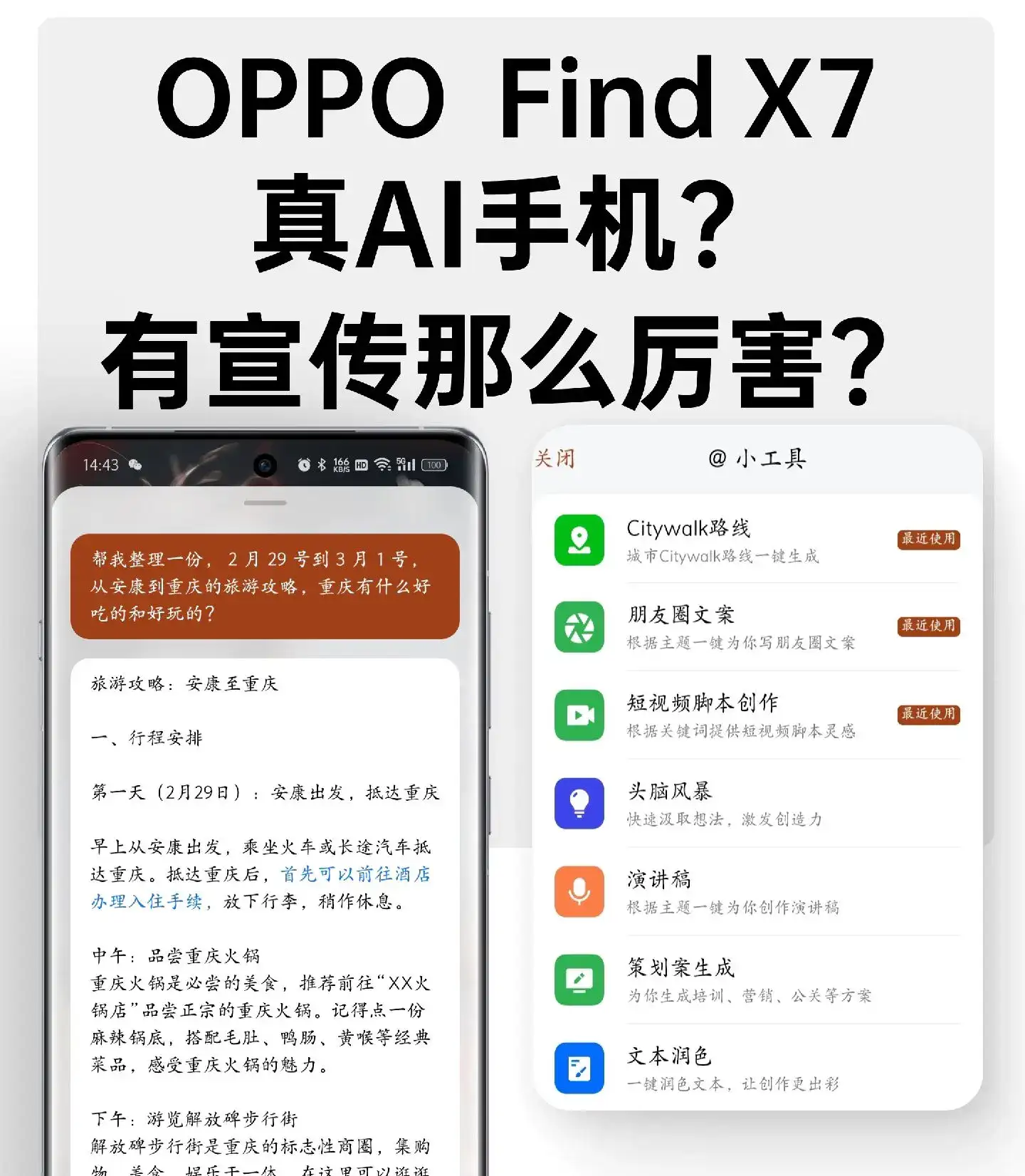
最近,Hugging Face 发布了史上最大规模的开源 PDF 数据集 FinePDFs 总结下核心信息:数据规模:3 万亿 tokens,覆盖 1733 种语言的 4.75 亿份 PDF,总大小约 3.65 TB;数据来源:2013 年至 2025 年的 105 个 CommonCrawl 快照 + 互联网重新抓取;处理方式:去重、OCR、模板剔除、语言识别,使用 Hugging Face 的 datatrove 大规模处理;开源许可:ODC-By 1.0,完全可复现,GitHub 提供代码和评估脚本;性能表现:与 HTML 语料结合时,在多项基准上显著提升效果。看上去,这是一个离普通人很遥远的新闻。一开始,我看到这个新闻,第一感觉也是麻木了。AI每天都在飞速发展,我也是热烈满满各种尝试,但目前,各种大模型更新迭代,我已经麻木了。这和我有啥关系?许多人看到这种新闻,第一反应可能也是:“AI 又更新了?和我有什么关系?”“每天都说 AI 越来越机智,我已经麻了。”“说实话,看不懂,也没啥感觉。”但实际上,这种“看不懂的大更新”,正在悄悄改变我们用 AI 的体验。红利是什么?红利就是:AI 在我们不知不觉中变得更懂 PDF 长文档了。以前,你可能觉得:几百页的合同、说明书、论文丢给 AI,它只会胡言乱语。未来,有了 FinePDFs 这样的数据集,AI 能够:更好地总结论文和专业报告;更准确地理解长合同、法律条款;更快地帮你找到资料里的关键点。这就是红利——你不用自己训练模型,却能直接享受更机智的 AI 工具。那普通人怎么用上这次更新?学习 工作:学生丢论文,AI 给你提炼要点;职场人丢行业报告,AI 帮你做摘要。内容创作:写公众号、小红书,AI 更懂资料,给你更扎实的支撑。编程开发:AI 更能理解技术文档,帮小白更快调用 API。生活日常:遇到看不懂的说明书、隐私条款,AI 能解释得清清楚楚。换句话说,红利已经落在你手里,就差你会不会用了。为什么不能等 AI 更机智再学?有人会想:既然 AI 会越来越机智,那我等到零门槛的时候再学不就行了?问题在于:工具迭代太快,你等的过程,本质上在失去机会窗口;应用窗口期有限,早一步上手,就能更快抓住新机会;思维方式需要时间迁移,和 AI 协作不是一蹴而就的,需要长期沉淀。等到人人都会用 AI 的时候,你可能已经错过了属于普通人的红利期。举一反三:AI 数据集能带来哪些机会?站在应用层,普通人完全可以把“AI 更懂 PDF”转化为自己的工具或服务。给你几个头脑风暴的方向(结合AI给的提议):留学与签证文档助手:使馆 学校 PDF 材料一键清单、双语解读;海外租房与合约解读:租约条款自动解析,提醒押金与违约风险;产品说明书翻译官:家电说明书一键问答,支持多语言;跨境合规雷达:各国注册、税务、政策文件一键提炼;RFP 招标文件助手:百页标书自动抽取关键评分点;学术 行业白皮书速读:长文档 PDF 转 5 分钟摘要,做成订阅资讯站;专利提炼工具:提取创新点、对比竞品专利;隐私政策 服务条款解释器:自动归纳用户权利与风险提示;发票 物流单证结构化:PDF 转 CSV Excel,做自动化报表;房地产披露文件助手:美国 HOA 文件自动解析关键条款。这些都可以做成轻量的出海网站、小工具,快速上线、快速试错。AI 的更新看似和普通人无关,但实则它们正悄悄决定:未来谁能抓住机会。等到 AI 无所不能时,你只是“用的人”;从目前开始,你可以成为“创造的人”。










© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...