谷歌在2026年4月2日推出开源模型Gemma 4,以31B参数实现头部性能,出现了前所未有的体量与能力反差。
首个明显的反差在于体量与表现:Gemma 4的31B稠密模型并非凭“加大”取胜,而是在同规模下跃至全球第三。它的性能甚至超过自身体量20倍的模型,这种掉头式超越让惯性认知发生断裂——参数不再是智能上限的指针。对研究者而言,这代表一种节能却不减能的计算格局,对开发者而言,则是更轻、更实用的智能载体。
继续向下拆,看似微缩的体量背后,是算法路径与生态接口的细微反转。过去,开源模型往往在可控性上牺牲性能;而Gemma 4采用Apache 2.0开源许可,却保留了商业级能力,原生支持函数调用与结构化JSON输出。这种放开的姿态,与过去“封闭高端、开放简化”相反,构成了制度层面的反差,也让其在智能体工作流中成为具备独立执行力的节点。
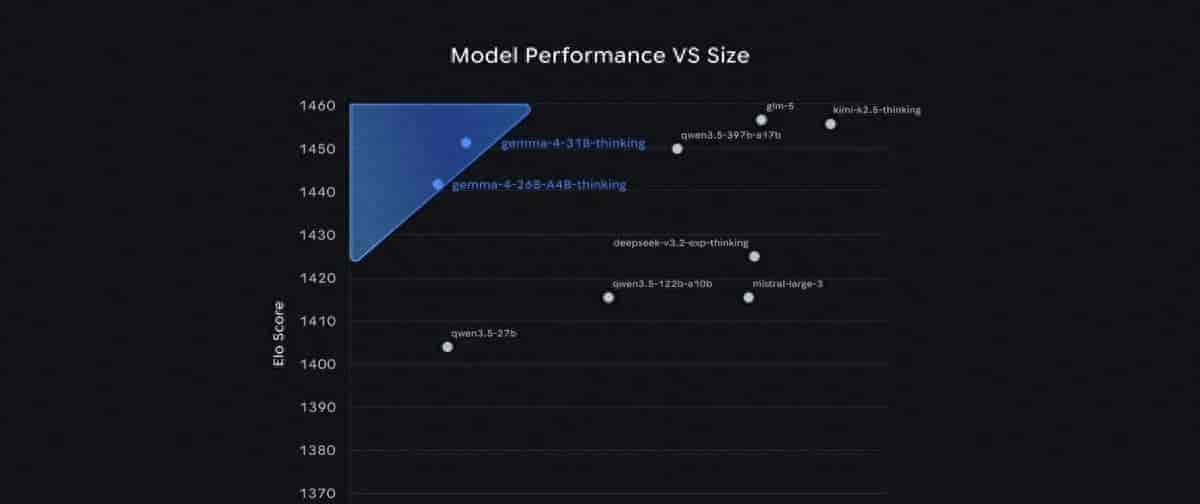
技术细节进一步暴露出资源分配逻辑的变化:26B混合专家版推理时仅激活38亿参数,却击败了总量数百亿级竞品。激活程度由静态全功率向动态稀疏切换,能量利用不再成倍扩张,而是转为灵活分配。用户因此感知到可在单张80GB H100上驱动顶级模型,消费级GPU亦可运行量化版本——硬件门槛骤降形成新的可及性反差。
再看端侧模式,E2B与E4B模型让“设备边缘”由弱势变强境:从依附云端到完全离线运行,能在手机、树莓派和Jetson Orin Nano上实现近零延迟。算力节奏从聚焦化转向分布化,那种原本被视为补位的轻型AI,如今具备独立运算能力。这种反差不仅是性能维度,更是应用心智的重塑——人们开始信任端侧也可以思考。
不同层面间反差不断叠合:从参数效率到跨设备兼容,从算法稀疏激活到多模态全栈统一,每一次变化都将“大即强”的旧范式削薄。Gemma 4用一系列局部逆转构造出代际断层,使上一代27B版本的成绩突然显得笨重,而“单位参数智能水平”成为新衡量标准。这种被谷歌定义为“最智能”的开源模型,不以量取胜,却重新定义了智能的重量与尺度。
这一核心变化揭示了AI计算范式正在由体量竞争转向效率竞争。当性能开始脱离规模,它同时改变了研发逻辑、生态结构与用户预期。Gemma 4不仅是新模型,更是计算价值体系自我对位的标志事件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











