Visual Thoughts: A Unified Perspective of Understanding Multimodal Chain-of-Thought
摘要
大规模视觉-语言模型(LVLMs)在多模态任务中取得了显著成功,多模态思维链(MCoT)进一步提升了其性能和可解释性。最近的MCoT方法分为两类:(i)文本型MCoT(T-MCoT),接受多模态输入并生成文本输出;以及(ii)交叉型MCoT(I-MCoT),生成交错的图文输出。尽管这两种方法都取得了进展,但推动这些改进的机制尚未被充分理解。为弥补这一空白,我们首先揭示了MCoT通过引入“视觉思维”来提升LVLMs的表现,“视觉思维”能够在推理过程中传递图像信息,这种传递与MCoT的格式无关,仅取决于表达的清晰性和简洁性。此外,为了系统地探索“视觉思维”,我们定义了四种不同形式的“视觉思维”表达并对其进行了全面分析。我们的研究表明,这些形式在清晰性和简洁性上各有不同,从而导致了不同程度的MCoT改进效果。此外,我们还探讨了“视觉思维”的内在本质,发现“视觉思维”在输入图像与深层变换器之间的推理中充当中介角色,从而实现更高级的视觉信息传递。我们希望“视觉思维”能够为未来的MCoT研究带来更多突破。

图1:比较 (a) 纯文本推理的文本MCoT(T-MCoT)与 (b) 图文交错推理的交错MCoT(I-MCoT)。VT:视觉思维。
1 引言
最近,大型视觉-语言模型(LVLMs)在解决各种多模态任务方面取得了显著进展 [56, 22, 52]。受链式推理(Chain-of-Thought,CoT)成功的启发 [45, 17, 3],LVLMs 已经结合了多模态链式推理(Multi-modal CoT,MCoT),从而在多模态环境中实现逐步生成推理路径。这一进步提升了模型的推理能力,使其能够更复杂地与多模态输入进行交互 [53, 4]。具体来说,当前的 MCoT 技术一般分为两种范式:(1)文本式多模态链式推理(Textual-MCoT,T-MCoT):这种方法遵循传统的链式推理框架,从多模态输入生成基于文本的推理过程(参见图 1 (a))。例如,一些方法要求 LVLMs 解释和描述视觉元素,然后得出答案 [54, 51],而另一些方法通过结合从图像中派生的 JSON 格式场景图来增强推理 [30, 31]。(2)交替式多模态链式推理(Interleaved-MCoT,I-MCoT):一种较新的方法,例如 o3-mini [33] 和 Visual Sketchpad [15],生成交替出现的图像-文本推理过程(参见图 1 (b))。此方法使用外部工具,例如代码解释器或专业视觉模型,对图像进行修改以辅助推理 [28, 15, 55],另一些方法则使用图像生成模型创建新图像以增强推理过程 [27, 19]。然而,这两种范式之间的争论仍未解决。一些研究人员认为,I-MCoT中的交错推理更能反映人类对多模态输入的认知处理方式,可能比T-MCoT具有优势[15, 19]。相反,其他研究表明,在数学上下文中,仅使用文本推理可能表现更优[55, 7]。这一分歧凸显了对不同MCoT方法背后机制理解的根本性差距。此外,文献中缺乏统一框架来解释MCoT的有效性、识别最优的MCoT范式或在任务间推导具有普遍意义的洞见。基于此,我们在这项工作中旨在探讨以下研究问题:不同的MCoT范式以不同方式增强LVLMs的背后机制是否存在统一解释?为此,我们揭示了MCoT通过将视觉思维[18]整合到推理生成中统一提升了LVLMs的表现。视觉思维是中间的、逻辑驱动的跨模态表征,它在统一视角下促进并加速多模态推理。通过缓存提炼的视觉信息,它桥接了原始像素和语言推理,能够进行快速、上下文感知的访问,而无需重新处理图像。从概念上看,如图2所示,图像特征和视觉思维类似于外部内存和缓存:原始图像需要缓慢且资源密集型的检索,而视觉思维保留关键内容供快速访问,从而提高推理效率并降低计算成本。此外,视觉思维传输的有效性和效率还能进一步解释不同MCoT范式间性能差异。为了验证这一点,在实验过程中,我们首先验证了视觉思维在提升MCoT性能方面的效果。随后,为了深入探索视觉思维在不同表达形式中的作用,我们将其分类为四种主要策略:自然语言、结构化语言、编辑图像和生成图像视觉思维。此外,我们还探讨了LVLMs中的内部注意机制和信息流,以分析视觉思维的推理依据。我们的研究发现如下:(1)移除视觉思维并仅依赖原始图像进行推理会损害性能,甚至比直接从查询推理表现更差。
(2)不同表达形式的视觉思维在特定场景中更具效果,取决于其表达的清晰度和效率。
(3)视觉思维不仅携带视觉信息,还作为主要中介,将输入图像连接到更深的变换器层,启用LVLMs更高级的认知处理。
我们的主要贡献可以总结如下:
• 我们首次全面探索了视觉思维在MCoT推理中的驱动机制。这一统一视角提供了关于决策过程中文本视觉认知展开的新见解。
• 我们引入了四种不同策略系统探索视觉思维,展示了不同策略的优势和劣势。
• 我们的分析进一步深入研究了视觉思维的本质,揭示了关键见解,例如视觉信息如何整合到推理路径中,从而使更多视觉信息传递到LVLMs的更深变换器层。
我们希望这些发现能激发该领域未来研究的更多突破。
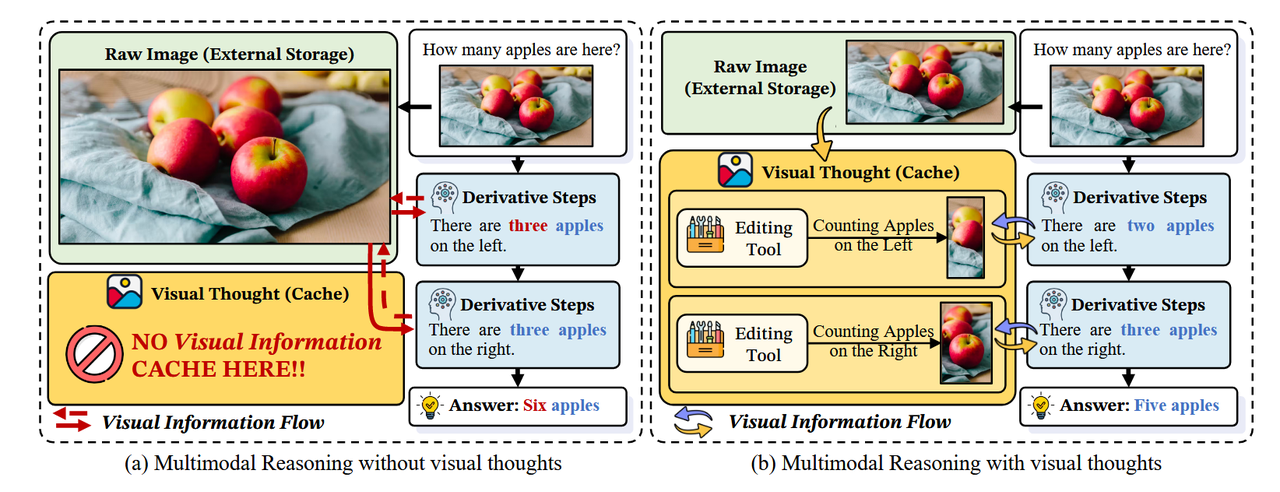
图2:从计算机系统的角度比较多模态推理:(a)将视觉思维视为内部视觉缓存与(b)直接访问原始图像作为外部存储。
2 视觉思维
2.1 可视化思维的定义
为了解释MCoT如何提升性能,我们认为其主要优势在于引入了“视觉思维”,即中间推理步骤,这些步骤能够明确传达视觉信息,使LVLMs能够执行更深层次的视觉推理。如图2所示,LVLMs将原始图像视为外部记忆,迫使模型在每一步重新处理整个视觉输入,从而限制了推理深度。相比之下,“视觉思维”仅提取与指令相关的区域(例如,左侧和右侧的苹果)并将其存储为缓存。后续的推理步骤查询此缓存,而不是完整图像,从而减少计算开销并实现更深层次的多步MCoT。形式上,一个“视觉思维”(REVT)是一个推理步骤,它传达来自视觉输入VI和所有先前步骤R<i = {R1, R2, . . . , Ri−1}的信息。这些步骤由任务问题QT和明确的指令IE驱动,以请求MCoT表达式EVT。模型随后生成如下的下一推理步骤Ri:
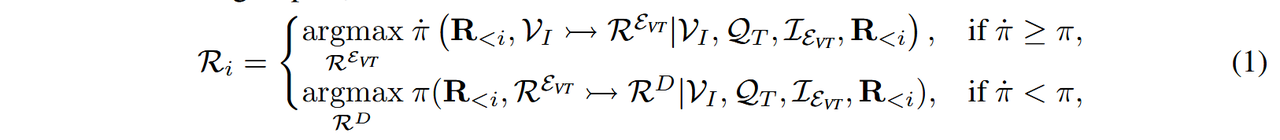
其中,RD 表示根据 Ri 推导的推理步骤 [57] 并从 REVT 中获取视觉信息。函数 π ̇ (·) 表示生成视觉思维的概率,π(·) 表示生成推导推理步骤的概率。符号 x ↣ y 表示推理信息从 x 流向 y 的推理步骤 y。
2.2 视觉思维的类别
视觉思维可以根据MCoT的不同变体以不同的形式表达:(1)在生成基于文本的推理的T-MCoT中,表现为文本表达;(2)在生成跨模态推理的I-MCoT中,表现为视觉表达。
2.2.1 文本多模态链式推理 (T-MCoT)
我们首先在T-MCoT中定义视觉思维,即模型将视觉思维生成为文本标记。如图1 (a) 所示,传统的T-MCoT从多模态输入中生成仅包含文本的输出,将视觉思维表示为EVT = Etext。形式上,视觉思维可以表达为:
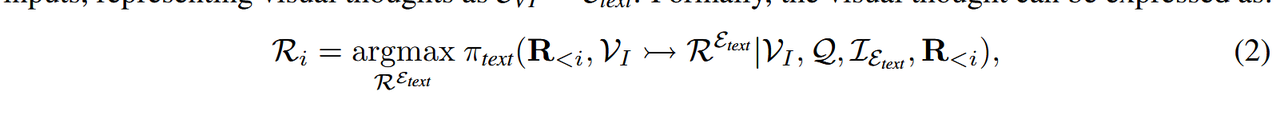
其中,πtext(·) 表示从文本标记中生成推理 REtext 的概率。
表达式 1:自然语言 (N-LANG) 通过自然语言表达(例如基于问题描述图像)促进有效的视觉信息传递,通过更丰富的视觉描述增强 LVLMs 中的视觉-语言对齐 [2, 12, 26],如图 3(a) 所示。其推理过程可以形式化地定义为:
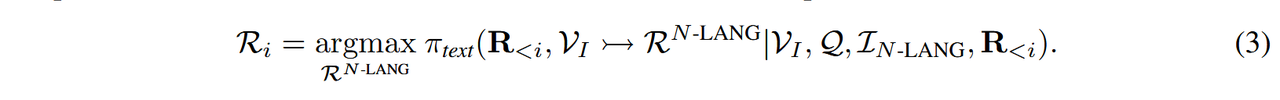
为了实现N-LANG,我们提示LVLMs生成图像描述作为推理的前置步骤。表达式2:结构化语言(S-LANG)[5]在数学领域中通过将结构化语言有效地融入推理流程[38, 13, 16],如图3(a)所示,已表现出优于传统MCoT推理的性能,其形式化表达为:
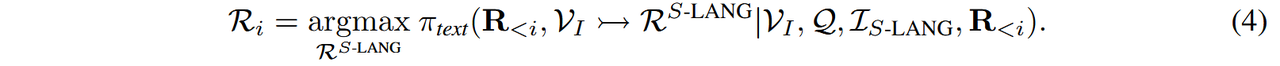
为了研究S-LANG视觉思维作为表达视觉思维的一种媒介,我们通过提示LVLMs从输入查询生成场景图来实现这一点,然后利用该场景图进行推理。
2.2.2 交错多模态思维链(I-MCoT)
然后,我们通过视觉表达引入了MCoT,表明图像标记是视觉思维的重要组成部分。如图1(b)所示,I-MCoT框架通过将图像编辑和生成整合到推理过程中,扩展了传统的T-MCoT,从而使得视觉思维能够通过图像传达。其数学表示为: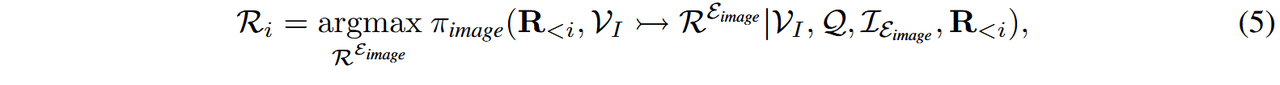
其中,πimage(·) 表示模型结合基于图像的推理步骤的概率。
表达式 3:编辑图像(E-IMG)处理原始图像并执行各种视觉操作,例如定位 [23]、深度估计 [48] 和分割 [35]。通过传递图像标记,E-IMG 增强了LVLMs(大规模视觉语言模型)对视觉数据的解释能力,从而提高了推理能力,如图3(b)所示,定义为:
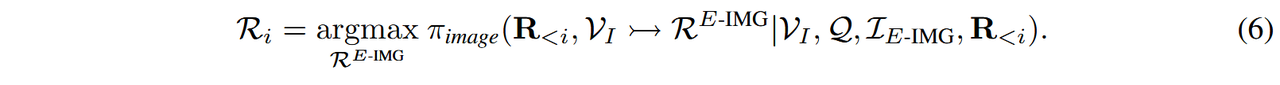
为了探索E-IMG视觉思维,我们通过使用视觉工具提供编辑过的图像给LVLMs,使其能够将编辑结果融入到后续推理中。
表达4:生成图像(G-IMG)需要促使生成模型基于LVLMs的进展生成逻辑相关的图像[1, 9, 43, 8],如图3(b)所示,其定义为:
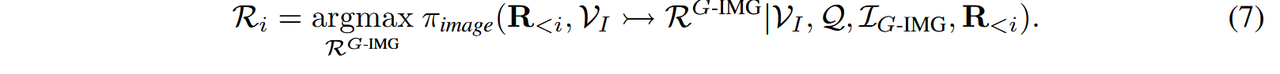
为探索G-IMG,我们使用DALL-E 3 [1]作为视觉思维的工具,基于输入查询生成新颖图像,这些图像随后被用作补充输入以辅助推理。
3 视觉思维有效性验证
整合视觉思维对于MCoT在图像和文本表达中的有效性至关重要。为验证这一点,如图4(a)所示,我们比较了系统在三种条件下的性能:(1)“图像形式的视觉思维”,即原始I-MCoT,包含交错的图像和文本推理;(2)“无视觉思维”,即清空视觉思维缓存,迫使模型重新分析输入图像;(3)“文本形式的视觉思维”,即使用I-MCoT生成的图像描述恢复缓存。如图4(b)所示,结果表明一个一致的趋势:省略
视觉思维导致准确性下降(甚至比仅从查询推理的效果更差),而将其纳入模型则能一致地提高推理性能。这些发现强调了视觉思维在传递视觉信息和提升模型准确性方面的重要作用。不同复杂度条件下,图像形式的视觉思维始终优于文本形式的视觉思维。由于图像模态在传递视觉信息方面的内在优势,图像形式的视觉思维可以比文本形式的视觉思维更有效地促进类似缓存的视觉逻辑传播,从而以更高的效率触发后续的推理过程。如图 4(b) 所示,结果表明,在各种复杂性场景下,图像形式的视觉思维始终优于文本形式的视觉思维,尤其是在高难度场景(CoMT-Selection 上为 47.83%)中,其改进更为显著。这表明图像形式的视觉思维在传递详细视觉信息方面提供了更优质的通道。
视觉思维代表了一种超越简单图像描述的推理过程,用于传递视觉信息。与普通的图像描述不同,视觉思维提供了一种更类似缓存的功能,在推理过程中动态整合详细的视觉线索。通过连续的推理步骤,视觉思维不断演变,涵盖视觉信息和上下文逻辑以支持后续任务。如图 4(c) 所示,在简单场景中,具有视觉思维的模型表现与仅使用描述的基线模型相当。然而,随着场景复杂性的增加,仅使用描述的模型准确性下降,呈现出“无视觉思维”(w/o visual thoughts)的表现。此外,当简洁的描述忽略了重要细节时,视觉思维能够将性能提升超过 7%,显示出其在传递视觉信息方面对 MCoT 的强大作用。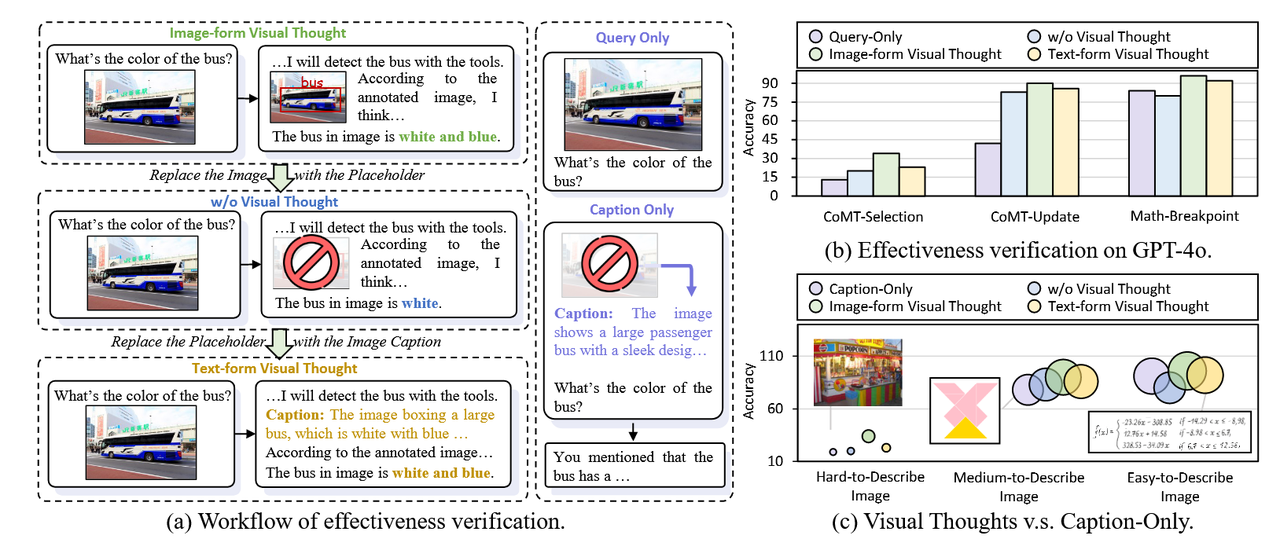
4 不同类别视觉思维的探索
基于初步验证中观察到的视觉思维的有效性,我们将进一步对视觉思维的四种经典表达进行全面评估。
4.1 这些不同的视觉思维都有效吗?
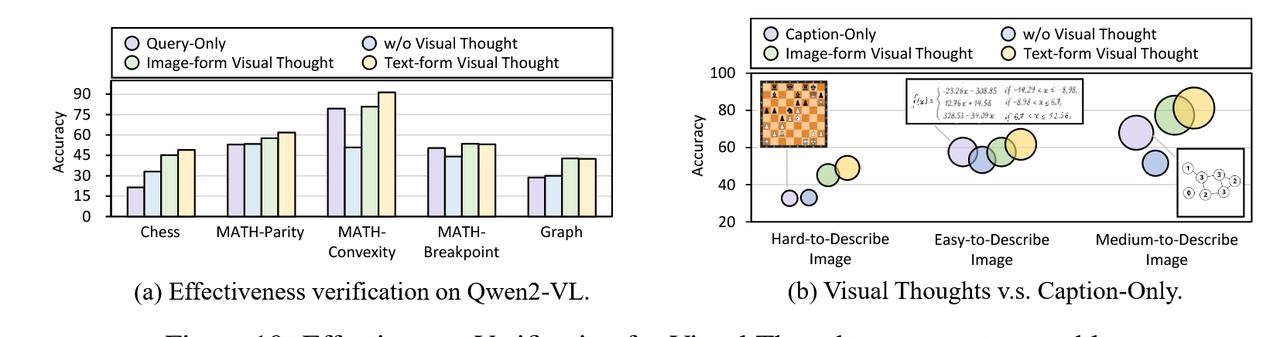
明确地将视觉思维与不同的表达方式相结合可以提升几乎所有LVLM的性能。如表1中的结果所示,与未添加额外指令的无视觉思维表达(w/o VT expression)相比,结合视觉思维的四种推理策略在几乎所有LVLM的不同任务中均实现了性能提升,这表明视觉思维在增强MCoT性能方面的有效性。需要更复杂视觉操作的任务可以从视觉思维中获益更多。进一步分析(如图5所示)表明,视觉思维在CoMT中带来了最显著的性能提升。该基准主要关注复杂的多模态操作,例如推理过程中的视觉删除、选择和更新,而非其他感知任务。研究结果表明,在复杂场景中,视觉思维可以显著增强LVLM的推理能力。T-MCoT在粗粒度感知任务中表现出卓越的推理能力,而I-MCoT在需要细粒度视觉操作的场景中表现优异。此外,我们研究了视觉思维在T-MCoT和I-MCoT中在不同场景下的传输效率。如表1所示,T-MCoT在粗粒度感知任务(例如MMVP、V*Bench-position)中表现更为出色,而I-MCoT在细粒度任务(例如V*Bench-attributes)和需要视觉操作的任务(例如M3CoT、CoMT)中实现了更高效的传输。因此,我们应根据任务的不同特征选择不同类别的MCoT。
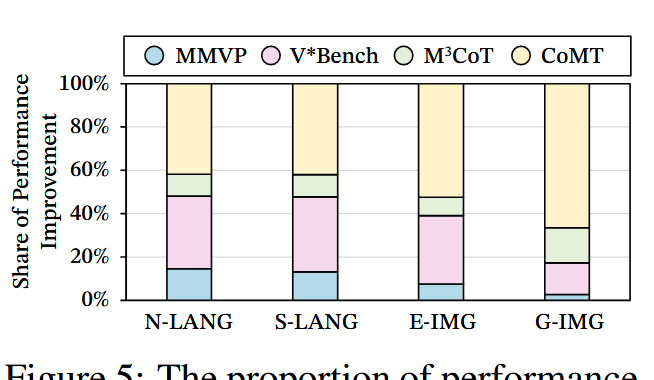
视觉化思维与视觉化表达在推理成本上比文本表达更高。为了比较四种视觉化思维表达的推理成本,我们计算了每种表达的响应中的平均文本标记数量以及生成的图像标记的平均数量。如表 2 所示,N-LANG 和 S-LANG 的平均文本标记数量略高,特别是 S-LANG 需要大量结构化片段。然而,对于 E-IMG 和 G-IMG,由于包含更多图像,平均图像标记数量较高,这显著增加了 LVLM 的推理负担,无论是在时间还是成本方面,这表明与文本表达相比,推理成本更高,从而极大地限制了推理效率。
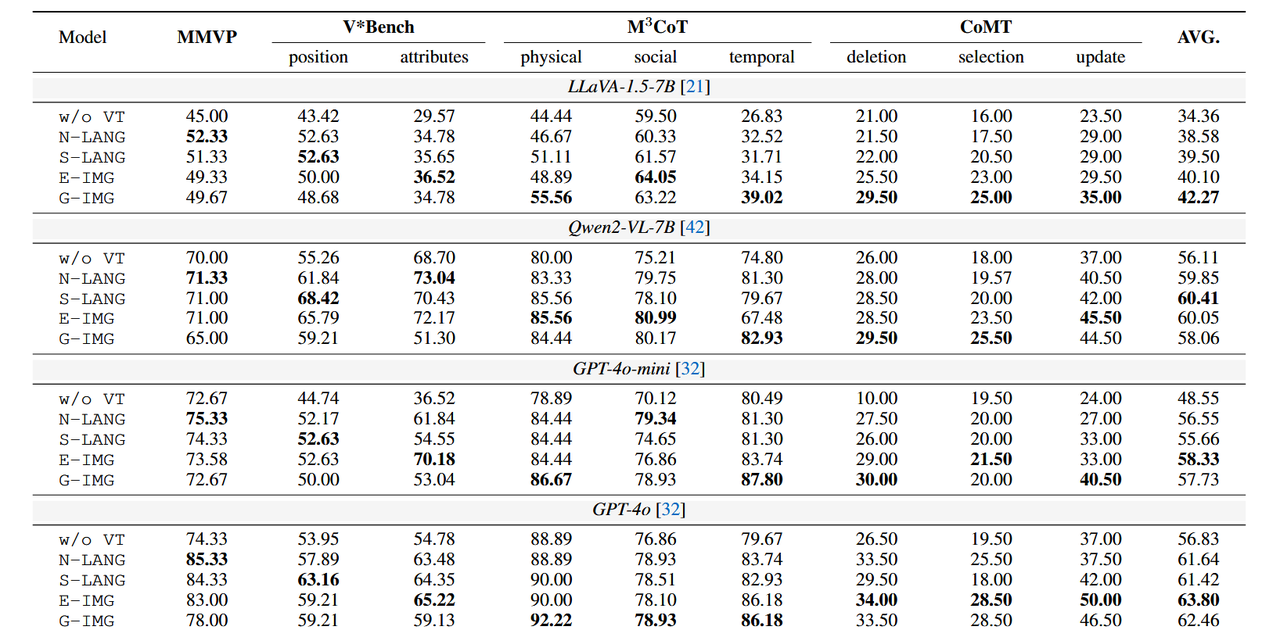
表 1:各种 LVLM 的主要结果。加粗内容表示每个 LVLM 中的最佳性能。w/o VT 指在没有额外视觉思维的情况下提示 LVLM。
4.2 不同的视觉思维在哪些场景中表现得更好?
N-LANG 在粗粒度、面向感知的推理任务中表现出色。当需要对整个场景进行快速概览时,N-LANG 使用自然语言将视觉输入转换为高层次的语义线索,并高效地提取宏观特征。如表1所示,在MMVP基准测试中,当涉及辨识显著目标时,N-LANG 首先识别出如“蝴蝶”这样的元素,指导后续分析并在粗粒度感知中取得顶级成绩。 以无固定格式的自然语言描述图像中与任务相关的视觉信息,将视觉内容转化为人类可理解的文本
S-LANG 在对象关系推理方面表现优异。S-LANG 将输入图像转换为详细的场景图,从而可以精确地建模空间和语义关系。如表1中V*Bench-position基准测试所示,S-LANG 不仅识别出如“桌子”和“椅子”这样的实体,还能精确推断它们的相对位置,从而奠定其在关系推理任务中的顶尖表现。 以固定格式的结构化文本(如 JSON、Scene Graph)编码图像中的物体、属性及关系,将视觉信息转化为 “机器可解析的结构化数据”,本质是 “视觉信息的符号化建模”。
E-IMG 在精准图像分析中取得了强劲成绩。E-IMG 模仿人类编辑流程,优化视觉内容以辅助细粒度特征检测。如表1所示,在V*Bench-属性通过放大和注释感兴趣区域,提高了属性预测的准确性。这种详细的关注使其在模型之间达到最高的平均性能。G-IMG非常适合通过迭代图像生成进行多步推理。通过视觉工具对原始图像进行编辑操作(如裁剪、标注、分割、深度估计),生成 “聚焦关键区域的局部图像”,本质是 “视觉信息的空间筛选与增强”。
G-IMG动态生成图像以优化和测试推理假设,从而实现自适应视觉思维。如表1所示,在需要多轮交互的M3CoT中,它将逻辑步骤与新的视觉内容相结合,以加深对复杂概念的理解。这种灵活的生成式管线在长期、多轮推理场景中表现出色。 通过生成模型(如 DALL-E 3)根据任务需求生成新图像(如函数图像、逻辑示意图),将 “抽象视觉逻辑转化为具象图像”,本质是 “视觉信息的逻辑化生成”。
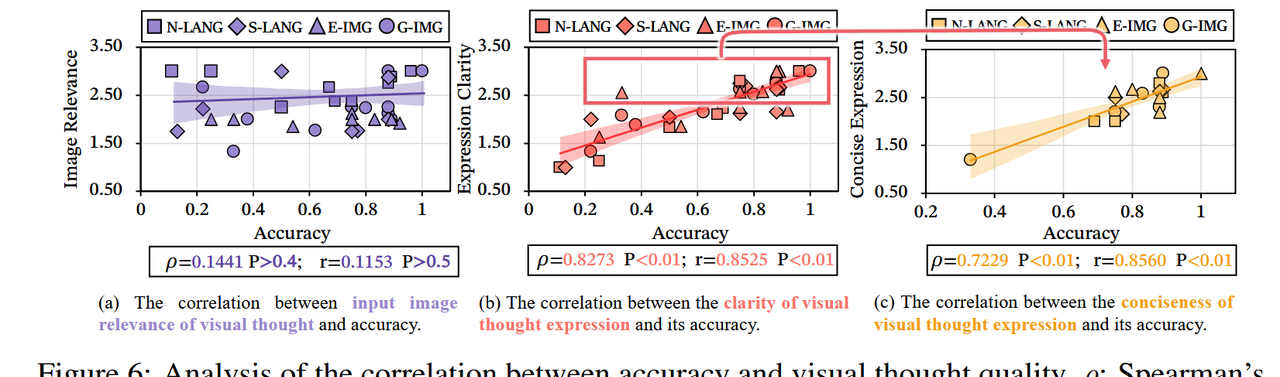
图6:精确性与视觉思维质量之间相关性的分析。ρ:斯皮尔曼相关系数;r:皮尔森相关系数;P:相关假设的p值。
4.3 不同视觉思维效果的核心影响因素是什么?
视觉思维充当了提炼视觉信息的缓存,而非原始图像的忠实复制品。一个关键问题是,视觉思维是否能够准确保留原始图像的全部内容,充当缓存而非外部存储。为了探索这一点,我们通过人工评估视觉思维的保真度,采用0–3分的评分标准,并检查其与模型准确性的相关性。如图6(a)所示,Spearman相关系数(ρ)和Pearson相关系数(r)均低于0.15(P > 0.4),这表明没有显著关系。这表明视觉思维更像是视觉信息的浓缩缓存,而非原始图像的直接替代。视觉思维提供了更清晰、更易解释的视觉逻辑表达,从而更有效地检索与推理相关的信息。与直接的图像表示不同,视觉思维并不旨在重建原始图像,而是像计算机缓存一样提炼并传递跨模态视觉逻辑。为了评估视觉思维的有效性是否取决于视觉逻辑表达的清晰度,我们通过人工对逻辑表达的清晰度进行0–3分的评分,并检查这些评分与模型准确性之间的相关性。如图6(b)所示,Spearman和Pearson相关系数均超过0.8(P < 0.01),表明两者之间存在显著的正相关。这些发现表明,视觉逻辑表达越清晰,模型越能有效利用存储在视觉思维缓存中的信息进行推理。精炼的视觉逻辑表达进一步增强了视觉推理的有效性。除了清晰度之外,我们还研究了其他影响视觉思维有效性的因素。我们假设更紧凑的视觉表达——剔除冗余或无关元素——能够在推理过程中更快、更准确地从内部视觉缓存中检索信息。为此,我们对每种视觉表达的简洁性进行人工评分,反映其传递所需的视觉信息和逻辑的效率,并检查这些评分与模型性能之间的关系。如图6(c)所示,推理准确性与简洁性强烈相关,这表明视觉思维的有效性不仅由清晰度决定,还受到其视觉逻辑紧凑性的增强。
5 视觉思维背后的五个内部理性
为了理解视觉思维的原理,我们研究了视觉信息如何通过注意力机制和在LVLM内部结构中的信息流分析进行传递。
5.1 视觉注意力分析
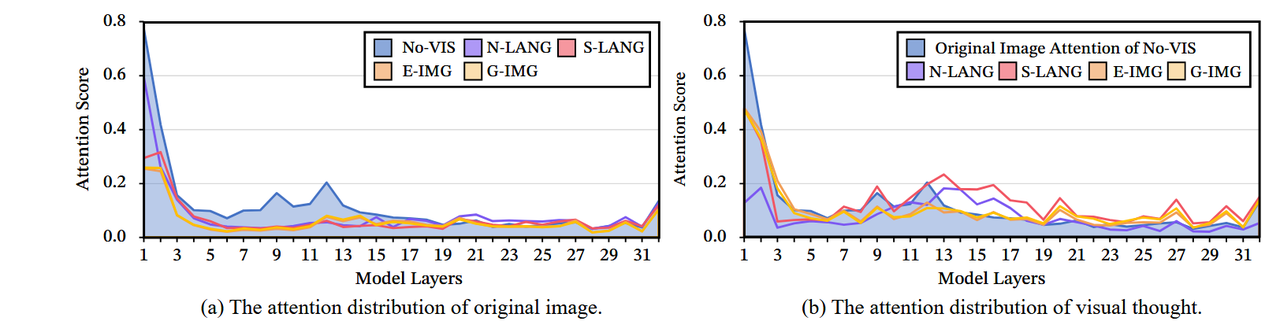
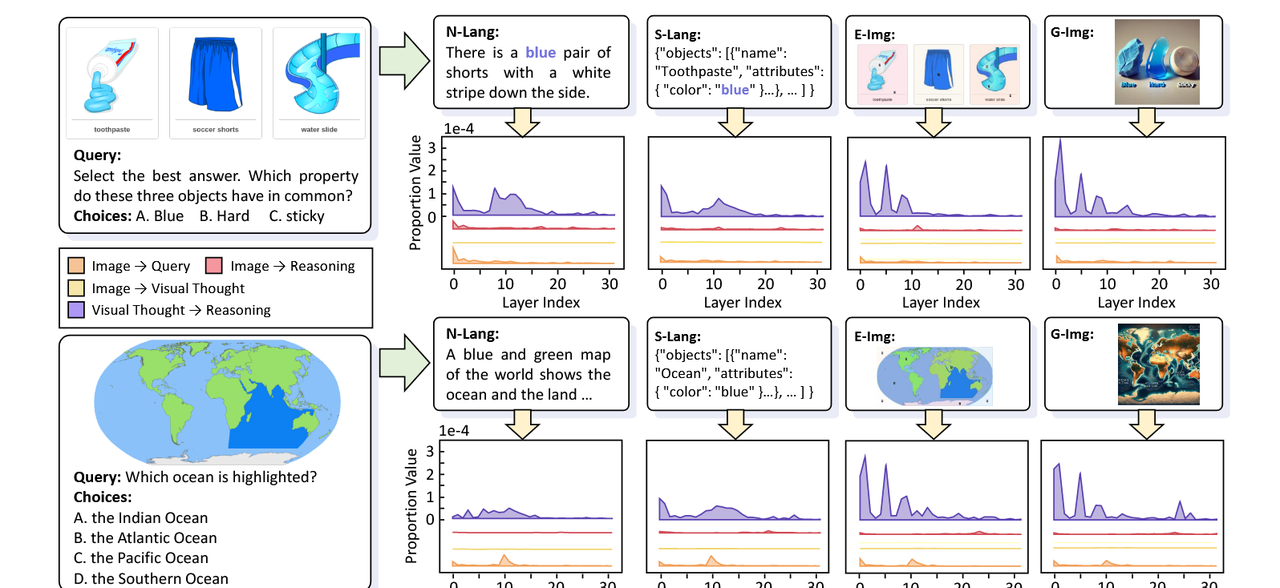
在推理过程中,原始图像的注意力将分散为视觉思维。为了研究视觉思维在大规模视觉语言模型(LVLMs)中的内部机制,我们首先分析了模型视觉思维的注意力分布变化。如图7(a)所示,在这种设置下,在无视觉思维(No-VIS)的情况下,模型对图像表现出高度关注,而在具有视觉思维的推理过程当中,对原始输入图像的注意力在所有视觉思维表达中显著减少。如图7(b)所示,模型将注意力从原始输入图像转移到各种视觉思维上。这种重新分配使得视觉信息可以流动,从而支持整个逻辑框架。视觉思维能够比原始图像本身更深入地传递视觉信息。更有趣的是,如图7(b)所示,我们在模型的更深层观察到一个显著现象:在未结合视觉思维的情况下,对原始图像的注意力在第12层之后急剧下降,几乎为零。相反,当包含视觉思维时,对所有表达的注意力在第12层之后显著增加,甚至保持在与早期层级类似的水平。这一发现表明,视觉思维在将视觉信息转移到模型的深层中起着关键作用,从而促进增强的跨模态交互并支持更复杂的逻辑推理。
5.2 可视化信息流分析
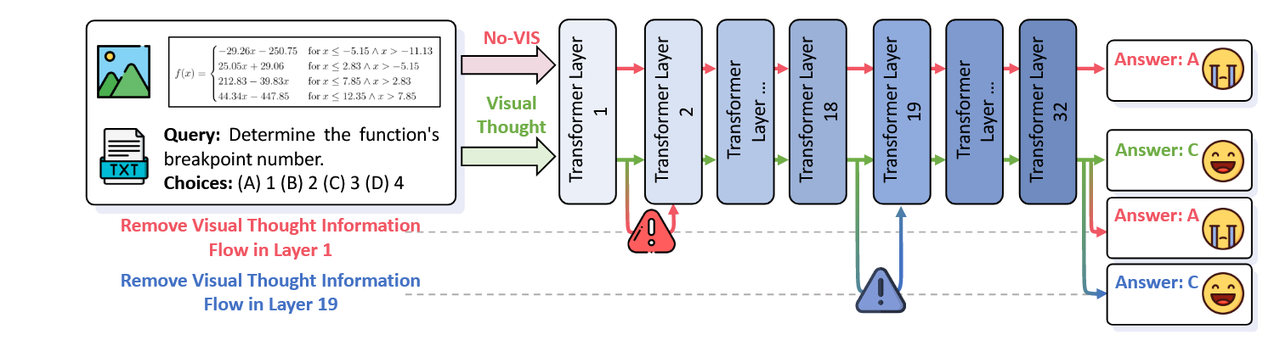
输入问题会从视觉思维缓存中查询视觉信息。随后,我们手动干扰模型的内部信息流,以理解和量化视觉思维对MCoT的缓存式影响。如图8所示,在没有视觉思维(No-VIS)的情况下,模型错误地选择了选项A,而引入视觉思维后,它能够正确选择选项C。此外,在19层之前拦截从查询到视觉思维缓存的信息流将显著阻止模型选择正确答案,而中断来自图像的信息流对推理没有影响。这些发现表明,从视觉思维缓存中查询视觉信息是增强模型预测的关键机制。从视觉思维缓存中检索的视觉信息将进一步传递到跨边界和更深层的模型用于高级推理过程。 与下文“原始像素 → 视觉思维 → 更深层次的推理”对应
此外,我们还检查了模型内部定向信息流的分布,重点关注输入图像与问题之间的流动、输入图像与视觉思维之间的流动、图像与推理之间的流动,以及视觉思维与推理过程在不同层次之间的流动。如图9所示,我们的研究结果表明,从视觉思维到推理阶段的信息流远强于从图像到推理的直接流动。这强调了视觉思维在中介和组织视觉数据方面的重要作用,将其优化用于推理。通过这种方式,视觉思维使模型能够更有效地利用视觉信息,从而产生更加准确和一致的文本输出。
原始图像的信息主要流向视觉思维。如图9所示,大多数图像的输入信息在推导步骤中最初被传递到视觉思维,而不是直接进入推理过程,然后才被传递到推理阶段。阶段。这表明几乎所有图像衍生的信号在到达更深层次的推理之前都会经过视觉思维。这一两阶段过程(原始像素 → 视觉思维 → 更深层次的推理)强调了视觉思维作为关键桥梁的作用,使LVLMs能够生成更好的MCoT。
6 相关工作
链式思维(Chain-of-Thought, CoT)[45, 17, 34] 的发展引发了对其扩展到多模态推理的研究 [25, 44, 14, 41, 31]。在此背景下,Zhang 等人 [53] 正式引入了多模态链式思维(Multimodal Chain-of-Thought, MCoT)的概念,并采用了一个双阶段框架,区分了推理生成和随后的答案表述。这些研究属于文本式 MCoT(Textual-MCoT, T-MCoT)的范畴,即多模态输入,但输出仅为文本。Zheng 等人 [54]、Yao 等人 [49] 通过步骤解耦改进了多模态交互;而 Wei 等人 [46]、Chen 等人 [4] 引入了多跳推理以捕捉更复杂的关系。此外,Chen 等人 [6] 扩展了 T-MCoT,用于常识推理任务的评估。
由于 T-MCoT 仅文本输出的局限性,更多文献探索了使用图文交错输出范式的 MCoT(Image-Text Interleaved MCoT, I-MCoT)[27, 28]。Hu 等人 [15]、Zhou 等人 [55]、Su 等人 [37] 探索了使用视觉专家模型为输入图像进行注释以支持 I-MCoT。此外,Cheng 等人 [7] 提出了一个包含四种任务类型的基准,用以评估大型视觉语言模型(LVLMs)的 I-MCoT 推理能力。尽管大多数工作依赖外部执行器或视觉专家模型,Gao 等人 [11] 直接从原始输入中提取图像片段用于交错图像,Li 等人 [19] 则通过微调具有多模态生成能力的 LVLMs 来实现 I-MCoT 推理。
尽管在 T-MCoT 和 I-MCoT 领域取得了进展,但少有研究分析 MCoT 背后改善性能的统一机制。我们将这些性能提升归因于视觉思维(visual thoughts),即从输入图像中传递视觉信息的推理步骤。我们进一步提出了四种策略,这些策略代表了不同模态和整合视觉思维的方法,并分别对此四种策略进行了全面分析,希望这些发现能为未来 MCoT 研究提供实践性和系统性的指导。
7 讨论
局限性
为了方便变量控制和简化分析,我们排除了多轮视觉思维互动,这应在未来的复杂场景中进行探索。此外,由于在任意到任意的LVLM推理过程中生成I-MCoT存在困难,通常导致逻辑质量较差,我们转而使用DALLE调用G-IMG。
更广泛的影响
本研究首次对MCoT背后的统一机制进行了全面调查。我们期望这项工作能够成为一个有价值的参考,并指导未来对MCoT机制的研究。在社会影响方面,这项工作可能有助于推进对多模态AGI系统可解释性的理解。
8 结论
在本研究中,我们首次提出了视觉思维的概念,这一概念能够促进从输入图像到推理过程及更深层变换器层次的视觉信息传递。视觉思维对于MCoT方法的有效性至关重要。我们还提出并评估了四种表达视觉思维的策略,展示了它们在提升MCoT性能中的作用。此外,我们分析了视觉思维的基本原理,以更好地理解其功能。我们希望这项工作能够推动对MCoT背后统一机制的理解,并为未来研究中的进一步创新提供启发。
附录
A 实验设置
模型设置
我们使用四种模型进行所有实验,包括 LLaVA-1.5 [21]、Qwen2-VL [42]、GPT-4o-mini [32] 和 GPT-4o [32]。对于 GPT 模型,我们将温度参数调整在 [0,2] 范围内;对于开源模型,我们将温度参数调整在 [0,2] 范围内。此外,所有开源模型的推理均在 2 台 A6000 48G 设备上完成。
基准设置
我们从数学和常识两类任务中选择基准。对于数学任务,我们选择 IsoBench [10],其中包括象棋、数学、图表等任务。对于常识任务,我们选择数据集 MMVP [39]、V*Bench [47]、M3CoT-Commonsense [4] 和 CoMT [7],这些数据集评估 LVLMs 的能力,如视觉关联和目标检测、精细识别以及链式推理(CoT reasoning)。
B 视觉思维的有效性验证
在本实验部分中,我们使用 CoMT [7] 和 IsoBench [10] 数据集。
B.1 视觉思维设置
对于图片形式的视觉思维生成的设置,对于 CoMT,我们利用基准中提供的交替模式推理过程,构建一个结合图片形式视觉思维的推理过程,并将其作为上下文提供给模型进行答案预测;对于 IsoBench,我们利用数据集中包含的函数图作为图片形式的视觉思维,将其嵌入到基于模板的推理过程中,作为上下文。随后,我们通过修改生成的图片构建两个不同的变体:在 w/o Visual Thought 设置中,图片被替换为 <image> 占位符;在 Text-form Visual Thought 设置中,图片被替换为根据查询生成的相应文字说明,由 GPT-4o [32] 提供。
在 Caption Only 设置中,我们使用 GPT-4o [32] 直接从原始输入图片生成文字描述,不考虑问题。这些生成的文字描述随后作为上下文提供给模型进行后续的答案预测。
B.2 图像分类
在本节中,我们探讨了图像的文本描述复杂性如何影响视觉推理的有效性。我们首先提示模型生成尽可能精确的文字描述,并通过每个描述中令牌数量来量化描述难度。与常识预期以及我们的手动标注一致,表现“找不同”场景的图像是最难描述的,因此被标注为难描述(Hard-to-Describe);与此相比,与七巧板相关的图像呈现出中等难度,被标注为中等描述(Medium-to-Describe);而显示通过光学字符识别(OCR)检测出的数学函数的图像则需要最少的令牌,因此被标注为容易描述(Easy-to-Describe)。
B.3 更多结果
除第三节中的探讨,我们进一步研究了将视觉思维整合到需要空间想象的纯文本问题中的有效性。在这类设置中,视觉思维用于传递想象的空间域中解决文本问题所必需的视觉信息。具体来说,我们选择从 IsoBench 中的象棋、函数和图表任务,并使用 Qwen2-VL 模型作为实验模型。我们使用 VisualSketchpad [15] 来生成包含图片形式视觉思维的推理过程,同时基于输入文本数学表达生成 Caption-Only 的文字描述,其他设置保持不变。
整合视觉思维对于 MCoT 在图像和文本表达中的有效性至关重要。如图 10(a) 所示,与第三节的结论一致,缺少视觉思维会导致准确率显著下降(甚至比仅依赖查询本身更差)。这一结果强调了视觉思维在传递视觉信息和提高模型性能中的关键作用。
视觉思维在更复杂的场景中比文字描述能够更高效地编码视觉信息。如图10(b)所示,在简单场景中,当描述较为直白时,效率提升较为有限(7.24%)。在中等复杂度的场景中,效率提升达到19.54%。在高度复杂的图像中,由于简洁文字描述往往力不从心,视觉思维提供了超过50%的效率提升。这些研究结果表明,视觉思维随着图像复杂度的增加具有良好扩展性,并且为传递详细视觉信息提供了更优的方式。
D 视觉思维的内在逻辑
在第五节中,我们分析了MCoT传递视觉信息的内在机制,重点从两个方面进行探讨:注意力机制和信息流动。
D.1 视觉注意力分析
在本节中,我们使用LLaVA-1.5-7B [21]作为实验模型,以分析其推理过程中的注意力分布,并从ScienceQA [25]中随机选取一个样本作为案例研究。具体而言,我们比较了两种输入设置:(1) 仅包含多模态查询,(2) 包含多模态查询和视觉思维。对于每种设置,我们分别获取最后一个token到输入图像和视觉思维在每一层Transformer中的注意力权重。
我们将A(l,h) i,j定义为第l层中第h个头部的令牌i关注令牌j的注意力权重,注意力权重的提取过程可以表示为:

其中,̄a(l) last→k 表示提取的目标注意力权重,last 表示最后一个标记的索引,k 表示目标标记的索引,H 表示头的数量。如图 7 所示,结果表明,加入视觉思维会导致注意力从原始图像转向视觉思维。此外,视觉思维继续将视觉信息传递到变换器的更深层次。
D.2 可视化信息流分析
在本节中,我们同样使用LLaVA-1.5-7B [21]作为实验模型,并从ScienceQA [25]中抽取样本数据,以研究MCoT中内部信息流的作用。具体而言,我们进行了两项分析:注意阻断分析和基于显著性的信息流分析。
D.2.1 注意力阻断分析
我们通过在选定的转换器层中将特定标记之间的注意力掩码设置为-inf [40, 50],手动阻断它们之间的信息流。如图8所示,阻断查询与视觉思维之间的信息流会导致模型选择一个错误的选项,而这个选项在其他情况下本来会被正确预测出来。该结果强调了查询与视觉思维之间信息流对最终答案预测的重要影响。
D.2.2 基于显著性的 信息流分析
我们计算显著性分数 [36] 以评估不同信息流对答案预测的相对重要性 [40, 50]。计算过程利用泰勒展开 [29] 处理注意力矩阵元素:
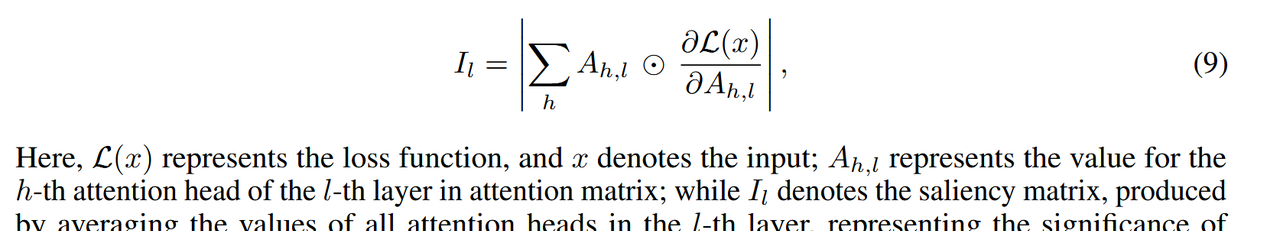
这里,L(x)表示损失函数,x表示输入;Ah,l表示注意矩阵中第l层的第h个注意头的值;而Il表示显著性矩阵,通过平均l层中所有注意头的值生成,表示信息流的重要性。 如图9所示,视觉思维与推理过程之间的信息流在引导模型获得正确答案方面起着关键作用,其贡献显著大于图像到推理路径的影响。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...







![[理论篇-10]AI 工作流(AI Workflow)—— 让 AI 像流水线一样干活](https://www.dunling.com/img/8.jpg)



