快、爽、贵,但不是一句“干翻 Claude Code”。这是一篇从计划、构建、自检到 8 项验收的终端代理实测。
先把门票摆出来
先交代一下门票。我不是领了一个媒体体验码,也不是在朋友机器上摸了两下就来写评测。为了测 Grok Build CLI,我开了 SuperGrok Heavy。300 美元刷出去的时候,我的第一反应很朴素,最好是真的有点东西,不然这篇文章就只能叫《如何优雅地给好奇心交罚款》。

先把门票摆出来:这次不是媒体码,也不是隔空转述。
5 月 17 日晚上,我在终端里敲了一下 grok version,返回的是 grok 0.1.211。这就是我这次实测 Grok Build CLI 的起点。没有浏览器聊天框,没有复制粘贴代码,也没有让模型在网页里给我写一大段“你可以这样做”。它直接进了项目目录,读文件,改文件,跑测试,做自检,再把结果摊在终端里。
我本来对它没有太大期待。目前终端编码代理太多了,Claude Code、Codex CLI、Aider、Cursor,每个都说自己懂项目、会计划、能自动修。Grok Build CLI 如果只是多一个命令行入口,那没有什么好写的。可我跑完一个完整 Weather App 后,第一反应很不专业,却很诚实。
快,爽,贵。顺序不能反,贵是最后才开始疼。
先说结论:快、爽、贵
快不是跑分上的快。它给我的感觉是事情被连续推着走。先 inspect 项目,再出 plan,再改代码,再跑 verifier,再根据 verifier 的意见二次修,几个环节之间没有那种坐在终端前等它慢慢组织语言的烦躁。尤其是改完后自测、发现小问题、继续补修这一段,节奏很顺。
贵也是真的。xAI 官网目前写得很清楚,Grok Build 还在 early beta,入口给 SuperGrok Heavy 订阅者。订阅截图我也放在前面了,免得后面聊价格时像在讲都市传说。至于值不值这个钱,不能靠官网文案判断,得看它能不能替开发者少走弯路。
测试起点:终端里真实返回的版本、模型和协助信息。
看基本功:Weather App
我这次没有做一个很花的 SaaS,也没有让它生成一堆看起来高级的依赖。测试项目就是一个 Weather App。功能要求很普通,正由于普通,才适合看一个编码代理的基本功。城市搜索、Open-Meteo API、当前天气、5 日预报、摄氏华氏切换、最近城市、加载状态、空状态、错误状态,最后还要有 Vitest 测试和生产构建。

我看的不是单次生成,而是它能否把计划、构建、验证和修补串成闭环。
我先让它只做计划。
grok --permission-mode plan
--prompt-file prompt-plan-weather-app.md这一步没有改文件。Grok 先发现当前项目实则是 vanilla TypeScript starter,并非我以为的 React 模板。这个细节挺有意思。许多工具在这里会顺着用户的假设往下写,结果越写越歪。Grok 先把现状说清楚,然后给出改造方案,React 入口、组件、API 层、weather 工具函数、storage 工具函数、Vitest 配置,都列了出来。
第一轮只让它做计划,先确认项目现状,再谈怎么动手。
批准后,我让它真正开工。
grok --always-approve --check
--prompt-file prompt-implement-weather-app.md真正加分的是自检
它完成了主体代码,又跑了一轮 verifier。第一次 verifier 已经给了 PASS,可它自己依旧指出几个毛病。pnpm test 还是 watch 模式,不适合 CI;极窄移动端 forecast 卡片会挤;“Feels like”最好用真实 apparent temperature;README 也该补一段。这个地方比“它一次写了多少代码”更能说明问题。一个能写代码的模型许多,一个能在写完后继续挑自己毛病的终端代理,才开始像工具。
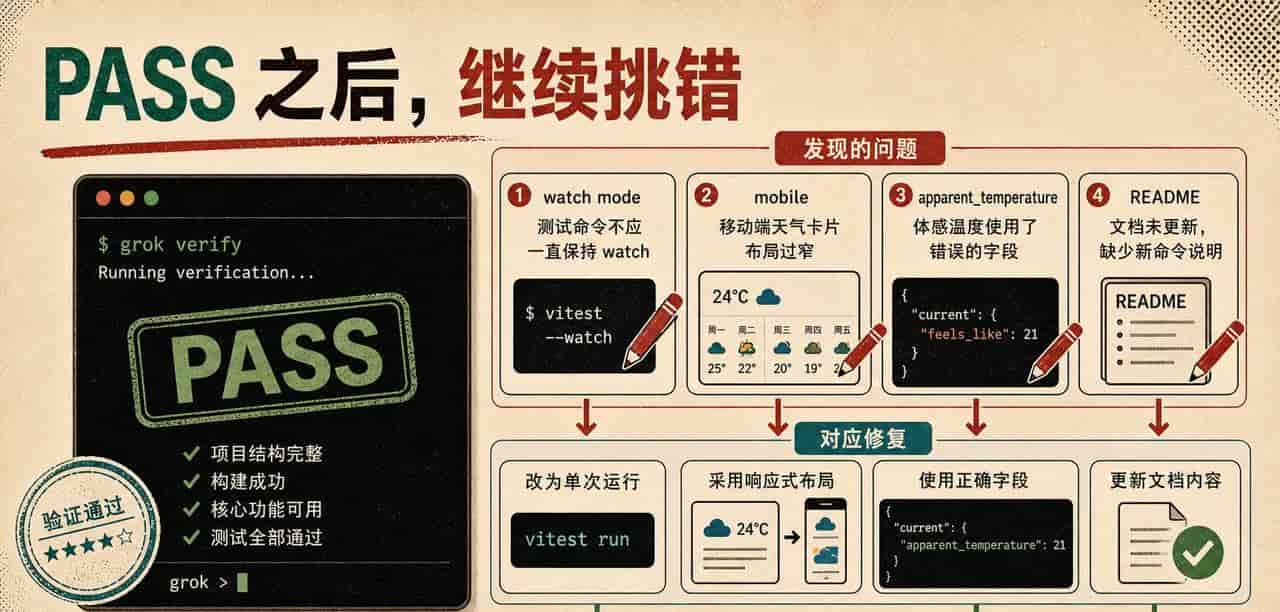
真正加分的是 PASS 之后仍能继续挑自己的毛病。
我又把这些问题丢回去。
grok --always-approve
--prompt-file prompt-fix-verifier-issues.md第二轮它把 test 改成 vitest run,补了 test:watch,调整了极窄屏样式,确认 apparent_temperature,删除没用的图标文件,还写了 README。最后我手动重新跑了一遍。
Test Files 2 passed (2)
Tests 18 passed (18)
vite v8.0.13 building client environment for production...
25 modules transformed.
built in 85ms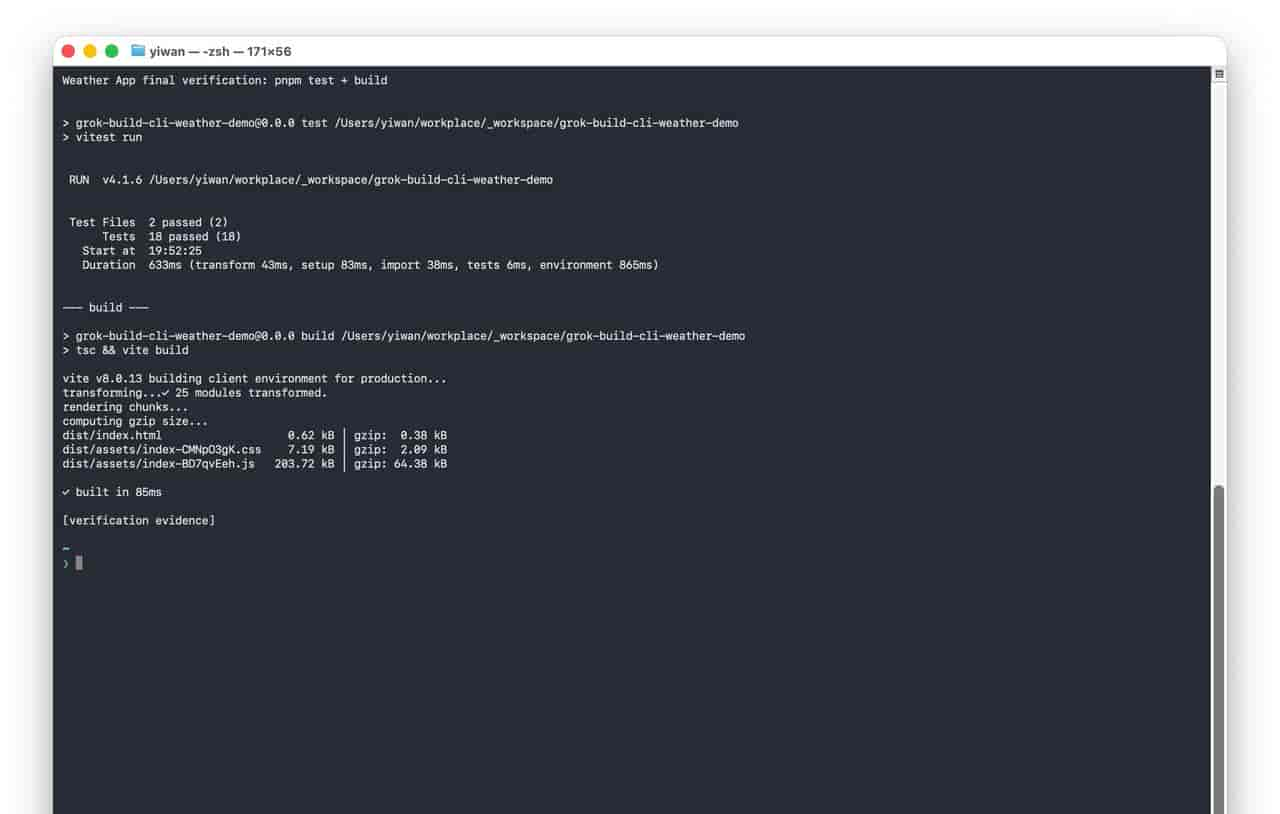
最后手动复核:测试和生产构建都跑通。
成品不炫技,但没糊弄
成品没有炫技。生产依赖只有 React 和 React DOM,天气图标用 emoji 映射,API 用 Open-Meteo,不需要 key。它也没有上 Redux,没有加图标库,没有把一个小天气应用写成依赖展览。这个取舍我反而喜爱。一个实用小工具先把事情做完,等复杂度真的上来,再决定要不要加状态库和 UI 组件库,这比一上来堆满配置更像正常工程。
最后的界面也没有糊弄。默认加载 San Francisco,搜索 Tokyo 有下拉结果,选中后更新主卡片和 5 日预报;最近城市会保存在 localStorage;摄氏华氏切换马上生效;移动端不会挤成一团。严格说它还够不上生产级天气应用,Grok 后面的验收也指出了这一点,可作为一个终端代理从空项目做出的第一版,已经超过了“能跑一下”的标准。
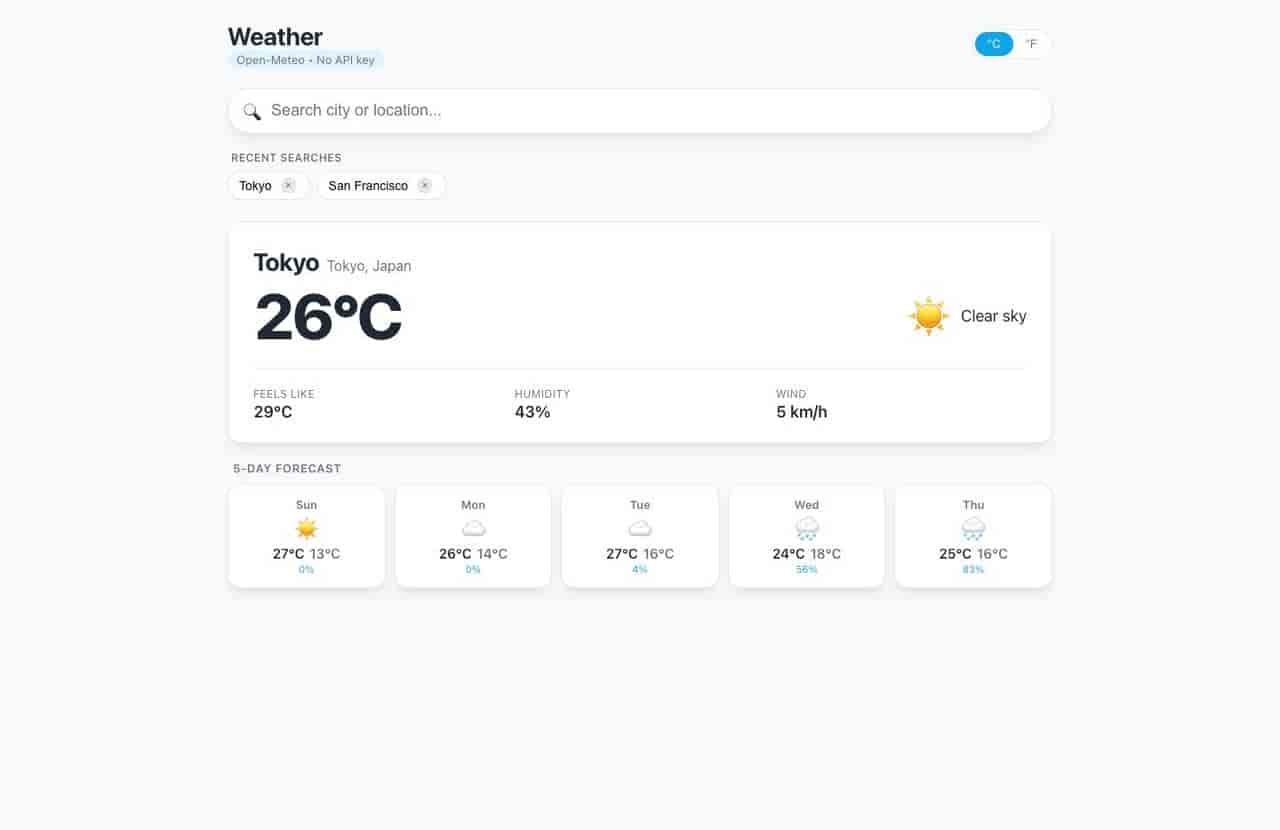
成品不炫技,但关键状态和移动端体验都没有糊弄。
最值得看的命令:inspect
Grok Build CLI 的命令面不小。我这次实际碰到或核过的主要有这些。
grok
grok login
grok version
grok models
grok inspect
grok update --check --json
grok sessions list
grok worktree list
grok mcp list
grok -p "..."
grok --prompt-file task.md
grok --permission-mode plan
grok --best-of-n 8
grok --check
grok trace
grok agent stdio
grok agent serve其中我最喜爱 grok inspect。它会把项目里的 AGENTS、skills、plugins、MCP、hooks、配置来源都扫出来,还会把解析失败和规则不认识的地方打成 warning。许多编码代理说自己“懂项目”,实际只是看了 README 和 package.json。inspect 至少让人知道它看见了什么,漏了什么。
inspect 的价值在于让“它看见了什么”变得可检查。
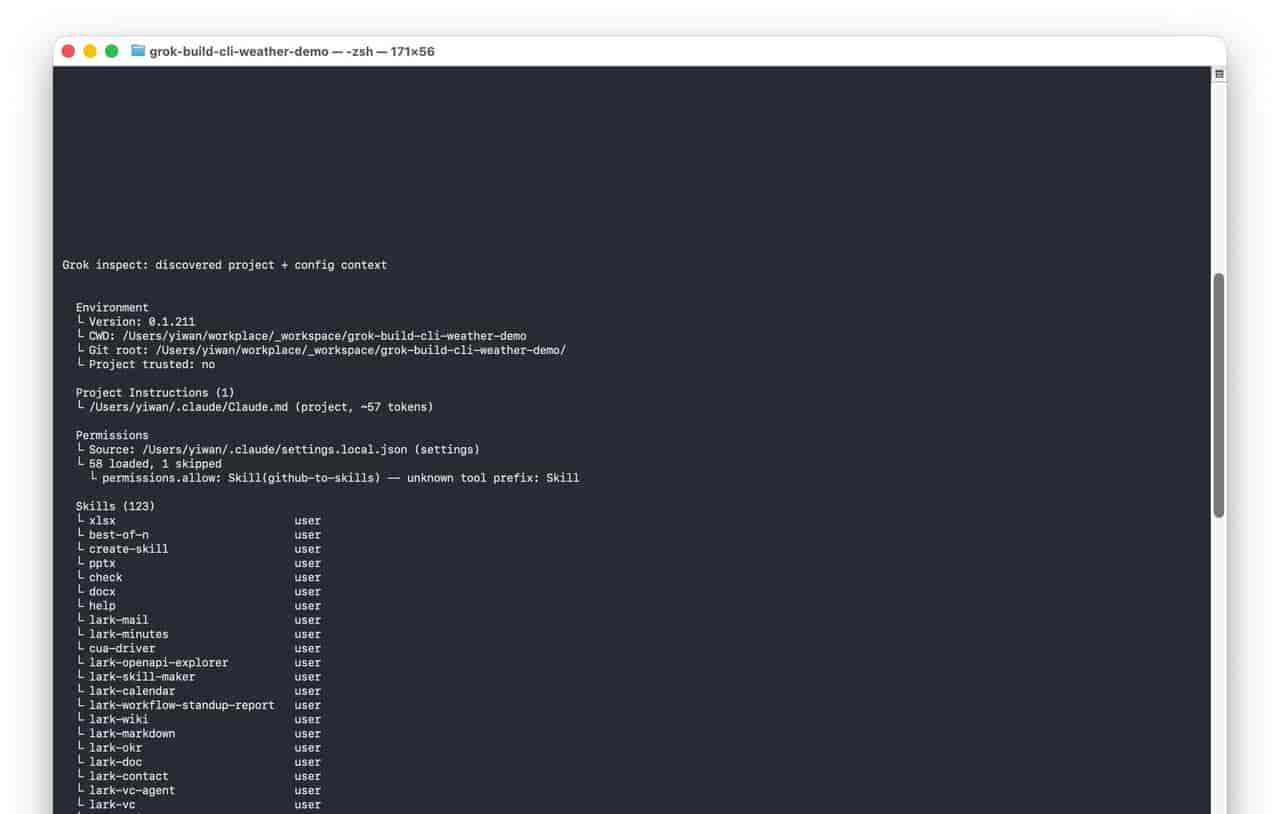
真实 inspect 截图:项目规则、技能、插件、MCP、hooks 都有迹可循。
8 个任务,别讲歪
最容易被误解的是 8 个 agent。官方视频里最吸引人的画面,的确 是多个 subagents 一起跑。xAI 的发布页也写了 subagents 可以并行 research、build、review,还支持 worktree。这个能力很有想象力,不过实测时要分清几件事。
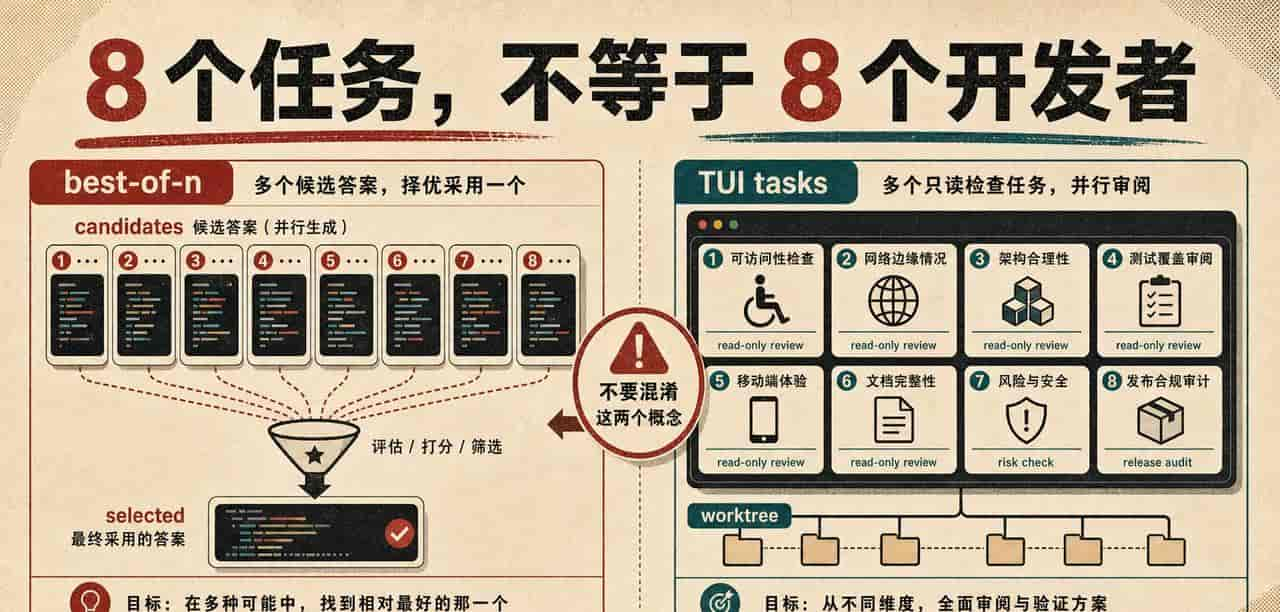
这段最容易讲歪:best-of-n 和只读验收任务不是一回事。
–best-of-n 8 不是 8 个 agent 一起开发。它更像 8 路候选答案。拿它当“8 个工程师同时干活”的证据,会讲歪。TUI 里的任务面板和 worktree 才是更接近官方演示的入口。我翻了本机文档,也看了几个视频的自动字幕,最后确认这一点不能混着说。
我最后做了一次更自然的软件验收测试,没有再给它预设展示目标。prompt 只要求它检查 Weather App 是否达到面向真实用户发布的软件质量标准,并把任务分成 8 个只读检查项。Grok 跑完后,右上角显示 8 个检查任务完成,最后给出的结论也很克制。可以发布,但需要补修,尤其是 RecentCities 的可访问性、网络边界测试、App 架构聚焦化。
这段我剪了一个 32 秒高光版。前 10 秒来自 1:00 到 1:10,后 22 秒来自 2:23 到 2:45。
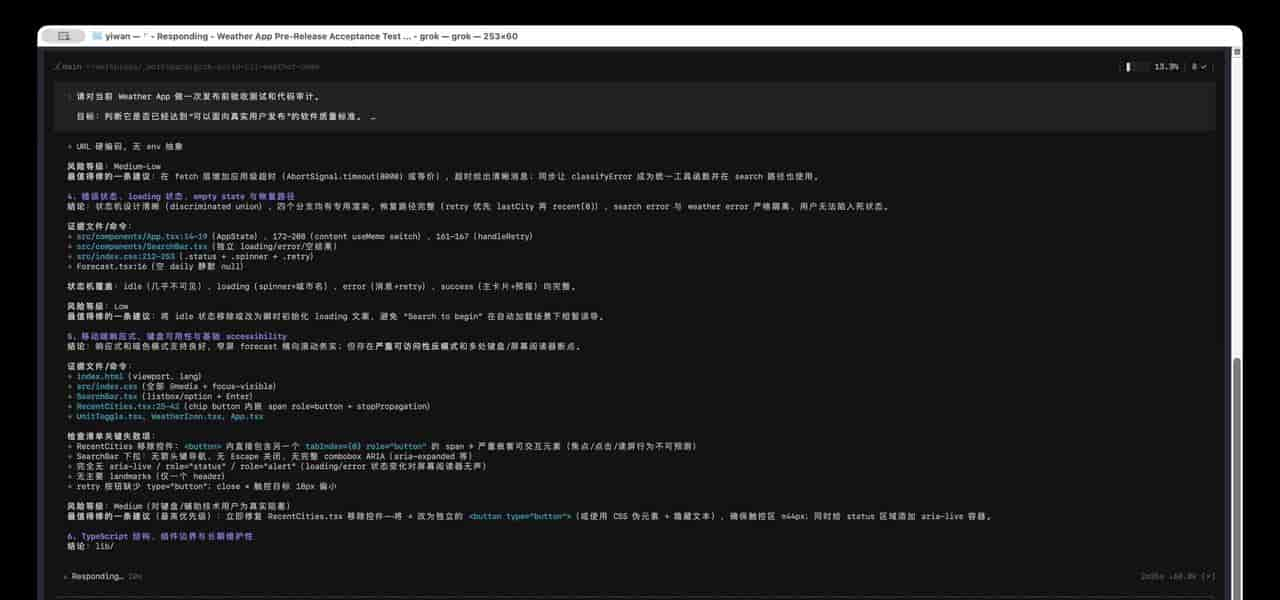
8 项只读验收能证明的是审阅和判断,不是 8 路同时写代码。
这条素材能证明的东西很有限,也正由于有限才可信。它证明 Grok 能在一个 TUI 任务里完成 8 项验收检查,并给出有用的发布判断。它不能证明 8 个 worktree agent 同时写功能,也不能证明它已经能干净合并 8 路改动。后者需要另做一个更重的测试。
不过我不觉得这个限制丢分。许多时候并行 agent 最适合做的事,本来就不是大家一起改同一个文件,最适合的是探索、评审、找风险、比较方案。Grok 在这件事上已经有了产品形态,至少不是 PPT 功能。
它和 Claude Code 的位置不一样
和 Claude Code 比,Grok Build CLI 目前还没有那种成熟工具的稳定感。Claude Code 的生态、习惯、社区资产都更扎实,出问题时也更容易在已有经验里找到解法。Grok 的优势在另一个方向。它的 TUI 更激进,Plan、inspect、subagents、worktree、headless、skills、plugins、MCP、ACP 这些东西,被放在同一个终端产品里,野心很明显。

Grok Build CLI 更像终端里的调度台,不是简单替代所有工具。
Cursor 适合留在 IDE 里改现有代码,Aider 适合小步提交和 Git 习惯强的人,Codex CLI 更像一个可以接本地和云端任务的工作代理。Grok Build CLI 这次给我的感受,是它更想做一个终端里的调度台。这个方向很诱人,也很容易翻车,由于调度台越复杂,越需要产品细节撑住。
目前看,它撑住了一部分。
问题和价格
问题也不少。第一次 verifier 没把 pnpm test 的 watch 模式当成必须修的错误;8 项验收任务完成了,但没有自动把任务过程整理成美丽的可引用报告;TUI 截图和录屏要自己抓,想拿到官方 demo 那种画面,还得反复试。它的输出也会偶尔带出“演示项目”这种说法,说明模型对项目定位依旧会摇摆,需要 prompt 写得更像真实工作。
价格是最后绕不过去的一刀。对只是偶尔写脚本、做小网页的人,SuperGrok Heavy 的门槛太高。用 Cursor、Claude Code、Codex CLI、Aider,甚至网页聊天加手动复制,都能把许多问题解决掉。Grok Build CLI 的价值,要靠高频、长时间、复杂项目来摊薄。
如果每天都在终端里写代码,项目里有 AGENTS.md,有 Claude Code 习惯,有 MCP,有自己积累的 skills 和 hooks,那它值得试。它最吸引我的地方,不在某一次回答比谁机智,它把读项目、计划、执行、自检、并行评审这些动作串了起来。只要这条链路足够稳定,省下来的就不只是几分钟等待,还有来回解释、重复粘贴、手动验收的疲劳。
临时评分:8.3/10
我的临时评分是 8.3/10。

我的临时评分:8.3/10。快、爽、贵,都是真的。
我不会说它已经干翻 Claude Code。这样说太早,也太便宜。Grok Build CLI 目前更像一个速度很快、方向很猛、还带着 beta 粗糙感的新工具。它让我第一次在 Grok 这条线上感到,xAI 不是只想做一个会聊天的模型,它开始碰开发者每天真正烦的那些事。
它还贵。可这次我用下来,至少清楚了一件事。
贵有时只是贵,有时是贵得让人骂两句,还想继续用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...