
一、24GB Mac Mini实测翻车?谷歌新模型竟被阿里开源模型碾压
本地AI玩家最近都在疯抢谷歌刚发布的Gemma4-12B模型,毕竟作为谷歌DeepMind推出的全新开源模型,它一上线就号称“端侧性能天花板”,支持全离线运行,还能完美适配本地部署场景。许多人默认“参数越大越能打”,觉得12B参数的Gemma4,必然能轻松碾压8B参数的阿里Qwen3-8B。
但一位技术博主的实测,却打破了所有人的固有认知。他在24GB Mac Mini上,对两款模型进行了实打实的头对头测试,没有华丽的参数堆砌,没有夸大的性能宣传,只靠真实的运行数据说话。测试结果一出,评论区瞬间炸了——号称更强的Gemma4-12B,竟然在核心速度上被Qwen3-8B按在地上摩擦?
更让人好奇的是,这场实测不仅揭开了“参数决定一切”的谎言,更给所有本地AI玩家提了个醒:我们追求的到底是参数噱头,还是能真正解决问题的实用性能?两款热门开源模型,到底谁更适合普通用户的本地部署需求?
关键技术补充:两款模型核心信息速览
在看实测细节前,先给大家理清两款模型的核心背景,避免被参数迷惑。两者均为开源免费模型,支持本地部署和二次开发,适配绝大多数消费级设备,是目前本地AI玩家的首选。
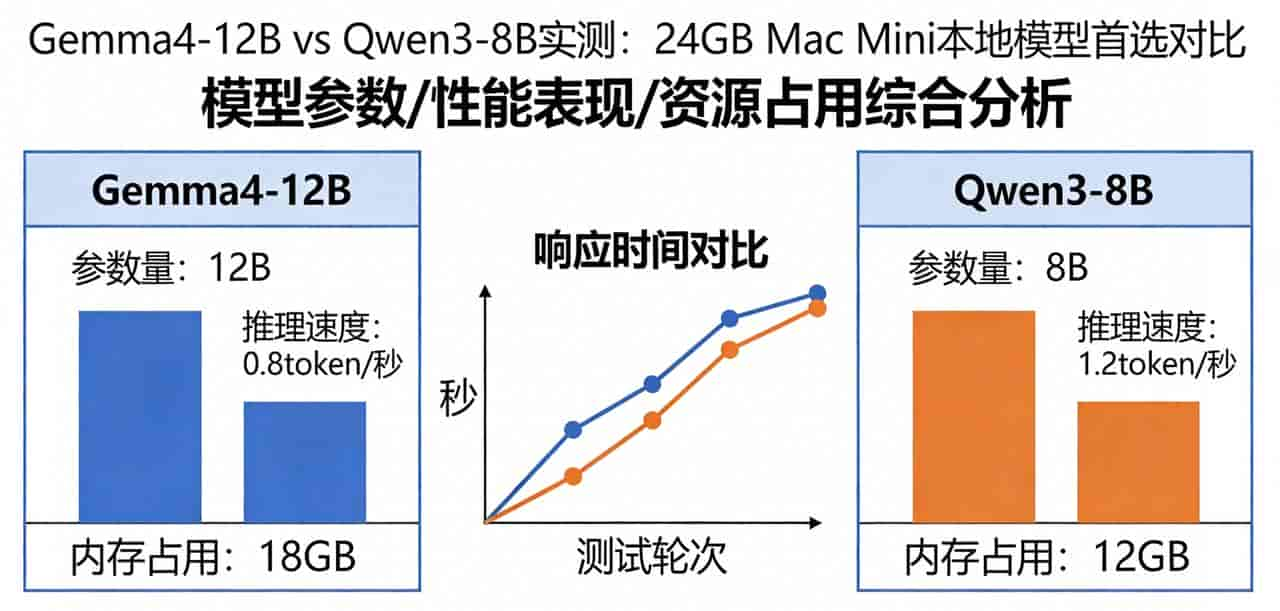
Gemma4-12B:谷歌DeepMind于2026年4月2日发布的Gemma4系列成员,基于Gemini 3同源技术打造,采用Apache 2.0协议,彻底摆脱了前三代的自定义许可证限制,可免费商用、修改和二次开发。该模型主打多模态能力和离线运行,支持复杂推理、编程助手、Agent系统等场景,在Arena开源榜中表现亮眼,其12B参数版本适配中高端消费级设备,24GB内存设备可流畅运行。
Qwen3-8B:阿里通义开源的Qwen3系列模型之一,于2025年4月正式开源,同样采用Apache 2.0协议,可免费商用。该系列模型发布2小时,GitHub星数就突破16.9k,支持119种语言,引入混合思考模式,可根据需求切换“思考模式”和“非思考模式”,在编程、数学、逻辑推理等领域表现突出,8B参数版本显存占用低,适配中小内存设备,是本地部署的“轻量王者”。
二、核心拆解:实测全过程曝光,每一步都可复刻
这位技术博主的实测没有任何玄学,全程公开可复刻,无论是测试设备、测试场景,还是测试方法,都清晰明了,普通用户跟着操作,也能完成自己的本地模型对比测试,真正做到“有理有据”。
测试基础信息
测试设备:24GB Mac Mini(普通消费级设备,无需专业显卡,贴合大多数用户的实际使用场景);
测试模型:Gemma4-12B(未量化版本)、Qwen3-8B(q4_K_M量化版本);
测试工具:借助Claude生成的grep命令,精准抓取模型的响应数据,确保测试结果的准确性;
测试场景:两个核心实用场景,覆盖日常学习和编程需求,避免无用测试,贴合用户真实使用痛点。
测试场景及步骤
场景一:化油器工作原理讲解(通用知识问答,测试模型的prompt解析速度和内容生成流畅度);
场景二:编写Python函数检测内存泄漏(编程任务,测试模型的代码生成能力和响应效率,贴合开发者需求)。
测试步骤:
1. 在24GB Mac Mini上完成两款模型的部署,确保模型运行稳定,无卡顿、无崩溃;
2. 输入第一个测试prompt:“explain how a carburetor works”(中文释义:讲解化油器的工作原理),通过grep命令抓取prompt评估速度(prompt eval,即模型解析输入指令的速度)和生成速度(Generation,即模型输出内容的速度);
3. 清空设备缓存,重复测试3次,取平均值,避免单次测试误差;
4. 输入第二个测试prompt:“write a Python function to detect memory leaks”(中文释义:编写一个检测内存泄漏的Python函数),重复步骤2和步骤3,记录相关数据;
5. 整理两款模型在两个场景下的测试数据,对比分析性能差异。
测试代码及数据(可直接复刻)
本次测试使用的grep命令(Claude协助编写,用于抓取响应数据):
# 用于抓取prompt评估速度和生成速度的命令
grep -E "prompt eval|generation" model_output.log | awk '{print $1, $2, $4}'场景一:化油器工作原理讲解测试数据
|
模型 |
Prompt eval(解析速度,t/s) |
Generation(生成速度,t/s) |
|
Qwen3-8B-q4_K_M |
89.8 |
19.6 |
|
Gemma4-12B |
20.8 |
27.6 |
场景二:Python内存泄漏检测函数编写测试数据
|
模型 |
Prompt eval(解析速度,t/s) |
Generation(生成速度,t/s) |
|
Qwen3-8B-q4_K_M |
133.8 |
18.7 |
|
Gemma4-12B |
26.1 |
26.1 |
补充说明:t/s(tokens per second)即每秒处理的token数量,数值越高,速度越快;Qwen3-8B采用q4_K_M量化版本,是目前最常用的量化方式,兼顾速度和性能,而Gemma4-12B未进行量化,更能体现其原生性能。
三、辩证分析:没有绝对的王者,只有适配的选择
从实测数据来看,两款模型各有优劣,没有绝对的“赢家”,也没有绝对的“输家”——它们的优势的背后,都藏着对应的短板,而这些短板,恰恰决定了它们适合不同的用户群体。
Qwen3-8B的优势十分突出,在prompt解析速度上,几乎是Gemma4-12B的4-5倍:化油器讲解场景中,Qwen3-8B解析速度89.8t/s,Gemma4-12B仅20.8t/s;编程场景中,Qwen3-8B解析速度高达133.8t/s,而Gemma4-12B仅26.1t/s。这对于需要处理大上下文prompt的场景(列如博主提到的OpenClaw相关使用)来说,简直是“降维打击”,毕竟大上下文解析速度慢,会直接影响使用体验,甚至导致任务卡顿。
但我们不能只看到Qwen3-8B的速度优势,也要看到它的短板:作为8B参数模型,它的生成速度略逊于Gemma4-12B,两个测试场景中,Gemma4-12B的生成速度均高于Qwen3-8B,尤其是化油器讲解场景,Gemma4-12B生成速度27.6t/s,比Qwen3-8B的19.6t/s快了近40%。而且,Gemma4-12B作为12B参数模型,理论上在输出内容的深度和准确性上,会略优于8B参数的Qwen3-8B,只是博主并未对输出质量进行测试,这也给我们留下了悬念。
更值得深思的是,参数大小真的能决定模型好坏吗?Gemma4-12B参数比Qwen3-8B多50%,但在核心的解析速度上却被碾压,这说明“参数越高越优秀”的说法,本身就是一个误区。对于本地部署用户来说,模型的适配性远比参数噱头更重大——24GB Mac Mini这样的普通设备,运行量化后的Qwen3-8B流畅无压力,而运行未量化的Gemma4-12B,虽然能运行,但解析速度慢,反而影响使用体验。
我们不妨思考一下:你在使用本地模型时,更看重什么?是“秒级响应”的解析速度,还是“稍快一点”的生成速度?是追求参数带来的理论优势,还是贴合设备的实用性能?
四、现实意义:本地模型选型,终于有了明确参考
这场实测的价值,不在于分出两款模型的胜负,而在于给所有本地AI玩家、开发者,提供了一份真实、可参考的选型指南——尤其是对于使用24GB内存设备(如Mac Mini、普通笔记本)的用户来说,终于不用再盲目跟风追参数,也不用在众多模型中反复试错。
对于大多数普通用户和开发者来说,Qwen3-8B无疑是更具性价比的选择。它的解析速度快,适配中小内存设备,量化后运行流畅,无论是日常的知识问答、文案生成,还是简单的编程辅助,都能轻松应对,尤其是需要处理大上下文prompt的场景(如OpenClaw相关操作),Qwen3-8B的速度优势会更加明显,能有效解决“解析卡顿”“等待时间长”的痛点。
而Gemma4-12B也并非毫无价值,它的生成速度更快,参数更高,理论上的输出质量更优,适合对生成内容深度有要求、且设备性能足够(如32GB及以上内存)的用户,列如需要生成复杂文案、深度编程代码、多模态内容的开发者。而且,Gemma4-12B支持多模态能力,能处理图像、音频输入,这是Qwen3-8B不具备的优势,对于有多模态需求的用户来说,它依然是值得尝试的选择。
除此之外,这场实测也印证了一个道理:开源模型的发展,正在从“参数竞赛”转向“实用化竞争”。无论是谷歌的Gemma4,还是阿里的Qwen3,都在努力降低本地部署门槛,让AI真正走进普通用户的设备中。对于用户来说,我们不用再为“参数焦虑”,只需根据自己的设备性能、使用场景,选择最适配的模型,就能发挥本地AI的最大价值——毕竟,能解决实际问题的模型,才是好模型。
五、互动话题:你的本地模型,选对了吗?
看完这场24GB Mac Mini上的实测,信任许多人都有了自己的思考:原来参数高不必定好用,适配才是王道。
不知道你平时使用本地模型吗?你用的是Gemma4、Qwen3,还是其他模型?有没有遇到过“参数高但运行卡顿”“速度快但输出质量差”的问题?
如果让你在24GB设备上选择,你会选Qwen3-8B的速度,还是Gemma4-12B的参数优势?你觉得本地模型的核心竞争力,是速度、参数,还是输出质量?
欢迎在评论区留言讨论,分享你的本地模型使用体验和选型技巧,协助更多小伙伴避开坑、选对模型!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











