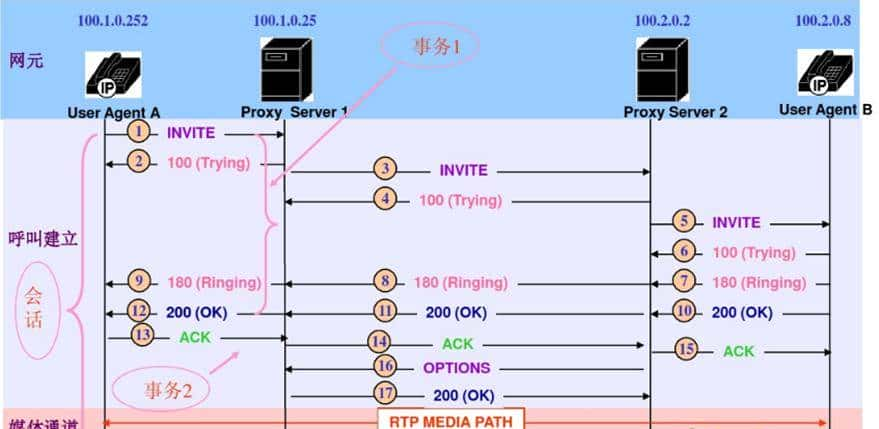
Embedding 模型是将文本、图像、音频等非结构化数据转化为低维稠密向量的核心 AI 模型,也被称作嵌入模型。它能捕捉数据的语义、特征与关联关系,让机器像人类一样理解信息的内在含义,是 RAG、语义检索、大模型微调、推荐系统的底层支撑,更是实现跨模态交互与智能推理的基础。
Embedding 模型的核心原理是语义编码与向量映射,核心过程分为三步。第一对输入数据做预处理,文本会进行分词、去停用词,图像会提取像素特征,统一数据格式后送入模型;接着通过 Transformer、CNN 等核心网络进行深度编码,挖掘数据的深层语义与特征关联,列如将 “电脑” 和 “计算机” 映射为高度类似的向量;最后输出固定长度的低维稠密向量,替代传统稀疏的独热编码,既节省存储成本,又能通过向量运算衡量数据间的关联度。
这类模型有三大核心特征,也是其适配各类 AI 场景的关键。一是语义保真性,向量的距离与数据语义类似度正相关,余弦类似度越高,代表信息含义越接近,可直接通过向量运算完成语义匹配;二是维度可控性,可生成 8 维、128 维、768 维等不同长度向量,低维适配轻量化场景,高维保留更细粒度特征;三是跨模态兼容性,多模态 Embedding 模型能将文本、图像等不同类型数据映射到同一向量空间,实现 “文本搜图”“图像描述” 等跨模态交互。
Embedding 模型的性能直接决定上层 AI 应用效果,主流模型分通用与垂直两类。通用模型如 BERT Embedding、Sentence-BERT,适配日常语义理解;垂直领域会基于通用模型微调,融入行业术语与场景特征,提升专业数据的编码精度。实际应用中,需根据场景选择向量维度,同时通过批量量化、索引优化提升检索与运算效率。
作为 AI 的 “语义翻译官”,Embedding 模型让机器实现了从 “识别数据” 到 “理解数据” 的跨越,是大模型、智能体、知识图谱等技术落地的必备基础,更是推动 AI 从单一任务处理向通用智能演进的核心支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...