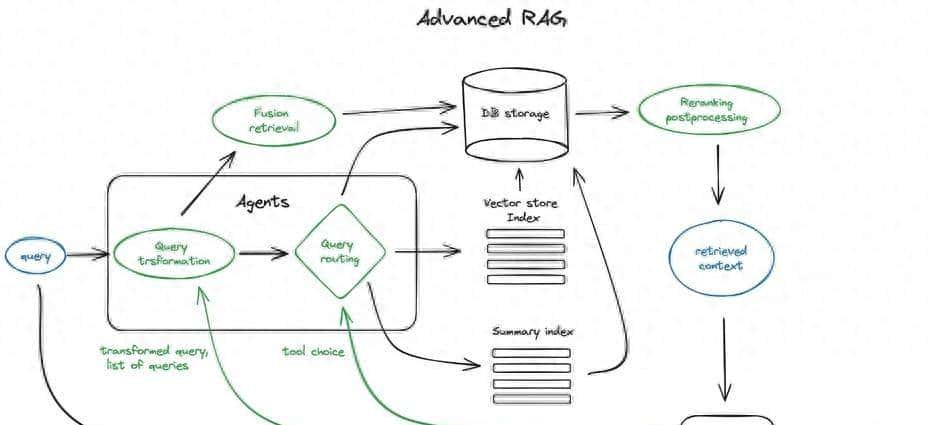
。推理优化的重大性大模型推理优化是解决大规模语言模型(LLM)高效推理的关键。以540B参数的GaLM为例,其推理成本超级高,如果无法优化成本,模型的普惠性将大打折扣。大模型的推理需求主要可分为两类:在线推理和离线推理。在线推理注重低延迟和严格的响应时间,而离线推理则侧重高吞吐和低成本。 推理过程的分解大模型推理可以分为两个阶段:填充(prefill)和解码(decoding)。其中,prefill阶段计算密集,解码阶段则涉及大量内存访问。解码阶段特别难以优化,由于每次只能解码一个token,同时需要不断访问累积的缓存(KVCache),这使得加速受限于计算卡的带宽。 并行推理的必要性由于模型参数庞大,单个加速卡无法存下完整模型,必须通过并行推理来提升效率。尤其是对于延迟要求较高的任务,增加加速卡的数量是提升算力和带宽的必要手段。 优化策略与经验总结大模型推理优化涉及多个方面,包括算子优化、量化加速、内存管理、Batching策略等。本文重点讨论并行策略,提供了一套工程化的原则,协助研究者在不同的模型规模和应用需求下,选择合适的并行策略。例如,在处理540B参数模型时,通过64个TPU v4芯片进行解码时,每个标记的延迟为29毫秒,能够同时实现高效的离线和在线推理。 并行策略的符号化抽象为了更好地指导推理工程的优化,文章提出了一种Partitioning Framework,协助优化并行策略的选择。通过符号化抽象,推理的并行策略可以更直观地表明,从而提升系统的效率。






© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章












大模型推理加速技术的学习路线在这里!。推理优化的重要性大模型推理优化是解决大规模语言模型(LLM)高效推理的关键。以540B参数的GaLM为例,其推理成本非常高,如果无法优化成本,模型的普惠性将大打折扣。大模型的推理需求主要可分为两类:在线推理和离线推理。在线推理注重低延迟和严格的响应时间,而离线推理则侧重高吞吐和低成本。 推理过程的分解大模型推理可以分为两个阶段:填充(prefill)和解码(decoding)。其中,prefill阶段计算密集,解码阶段则涉及大量内存访问。解码阶段特别难以优化,因为每次只能解码一个token,同时需要不断访问累积的缓存(KVCache),这使得加速受限于计算卡的带宽。 并行推理的必要性由于模型参数庞大,单个加速卡无法存下完整模型,必须通过并行推理来提升效率。尤其是对于延迟要求较高的任务,增加加速卡的数量是提升算力和带宽的必要手段。 优化策略与经验总结大模型推理优化涉及多个方面,包括算子优化、量化加速、内存管理、Batching策略等。本文重点讨论并行策略,提供了一套工程化的原则,帮助研究者在不同的模型规模和应用需求下,选择合适的并行策略。例如,在处理540B参数模型时,通过64个TPU v4芯片进行解码时,每个标记的延迟为29毫秒,能够同时实现高效的离线和在线推理。 并行策略的符号化抽象为了更好地指导推理工程的优化,文章提出了一种Partitioning Framework,帮助优化并行策略的选择。通过符号化抽象,推理的并行策略可以更直观地表示,从而提升系统的效率。#深度学习#大模型#强化学习#知识图谱#时间序列分布预测