
想象一个场景:你的团队花了大价钱上线了一个AI助手,问它”我们三季度的客户流失率是多少”,它洋洋洒洒写了一堆分析,最后输出的数字和你财务系统里的实际数据对不上——这就是企业Agent最典型的”幻觉”问题。
最近读到一篇论文《Ontology-Constrained Neural Reasoning in Enterprise Agentic Systems》,来自arxiv,地址是
https://arxiv.org/abs/2604.00555 。它回答了一个被许多人忽视却至关重大的命题:在企业场景下,AI最缺的不是”能力”,而是”边界”。
01 企业Agent落地,为什么总差点意思?
许多人以为企业Agent做不好,是由于模型不够强、知识库不够大。于是不断调Prompt、不断喂文档、不断fine-tuning——但效果始终差一口气。
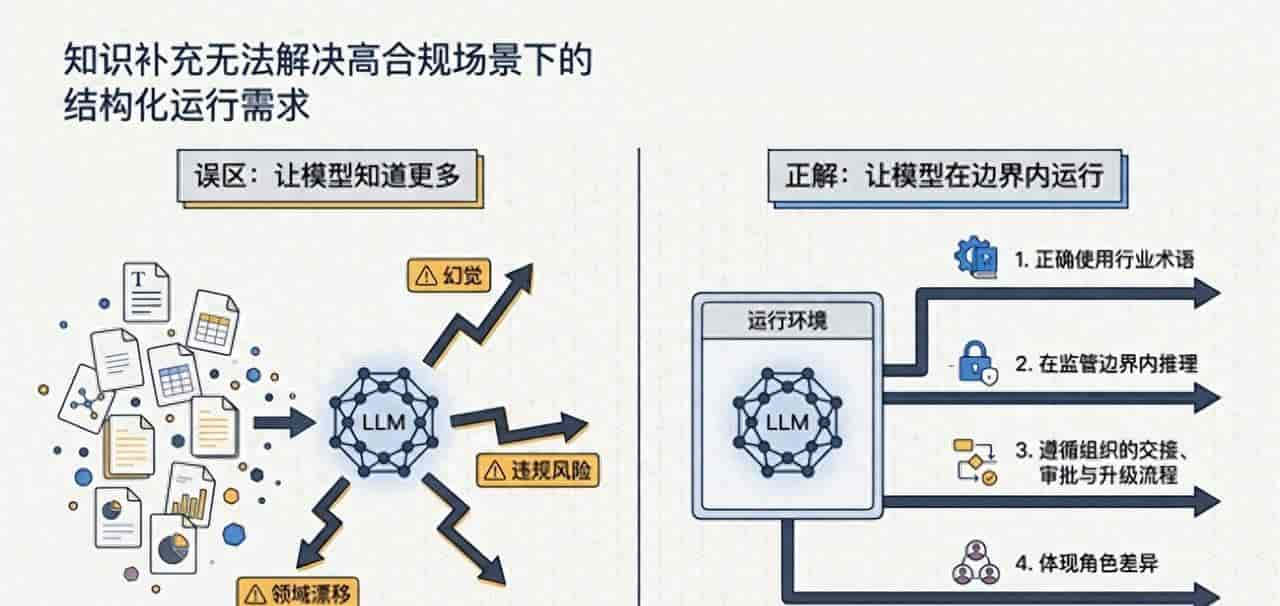
论文重新定义了这个问题:企业Agent至少要同时满足四类要求:
- 术语用对:CFO说的”ARR”和运营说的”ARR”可能不是一回事
- 监管合规:金融、医疗、法律场景,AI的推理必须在监管边界内
- 流程走通:判断之后要走交接、审批、升级,不是生成一段文字就完事
- 角色差异:同一个数据,给CFO看和给产品经理看,分析逻辑完全不同
这四件事,传统的Prompt工程、RAG检索、甚至是fine-tuning,都只能解决局部,无法构成一套完整的企业级”语义边界”机制。
换句话说,企业Agent的核心问题不是”让AI知道更多”,而是”让AI在什么边界内知道、推理和输出”。
02 三层本体,构建企业语义边界的核心框架
论文提出了一个形式化的企业本体框架:O = ⟨ R , D , I ⟩
这三个本体,分层解决了”谁来判断、在什么业务语境中判断、判断如何进入组织流程”三个根本问题。
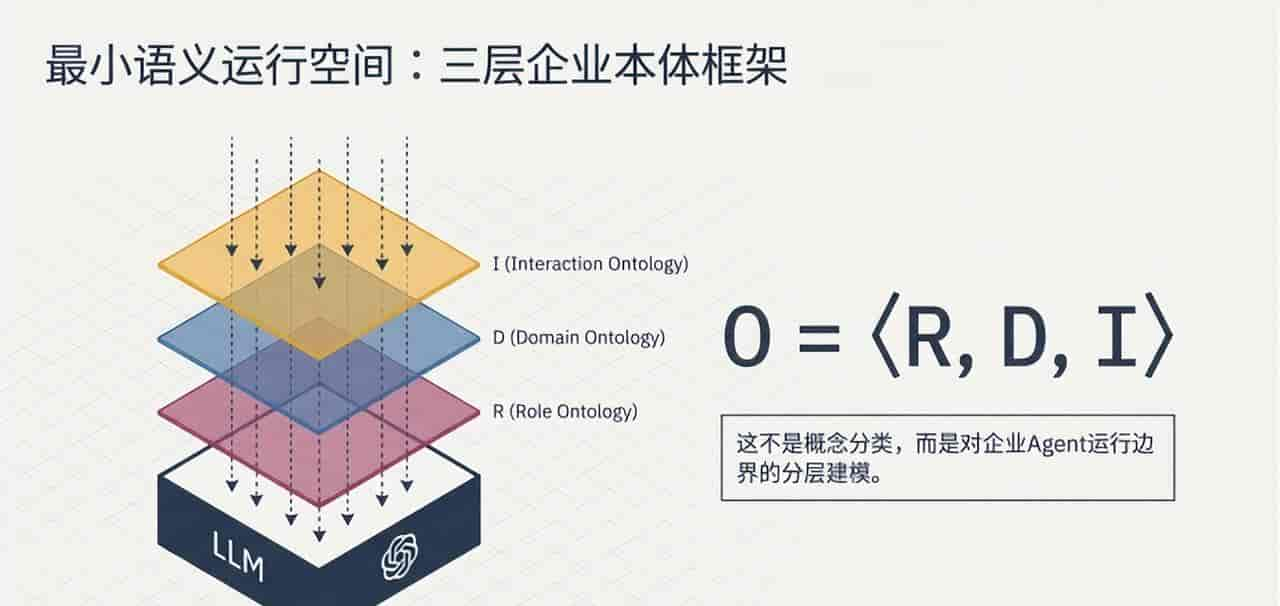
第一层:Role Ontology——约束”谁在判断”
同一个问题,不同角色的反应天差地别。
- 合规负责人看到一份合同,关注的是监管风险点
- 财务负责人关注的是指标口径和健康区间
- 产品经理关注的是市场表现和用户反馈
Role Ontology的核心,不是给AI加一段”人设Prompt”,而是正式定义每个角色的决策模式、指标关注点、沟通风格和授权边界。系统需要具备”perspective-aware reasoning”能力——知道自己在扮演谁,并且在这个角色下保持判断一致性。
第二层:Domain Ontology——约束”在什么业务语义中判断”
模型”知道一个概念”和”知道这个概念在当前行业的指标边界和规则适用条件”,是两件完全不同的事。
列如保险行业的”persistency rate”,术语模型认识,但:
- 行业基准是多少?
- 健康区间的阈值在哪里?
- 它适用哪套监管框架的披露要求?
Domain Ontology承担的就是这个角色——让AI不仅认识词,还要知道这个词在当前业务语境下的边界、口径和适用规则。
第三层:Interaction Ontology——约束”判断如何进入组织流程”
一个判断即使实际正确,只要绕过了应有的交接、审批或升级链路,在企业环境中依然是不合格输出。
Interaction Ontology管理的正是这些:handoff patterns(交接模式)、approval chains(审批链)、escalation paths(升级路径)。本体在这里不是知识库,而是组织运行规则的语义化映射。
03 本体怎么进运行时?技术架构一览
论文给出了FAOS系统的具体实现。本体不是简单拼进prompt,而是进入运行时多个关键位置:
上下文解析管线按租户行业加载ontology → 合并tenant overlays → 解析角色/领域/交互上下文 → 序列化并优化token budget。
关键工程细节:默认token budget 2000tokens;注入优先级为 Role > Domain > Interaction。
Agent执行图是一个9节点State Graph,节点包括意图分类、路由、任务分解、计划生成、并行执行、专业执行、质量裁判、结果聚合、升级处理。本体上下文主要在”专业执行”节点注入,治理约束则通过质量裁判和autonomy gates进入执行过程。
还有一个工程价值很高的设计:ontology-constrained tool discovery。工具发现综合考量语义相关性、领域匹配度、能力匹配度和角色匹配度四个维度,系统在SQL层做pushdown过滤,在600+注册技能上实现了sub-100ms的发现效率。
04 实验结论:本体的价值,主要体目前结构性约束层
论文在五个行业、四种条件下做了600次运行测试。
结果很清晰:本体约束带来的最大收益,聚焦在三类能力上——指标准确性、监管合规性、角色一致性,而不是表面表达或术语覆盖率。
还有一个反直觉但至关重大的发现:本体grounding的价值,与模型在该领域的预训练覆盖度成反比。
模型本来就熟悉的知识(列如保险里公开的combined ratio),本体注入反而可能带来干扰——结构化上下文占用了prompt空间,挤压了模型原本的parametric recall。
而模型预训练覆盖不足、本地化和监管长尾特征明显的知识(列如越南保险市场的特定规则),本体注入收益最大。
这说明:本体主要补的不是通用世界知识,而是企业专有知识、本地监管知识和长尾业务知识。在这类场景下,本体grouning不是加分项,而是接近必要条件。
05 技术落地:四步走的实操提议
结合论文已实现的部分和企业系统建设规律,这类架构真正落地,提议分四层推进:
第一步:先建业务对象层,而不是先做Prompt模板
先沉淀三类核心对象:角色对象(岗位职责、指标关注、权限边界)、领域对象(术语、实体、指标口径、规则边界)、交互对象(交接、审批、升级路径)。没有这一层,所有上下文注入和工具发现都会退化为”文档拼接”。
第二步:本体先进入输入侧和工具侧,不急于直接做输出验证
最现实的落地顺序是:先做context injection → 再做discovery-constrained tool registry → 再做治理过滤和autonomy gates → 最后再思考输出侧验证。输出验证一旦走到OWL符号推理层,复杂度会急剧上升。
第三步:把本体与技能注册表、治理系统绑定
本体最大的价值,是让能力暴露和治理控制建立在同一套语义边界上。技能注册时绑定domain path和capability tag;执行前按领域和角色过滤可见能力;高风险场景前置治理阈值和人工审批。如果做不到这一步,本体就容易退化为”知识标签体系”。
第四步:必须做自适应注入,而不是静态全量注入
论文已给出明确证据:对模型原本熟悉的概念,全量注入可能带来反效果。上下文注入应该是动态决策,按概念类型、行业、语言和角色差异调整注入策略和权重。
06 最后
回到开头的问题:企业Agent落地,为什么总差点意思?
由于大家都在努力让AI”知道更多”,却很少有人认真去建立**“可运行的语义边界”**。
RAG解决的是”取回什么材料”的问题。本体约束解决的是”在当前角色、领域、流程与治理条件下,允许系统如何理解、如何调用、如何输出”的问题。
在金融、保险、医疗、运营商这类高监管、高术语密度、高组织复杂度的场景里,后一个问题才是决定Agent能否进入核心业务链路的关键。
语义边界,才是企业Agent真正的护城河。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










