

生物性|视觉神经|人类共识|解释|入口
出品 | AI闹
01.
想象一个场景:你坐在曼谷一家餐厅,手机对准一张泰语菜单:2026年的AI不仅能把泰文翻译成中文——这已经像是上个时代的把戏了——它还能记住你是素食主义者,从二十道菜里挑出那三道不含肉的,用标准泰语帮你点单,顺便把附近评分最高的甜品店塞进你的下午行程。
这就像你雇了一个既懂你口味、又精通当地语言、还顺带是美食博主的私人助理。只不过,它在你的手机里,通过拍照即可得到。
这正是2026 年许多创业者押注的新方向:不仅让AI准确识别事物,还要让它理解「你为什么要看拍这个东西」,以及「接下来你想要干嘛」。
Chance AI就是切入这个方向。创始人曾熙有一个有趣的背景:他在巴塞罗那读认知科学与当代艺术博士,研究的问题是——为什么人类看到毕加索蓝色时期的画会感到忧郁?
这是一个文艺话题,但背后的原理实则超级硬核。
它触及了人类视觉系统的本质:我们的眼睛是摄像头,通过我们的大脑把视觉信号转化成情绪、记忆、意义。
目前,曾熙想让AI也学会这套本事:「为AI搭建一套视觉推理系统,把视觉信号转化成有价值和判断的解释。」
Chance AI的产品逻辑很简单:用户拍照,APP自动识别,然后给出解释,随着AI越来越了解你,解释会变得越来越个性化。
列如同样在画展拍毕加索:
- 一个孩子可能得到:毕加索是谁?回顾下昨天绘画课堂讲的知识点,你晚上可以试着画什么?
- 一个艺术爱好者可能得到:毕加索和蒙克的异同,城里还有哪个展览适合你?要不要目前帮你订票?
曾熙有一套公式来解释Chance AI的核心逻辑:识别视觉信号 + 个性化上下文 + 社会共识 = 价值意义
听起来有点抽象?我们简单拆解一下。
假设你随手拍了一张演唱会海报。对AI来说这不只是「一张印着字和图案的纸」,而是等待待解的工程:
这是什么演唱会?(识别视觉信号)
你是这个歌手的粉丝吗?(个性化上下文)
票好买吗?值得去吗?(社会共识)
然后,推导出行动:
什么时候开票?
要不要帮你加进日历?
开票当天是否设置提醒?
「我们想让AI长出一双有思考能力的眼睛。」曾熙说,「See the unseen——看到表面之下的东西。」
曾熙身上有种奇妙的混搭气质。他能用神经科学术语解释视觉皮层的工作原理,也能用黑色讲英国皇室和中国皇室的审美哲学,会用硬件行话聊供应链和PMF,同时喜爱橘子海,一支只唱英文歌的山东青岛籍乐队。
毕业后,他先后在一加、OPPO工作,最后一份工作是在字节跳动的Flow团队担任高级总监。
2024年,当GPT-4o多模态模型出世时,曾熙收到了一个明确的信号——这个技术方向正接近他博士期间研究的问题:人类的视觉系统如何生成意义?
这就是Chance AI诞生的故事。


02.
Chance AI目前已经积累了20万用户,其中40%在北美。产品的使用门槛很简单:拍照、识别、解释。
在技术底层,曾熙做了一个反共识的选择。「行业目前最大的误区,是尝试用一个模型解决复杂的视觉推理,这是不可能的。」
他在工程侧模仿了生物的视觉机制,把推理过程拆成了四步——就像人类大脑处理视觉信息时,会经过初级视觉皮层、形状识别、语义理解、决策规划等多个阶段。
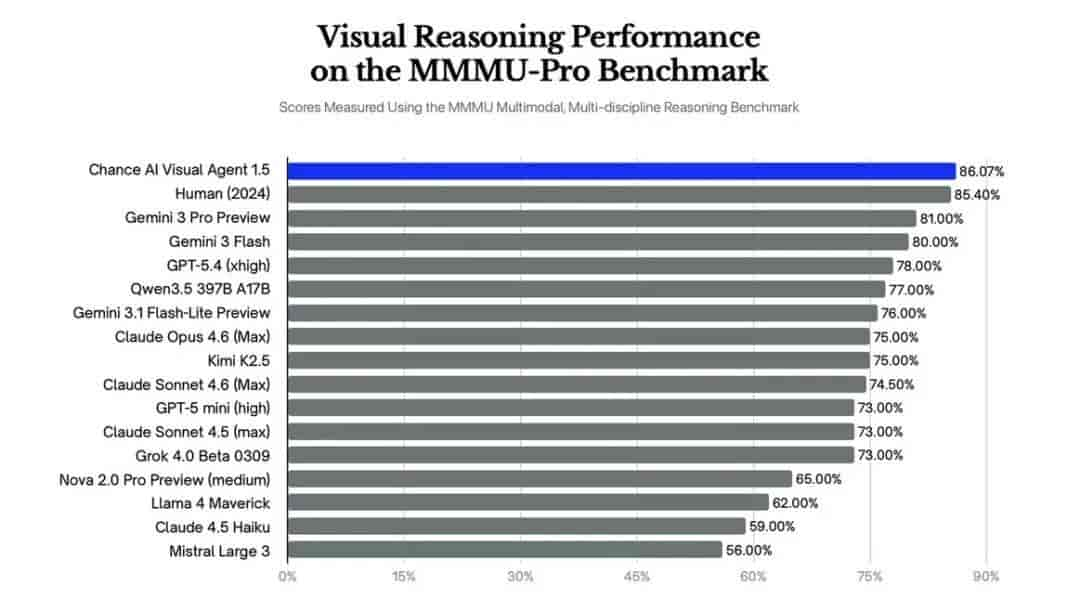
这套方法的效果如何?根据曾熙的说法,在目前最严苛的专业级多模态推理基准MMMU-Pro上,Chance AI跑出了86.07%的分数——这是目前已知的最高分。作为对比:
- Gemini 3 Pro:81.00%
- GPT-5.4:78.00%
- Claude Opus 4.6:75.00%
为了打消外界对「内部测试」的疑虑,团队最近把底层API开源,封装成可供其他Agent调用的CLI工具,希望学术界和开发者亲自跑分验证。
Chance AI还在超级早期的阶段,曾熙承认VLM(视觉语言模型)应用类产品大规模爆发还需要等待(或证明)三件事:
第一,「看」不是低频行为。 视觉会成为下一代交互入口——就像十年前触摸屏会取代键盘一样。
第二,把「看」真正转化为「行动」。 识别是第一步,理解是第二步,最终价值在于——AI能不能帮你完成事情。
第三。在巨头的系统能力之外,自己的不可替代。
「 对话曾熙 」
AI闹 第一个问题先问一个AI视觉的科普问题:AI已经能帮我们写论文、做奥数、但依旧很难判断「一杯冒热气的水不能碰」。为什么连婴儿都能理解的事,对 AI 反而是高难度?
曾熙 要先引入一个概念:人类看到的任何一个东西,都不只有表面那一层。
列如为什么一辆布加迪威龙的售价会比同等重量的黄金还要贵?或者一件潮牌 T 恤,可能上面只是多印了一个 logo,就比一件普通 T 贵许多?
所以让 AI 做到真正理解,要拆成三层:
第一层是感知,就是视觉识别。
第二层是上下文,从哪来?经历过什么?为什么重大?
第三层是社会共识。列如开布加迪威龙就释放出一种财富信号。
感知+上下文+共识才决定一个事物的价值。
但今天行业大部分产品,只停留在第一层,由于普遍做法是用一个模型来解决复杂的视觉推理,这是完全不可能的。
我们要做的让 AI 进入第二层第三层,列如理解为什么在人类社会同等重量的布加迪威龙售价会比黄金还要贵。
AI闹 你之前提过一个很有意思的判断,视觉理解的突破不能只靠更大模型、更强算力,而是要参考人类的生物机制?
曾熙 我认为 AI 在下一阶段技术突破的趋势通过参考其他学科的解决办法,把它们翻译转换过来,这是最难也是最具挑战的部分。
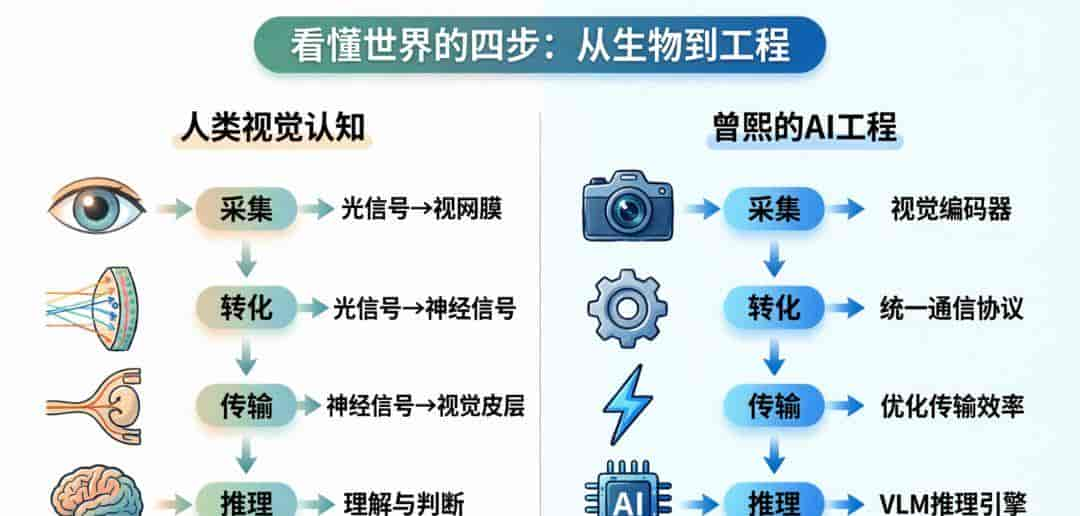
列如 AI 的视觉理解就要参考生物的视觉系统。生物从「看到」到「理解」是分四步的。
第一步是采集——把我们在真实世界里看到的视觉信号映射到视网膜上;
第二步是转化——把视觉信号转化成神经信号;
第三步是传输——把神经信号传到负责思考的大脑里;
第四步才是真正的视觉推理。
我们目前的做法是把四步拆成工程再用不同的技术实现,参考 Unix,把复杂问题拆成许多小模块,每个模块只做好一件事。
- 采集:获取视觉信号
- 转化:把视觉信号转化成模型能理解的格式
- 传输:建立统一的通信协议
- 推理:基于转化后的信号进行深度理解
以上四步还得串联通信协议,有点像目前流行的 MCP 或者 Skills,相当于我们也要做一部分视觉领域的基础建设。
AI闹 之前豆包的拍照功能就是你主导的,大厂没有这么干吗?
曾熙 大厂倾向选择一个模型解决一切,不是由于它们没有能力,而是由于他们有更大的模型,更多的数据,更强的算力,以及想做更统一的入口。但视觉理解并不是一张更大的参数表就能解决的问题。它更像一条神经链路。列如人的眼睛不负责思考,眼睛只是采集信号。真正理解发生在信号转化、传输和大脑推理之后。
大厂想做的是更强的眼睛,我们想做的是眼睛后面的神经系统。
AI闹 目前产品刚上线一年就累积20万用户,怎么做到的?
曾熙 种子用户是 2024 年我和朋友探索了一个小项目,给在深圳举办的安迪沃霍尔展览做 AI 导览。展览结束之后,大致还有大几千个用户日常也会用它拍东西,列如名胜古迹、花草,商品、食物。
之后产品正式上线,第一批针对北美和印度的一些高校做的的社群项目。刻意寻找了一批设计系、艺术系的学生,他们本身就是极度视觉导向的年轻人群体。在校园里形成了超级强的口碑自传播。此外我们还在Product Hunt 上连续两次拿下了当日最佳产品。
这20 万用户几乎没有花钱去买量。

AI闹 用户具体用它做什么?
曾熙 很反常识,我们几乎没有 30 到 45 岁的用户。
主力用户第一类是年轻人,大致 15 到 25 岁,第二类是 45 到 55 岁,甚至更年长一点、接近退休的人。他们有时间也有好奇心。反而是 30 到 45 岁的人群很难使用一个「跟生产效率无关」的产品。
主要场景有三个:
第一个是旅游,尤其是出国。
第二个生活场景,让 AI 看一下穿搭,面试穿什么,见男朋友穿什么;和闺蜜喝下午茶看食物的热量、去书店拍书了解核心思想。
第三个是兴趣爱好。有个用户一天拍了 300 多张石头照片,后来才知道他是个矿物爱好者,收藏了许多石头,兴趣场景粘性最高。
AI闹 「穿搭」这个场景有意思,其他场景是给信息,给知识,相对客观,穿搭要提供品味提议,相对主观,AI怎么做到?
曾熙 某种程度上成立。但我观察到的更复杂一些。
这是个好问题。我是这么理解的,好品味是由一系列高质量决策组成。
我们无法告知用户「好看」或者「不好看」,我们是在做决策之前给他提供更多高质量的选项。
列如用户问一件碎花裙,我们马上找来跟碎花裙相关的比较 trending 的图片、社媒讨论热点、公开网络形成的高质量观点。最终穿什么,还是由用户来做。
相当于压缩了形成品味的效率,时间累积,用户自然能形成了自己的品味。
AI闹 我有个疑惑:我们真的需要一个 AI 随时解释眼前的生活吗?怎么避免「过度解说」?
曾熙 举个例子,我很喜爱看球赛,chance AI 有点像我们看球赛时的解说,不同的解说会带给人完全不同的感受。
列如你在逛街,它可能会跟你说:这条蓝色裙子不太适合你,由于家里已经有一条类似的了。为什么不思考一下那条淡绿色的?最近很流行,显得你皮肤白。而且这条绿裙子,恰好跟你昨天逛过的那家店里的某双鞋子还挺搭的,相当于你拥有了一个实时陪你看世界的「闺蜜」。
它可以帮你解读眼前的生活,给你提供更多选项。让你正在经历的真实世界变得更有意义。
AI闹 这两年在 VLM 上做应用层的公司不多,第一是由于LLM 机会超级多,第二个VLM应用确定性不高,为什么创业要切入这个方向?
曾熙 视觉应用是下一个时代最大的入口,没有之一,我无比确定。
第一, Google Lens 在 2025 年加了 AI mode 之后,带来了 70% 的用户增长,且全是新用户,这是客观数据;
第二, Z 世代甚至是阿尔法世代的成长经历就是在 Instagram、TikTok、抖音、小红书这类产品浸染下长大的,他们可以说是「视觉原生一代」,对他们来讲,文字反而是补充;
第三,未来,每个人都需要一个终端来连接自己与虚拟世界。今天的终端是笔记本电脑、手机,或者如智能手表、智能耳机。那未来设备会演化成什么样?目前还不确定。但我笃定的是,它必定是一个能跟你的感官同频的产品——听到你听的,看到你正在看的,同时有自己的运算和通讯能力来补充你的信息。
我们想做的是在下一代 AI 终端没有完全确定之前,先把「视觉大脑」打磨好,等下一代视觉终端来了,直接无缝接进去。
AI闹 你正好回答了我的另外一个疑问,你有过硬件背景,但创业没有从硬件切入?
曾熙 我超级知道其中门道。 iPhone 卖得好并不是由于硬件本身,而是由于它丰富的生态。硬件是最终的结果,只不过大部分人都误会了。
AI闹 不做垂直场景,也不做硬件,对商业化是怎么思考的?
曾熙 现阶段我们对商业化的判断是先把「入口」做成,再把商业化做深。
Chance AI 不是一个一次性工具,我们更想先让用户形成一种新的习惯——看到一个东西,会下意识地先用 AI 去理解它。如果这件事成立,商业模式实则会比较自然地长出来。
最明确的路径有三条。第一条是 Premium 订阅,面向高频用户提供更强的能力,列如更深入的 Live 模式、更长链路的视觉记忆、更个性化的理解与判断、以及不同场景下的专业 Visual Agents。第二条是 B2B / 授权合作,艺术展览、博物馆、教育等场景,甚至 AI 硬件厂商,本质上都需要一层「视觉理解系统」,;第三条才是场景内的推荐与交易,但会超级克制地做。不会把用户的好奇心导向广告或购物链接,而是在用户已经完成理解之后,再协助他做下一步行动,列如订票、预约、到店体验、点菜、购买等。
但一切前提是视觉入口成立,订阅、授权和交易都会有空间;如果没有成立,任何商业化都只是短期变现。
AI闹 许多大厂也在探索视觉OS的方向,他们有硬件、有模型、有分发。Chance AI 的壁垒是?
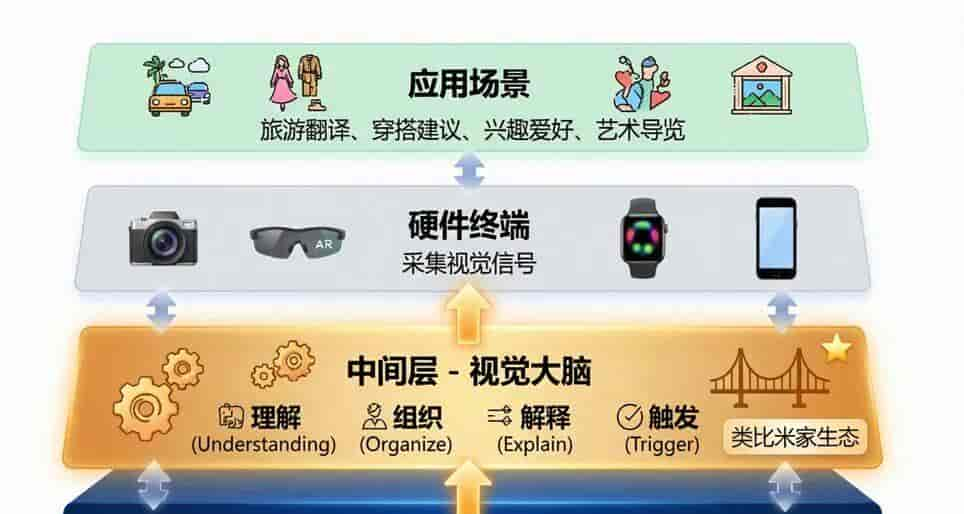
曾熙 大厂提供 VLM 能力,硬件负责采集世界,具体应用负责服务某个场景,Chance AI 的价值是如何理解、组织、解释,并触发下一步行动。
我想做是中间层,是「神经系统」。可能更像米家生态——无论用户买什么样的小米电器,最终都要返回到米家生态。
AI闹 跟你做同一方向的创业公司还有哪些?
曾熙 暂时没有看到,我们是全球唯一一家,这也是让我有点恐慌的点,但也并不是做早了,列如提前了十年。也许 DeepMind 也在做,只是外界不知道(笑)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











