
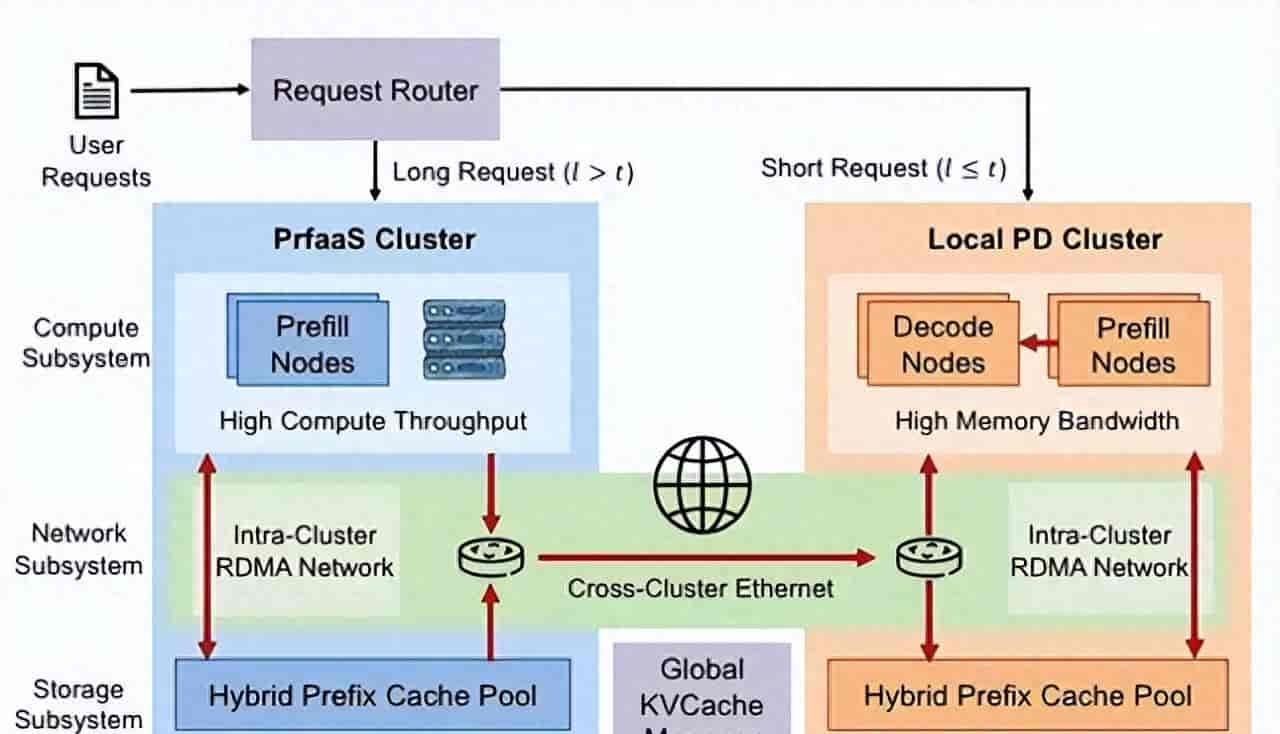
大模型推理效率长期受制于 Prefill 与 Decode 阶段的耦合限制:
传统架构中,这两个阶段必须运行在同一数据中心,否则会因高带宽缓存(KV Cache)传输瓶颈而陷入性能瓶颈。
但随着长上下文需求爆发式增长,这种模式显然难以应对:
- KV Cache 随上下文线性增长,高速依赖专有 RDMA 通道。
- 不同硬件资源无法灵活组合。
核心突破:PrFaaS — Prefill‑as‑a‑Service(预填充即服务)
该工作由 清华大学郑纬民院士团队 & 月之暗面 联合提出,核心亮点是:
✅ 彻底解耦 Prefill 与 Decode
Prefill 阶段可“卸载”到专用计算集群执行,再把生成的 KV Cache 通过普通以太网传回 Decode 节点。
✅ 支持 跨数据中心调度
只要是标准以太网带宽(如 100Gbps),就足够支撑 KV Cache 传输,这让原本只能在 RDMA 网络域内工作的 PD(Prefill‑Decode)架构变得跨机房可用。
为什么它如此关键?
传统 PD 架构瓶颈在于:
Prefill 与 Decode 强绑定在单个集群内
如果最适合做 Prefill 的算力芯片和最适合做 Decode 的带宽芯片不在一起,就无法联合使用
固定资源导致浪费严重、扩展性差
而 PrFaaS 的出现让:
计算资源可以跨地域灵活调度
硬件资源专业化扩展成为可能
长上下文场景下吞吐量与延迟表现显著提升
实测性能亮眼(可配图:性能对比表)
在典型混合注意力模型中对比:
|
指标 |
传统同构 PD 集群 |
PrFaaS‑PD 架构 |
|
吞吐量 |
— |
提升约 54% |
|
P90 延迟 |
— |
降低约 64% |
此外,跨数据中心传输仅用 13 Gbps 带宽,远低于 100 Gbps 以太网容量。
技术细节:新架构如何实现
PrFaaS 系统由三大子系统协同:
计算层
- Prefill 在高算力集群完成
- Decode 在带宽优化集群处理
网络层
- 集群内仍用 RDMA
- 集群间用普通以太网或云 VPC 连接
缓存层
- KV Cache 分为 “本地复用缓存” 与 “传输缓存”
- 动态调整调度策略,实现高效资源利用
这一组合使得原本算力资源“固化配比”的困局得以破解。
长上下文时代的推理新方向
随着大模型对长上下文支持的需求飙升,这项研究为:
✔ 大模型跨地域部署
✔ 异构硬件资源协同
✔ 大规模推理服务高效调度
提供了清晰可行的新路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。











[db:评论]