
当AI开始“同时理解世界”,真正的难题才刚刚开始。如果说前几讲,我们还停留在“一个模型处理一种数据”的世界,那么从这一讲开始,问题彻底变了。
现实世界,从来不是单模态的。你看一段视频,不只是“图像”,还包含声音、语言、情绪、时间节奏;你理解一个人,不只是“他说了什么”,还有语气、表情、语境。
而多模态AI,本质上就是在做一件事:让机器像人一样,把这些不同来源的信息“拼在一起理解”。
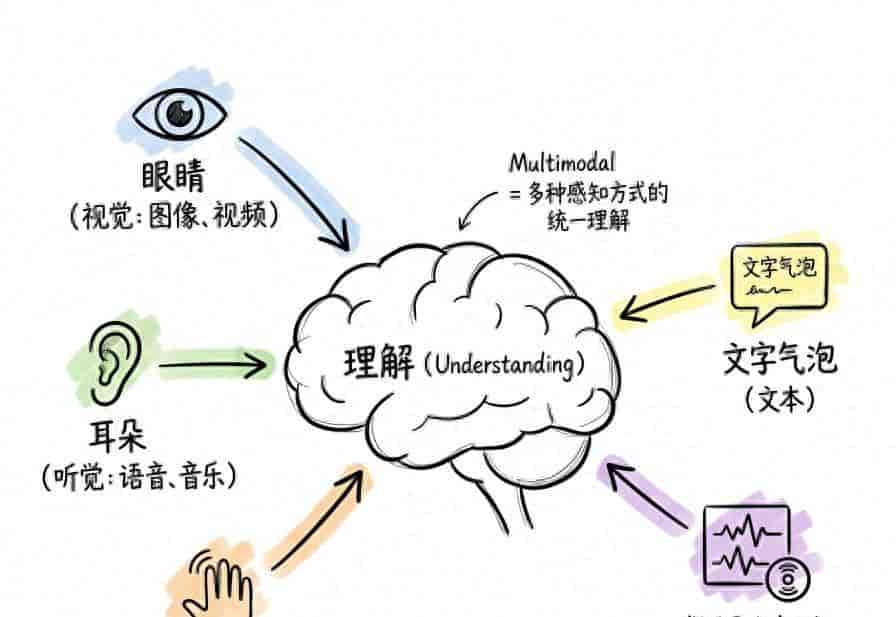
这听起来很自然,但技术上极其困难。
这一讲,讲的就是这件事背后的核心问题: 多模态(Multimodal)与对齐(Alignment)
一、多模态AI,是怎么一步步走到今天的?
在讲技术之前,我们先看一条超级关键的时间线。
多模态的发展,并不是一蹴而就的,而是经历了五个阶段:
1)行为时代(1970s–1980s)
研究停留在观察层面,人类是如何同时理解语音和表情?如何通过唇读理解语言?
这个阶段是有认知,没有模型。
2)计算时代(1980s末–2000)
开始出现早期系统,列如语音识别。但核心方法还是:规则 + 统计;模态之间几乎没有“深层理解”
3)交互时代(2000–2010)
重点变成人机交互:
- 多模态对话
- 手势识别
- 情感计算
机器开始“参与沟通”,但还不够机智
4)深度学习时代(2010s)
真正爆发:
- CNN 处理视觉
- RNN 处理序列
- 经典任务出现:图像描述、VQA、唇读
这个阶段模态开始“能被学出来”了。
5)基础模型时代(2020s)
关键转折点来了:
- CLIP
- DALL·E
- GPT-4V
这些模型的本质是:它们天生就是多模态的
不再是“多个模型拼起来”,而是一个模型理解整个世界。
如果你把这五个阶段串起来,实则是一个很清晰的演化路径:
行为观察 → 计算建模 → 交互系统 → 深度学习 → 大规模预训练
每一次跃迁,本质上都在回答一个问题:不同模态之间,如何建立关系?
二、什么是“模态”?真正的定义是什么?
课程里给了一个超级精炼的定义:Modality = 信息被表达或被感知的方式
给公式:模态 = 你“怎么知道这件事”的
在人类世界里:
- 视觉:你“看到”
- 听觉:你“听到”
- 触觉:你“摸到”
在AI世界里:
- 图像 = 一个模态
- 文本 = 一个模态
- 语音 = 一个模态
- 视频 = 一个模态
甚至:图结构、传感器数据,都可以是模态
三、多模态,不是“多个数据”,而是三件事
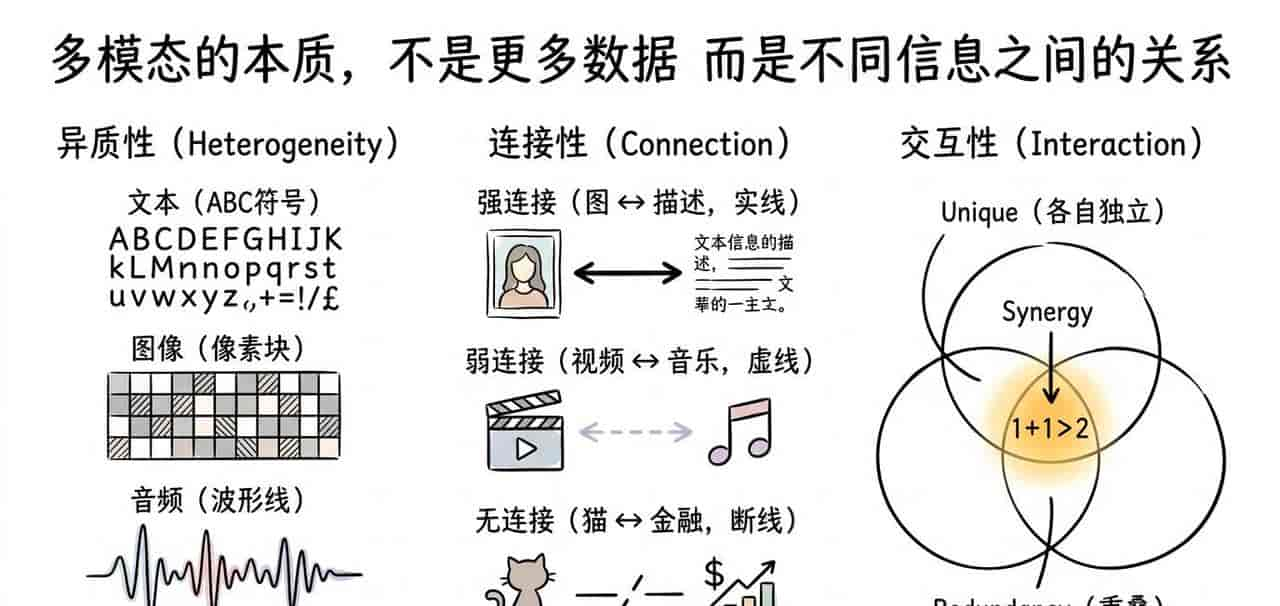
课程里有一句超级关键的话:
Multimodal is the science of heterogeneous and interconnected data
直接翻译是:多模态是研究异构和相互关联数据的科学。但这种直译过来实则不够——真正要理解,需要拆成三个关键词:
1)异质性(Heterogeneity)
不同模态,本质完全不同。
- 文本:离散符号(词)
- 图像:连续空间(像素)
- 音频:连续时间(波形)
他们的底层结构不一样,但有个很有意思的现象,那就是越抽象的东西,不同模态反而越“像”。
列如“开心”:
- 文本:我很开心
- 表情:微笑
- 语音:轻快语调
表达不同,但语义一致
2)连接性(Connection)
模态之间不是随意拼的,它们有关系强弱:
- 强连接:图像 ↔ 描述
- 弱连接:视频 ↔ 背景音乐
- 无连接:猫图 ↔ 金融新闻
连接强弱,决定是否能相互协助
3)交互性(Interaction)
就是模态组合之后,会产生什么?
三种情况:
• Unique(独有信息)
某个模态独有:
- 文本:语义
- 语音:语气
• Redundancy(冗余)
多个模态表达同一件事:列如说“我很开心” + 微笑
• Synergy(协同)
最重大: 1 + 1 > 2
列如:
- 文本:I'm not sure
- 表情:困惑
结合起来才能真正判断“犹豫”,因而多模态的价值,不在叠加,而在协同
四、多模态的6个核心问题,实则就是你每天在做的6件事
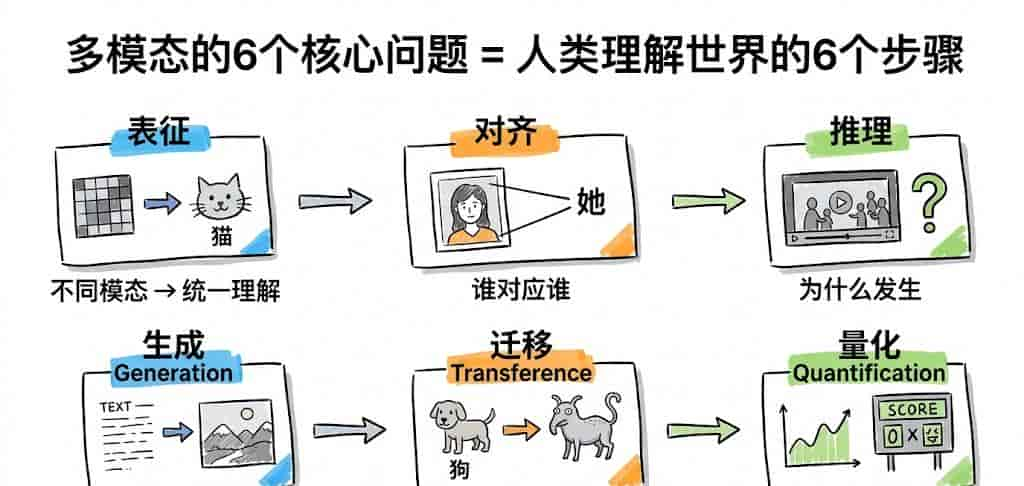
你以为多模态很复杂,但实则——你每天都在做,只不过你做得太自然了。
我们一个一个来。
1. 表征(Representation)
这就是你在做把世界“看懂成一种形式”。
例如你看到一只猫。不是像素、不是颜色、不是边缘。而是你脑子里只剩一个东西 “猫”。
但对机器来说,不一样。
- 图像:是一堆像素
- 语音:是一段波形
- 文本:是一串符号
由于我们和机器根本不是一个“语言体系”
所以第一步必定是:把不同模态,翻译成一种“机器能统一理解的表明”
举个更直白的例子:
你刷短视频:
- 画面:一个人在跑
- 音乐:很燃
- 文案:冲!
你脑子里形成的是:“热血/激励”。这个过程,就是表征
本质一句话:表征 = 把不同模态,压缩成“同一种理解空间”
2. 对齐(Alignment)
就是知道“谁对应谁”。
列如你看一张图:
一个女生在喝咖啡。同时字幕写着 “她终于放松下来了”
你不会困惑“她”是谁?“放松”发生在哪?
你自动知道:“她”=图里的那个人,“放松”=她目前的状态。
但这些机器不知道。
因而它需要解决的问题是:文本里的词,对应图像里的哪个区域?
再换个生活例子:
你看电影:
- 角色说:“我来了”
- 镜头切到门口的人
你会自动对齐:说话的人 = 这个人
所以: 对齐 = 在不同模态之间,建立“对应关系”
3. 推理(Reasoning)
你看到一个视频:一个男生打开窗户,外面正下雨
问题来了: 他为什么开窗?
人类不会只看一个模态:由于只看画面不知道缘由,只有问题不知道场景。
所以机智的你会结合:场景 + 语义 +常识
得出结论:可能是需要通风、或者刚回家。这就是推理。
小结一下:
- 对齐:谁对应谁
- 推理:为什么发生
推理 = 用多个模态,推导出“隐含信息”
4. 生成(Generation)
就是把理解“说出来或者画出来”。
你看到一张照片:夕阳、海边、一个人。
你可以说:“一个人在海边看日落,很孤独”
或者你听到一句话:“一只宇航员猫在月球喝咖啡”,你脑子里会立刻出现画面。
这就是生成:
- 图 → 文(描述)
- 文 → 图(想象)
这个难点在不是生成本身,而是跨模态语义必须一致
本质一句话:生成 = 用一个模态,创造另一个模态
5. 迁移(Transference)
迁移就是用“熟悉的理解”,帮你理解陌生的东西
你没见过某种老虎。但你见过猫,想到老虎,你想到一个巨星猫。这就是用已有知识迁移。
在AI里:图像数据许多,语音数据少,就可以用视觉能力,去协助语音任务。
在举一个例子,我们多数人学英语的时候,都是用先中文理解的。
迁移的本质:用一个模态的知识,协助另一个模态
6. 量化(Quantification)
判断“它到底理解了吗?”。这是最容易被忽略,但很最重大的一点。
列如一个AI:
- 能生成图片
- 能回答问题
问题是:它是真的理解,还是在“瞎猜”?
你怎么判断?
- 准确率?
- 一致性?
- 人类评分?
衍生更深一层问题:如果文本说开心,表情是悲伤,这更可信吗?
这就是量化要解决的:如何衡量多模态之间的关系和质量
总结一下: 量化 = 判断多模态系统“到底有没有理解”
最后,把这6件事串起来
你会发现一件很有意思的事,这6个问题,实则就是一条完整链路:
表征 → 你先把世界“看懂”
对齐 → 再知道“谁对应谁”
推理 → 然后理解“为什么”
生成 → 再表达出来
迁移 → 用已有能力扩展
量化 → 最后判断好不好
所以真正的总结不是6个词,而是一句话:多模态AI,本质是在复刻人类理解世界的全过程。
如果你把这套理解建立起来,你再看CLIP、GPT-4V、视频模型。就不会觉得它们是“不同模型”,它们只是在这6个环节中,分别变强了。
最后的总结
如果你只记住一句话,我希望是这一句:
多模态AI,不是处理更多数据,而是理解“不同数据之间的关系”。
而这件事的核心,不是模型,是对齐(Alignment)。
再进一步说: 未来AI的能力边界,不取决于模型有多大,而取决于它能否把世界“对齐”。
如果你理解了这一点,你会发现:那些AI公司不是做“模型”,而是让让机器建立“世界的统一表明”。 也就是李飞飞说的世界模拟。
[!Tip]
专注于 AI 智能体实践与技术演进深度思考。主理人拥有资深技术背景与心理学视角,致力于通过真实实验(2025年更新361篇实操记录)探索 LLM、RAG 与 Agentic Workflow 的落地边界。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











