFS的运行状态
2. 在本地计算机的浏览器输入http://localhost:8088查看YARN的运行状态

再次提示:这里一定要把防火墙关闭才能看到UI界面。
四、在Hadoop集群中运行MapReduce程序对数据文件(数据文件内容可以自定义)进行词频统计
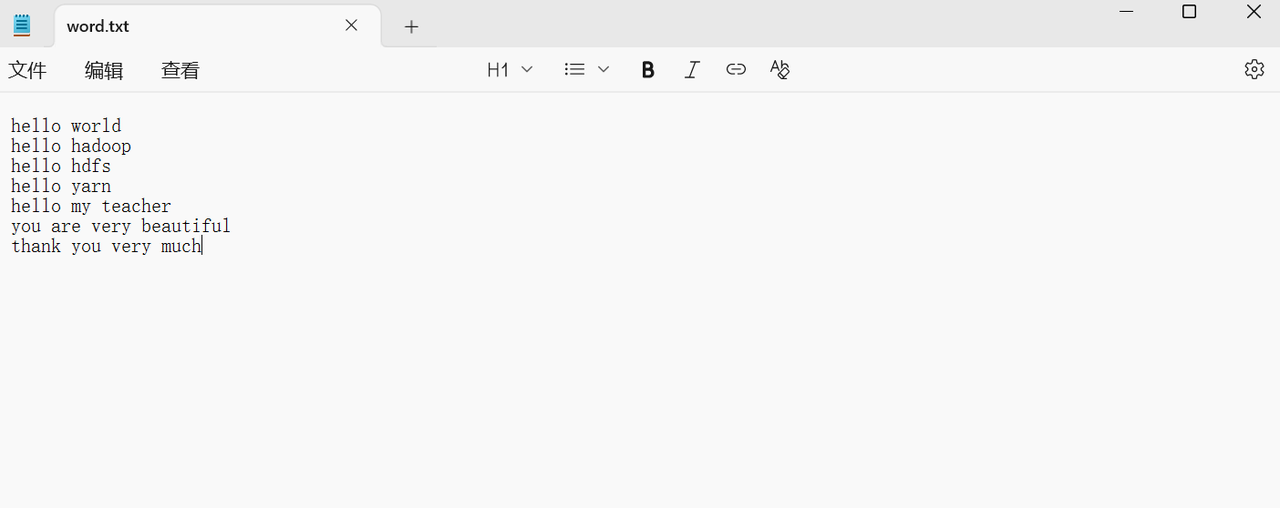
1. 准备文本数据
创建一个名称为word.txt的文本文件并填充数据。
2. 创建目录
在HDFS创建/wordcount/input目录,用于存放文件word.txt。
hdfs dfs -mkdir -p /wordcount/input
成功

3. 上传文件
在虚拟机Hadoop1的/export/data/目录执行“rz”命令上传文件word.txt至虚拟机data目录下然后将文件word.txt上传到HDFS的/wordcount/input目录
cd /export/data/ # 进入data目录
rz # 上传数据文件
hdfs dfs -put /export/data/word.txt /wordcount/input #将数据文件上传到集群文件夹(目录)成功



4. 运行MapReduce程序
1. 进入虚拟机Hadoop1的/export/servers/hadoop-3.3.6/share/hadoop/mapreduce目录,在该目录下执行“ll”命令,查看Hadoop提供的MapReduce程序。
cd /export/servers/hadoop-3.3.6/share/hadoop/mapreduce
ll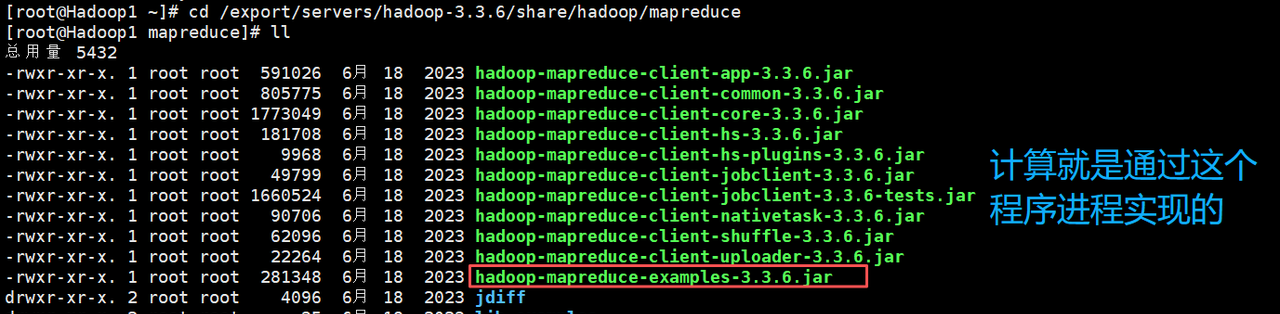
2. 在MapReduce程序所在的目录执行下列命令,统计word.txt中每个单词出现的次数。
# 运行命令
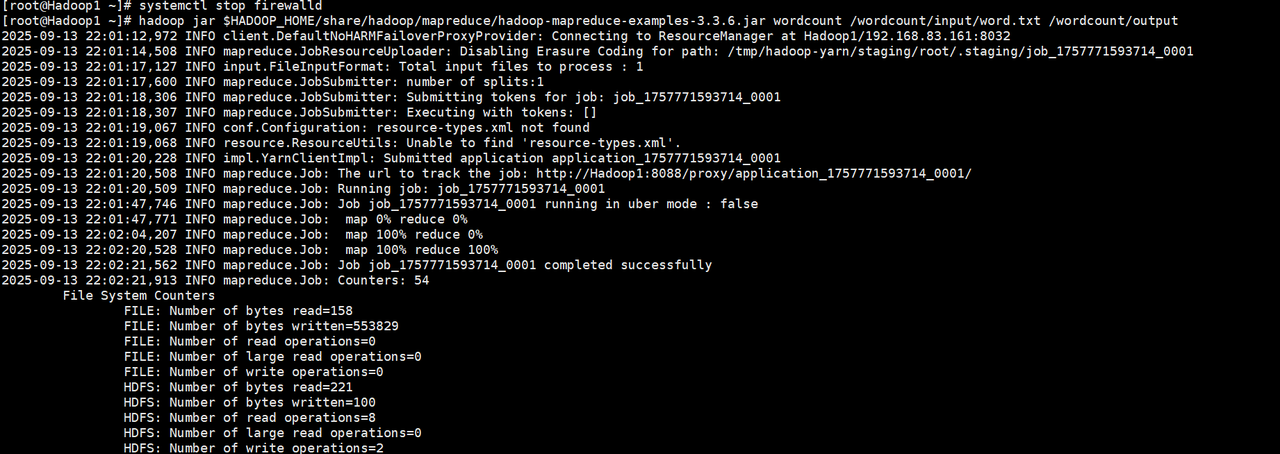
hadoop jar hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/input /wordcount/outputhadoop jar:用于指定运行的MapReduce程序
wordcount:表示程序名称
/wordcount/input:表示文件word.txt所在目录
/wordcount/output:表示统计结果输出的目录
注意:WordCount 作业要求输出目录(
)必须不存在,否则会失败(Hadoop 为了防止数据覆盖,默认不允许输出目录已存在)
/wordcount/output
3. MapReduce程序部分运行效果。
5. 查看MapReduce程序运行状态
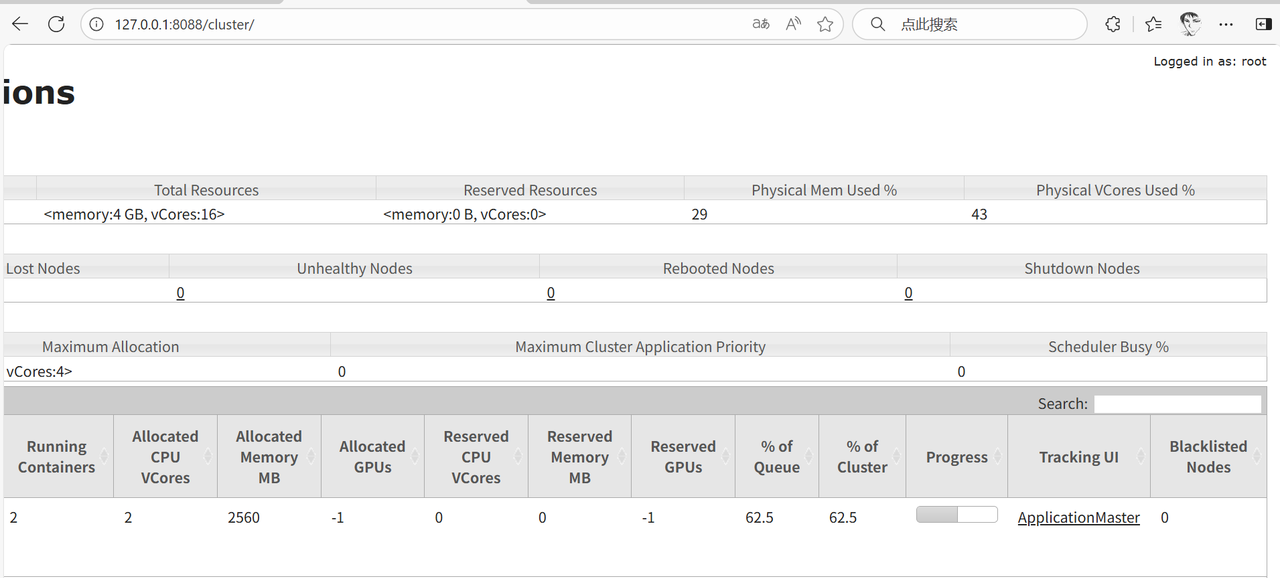
MapReduce程序运行过程中,使用浏览器访问YARN的Web UI查看MapReduce程序的运行状态。
6. 查看统计结果
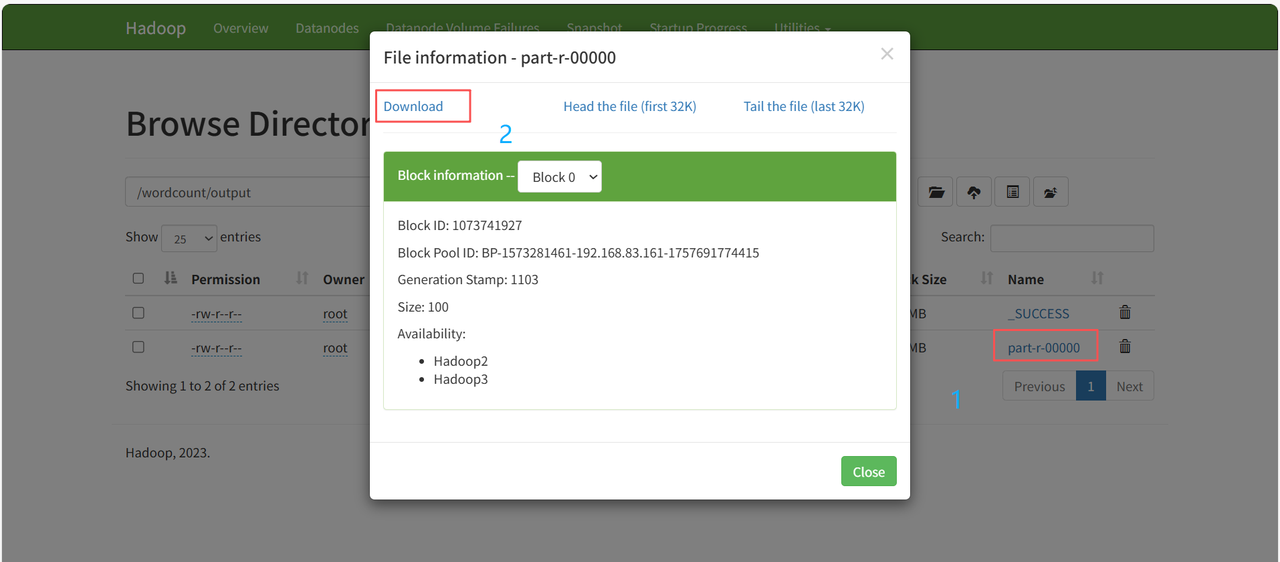
在HDFS的Web UI查看统计结果。
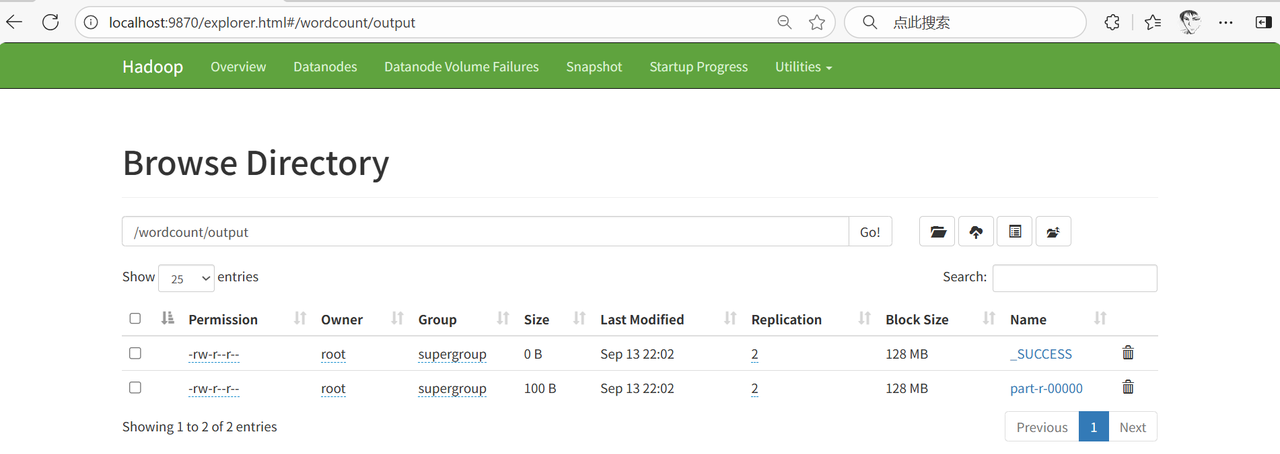
查看结果文件part-r-00000的内容。
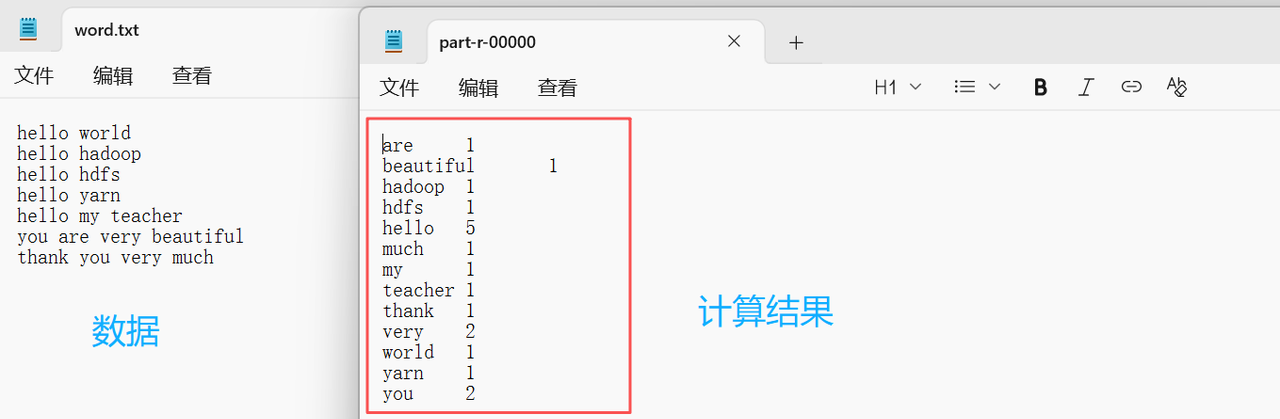
这里我用记事本打开,并且和之前的对比着看,计算没问题。
完结
撒花【作者创作不易,能给个免费的三连吗】

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...