
摘要
这次系统了解了自编码器的基本原理及其作为自监督学习经典方法的代表性,详细阐述了其通过编码器-解码器结构实现数据压缩与重构的核心机制,并分析了去噪自编码器等变体的工作原理。课程进一步深入综述了扩散模型的理论基础、主流改进方向及其与VAE、GAN等生成模型的广泛联系,全面梳理了扩散模型在计算机视觉、多模态生成及科学计算等领域的革命性应用,最后剖析了其在理论理解、潜空间语义性、基本假设与计算成本等方面面临的关键挑战,为理解生成式AI的前沿发展提供了系统性的知识框架。
Abstract
This lecture systematically introduces the basic principles of the Auto-Encoder and its role as a classic method in self-supervised learning, detailing its core mechanism of data compression and reconstruction through an encoder-decoder structure, and analyzes the working principles of its variants such as the Denoising Auto-Encoder. The course further provides an in-depth review of the theoretical foundations of Diffusion Models, mainstream improvement directions, and their broad connections with other generative models like VAEs and GANs. It comprehensively outlines the revolutionary applications of diffusion models in fields such as computer vision, multimodal generation, and scientific computing. Finally, it examines the key challenges faced in terms of theoretical understanding, latent space semantics, fundamental assumptions, and computational cost, offering a systematic knowledge framework for understanding the cutting-edge developments in generative AI.
一.自编码器
1.了解自编码器
自编码器其实也可以算是自监督式学习的一环,所以再简单回顾下自监督式学习框架。自监督式学习先通过大量没有标注的资料训练一个模型,如完成“填空”或者预测下一个token的任务,训练完后就可以经过微调后将其用在其他下游任务中。
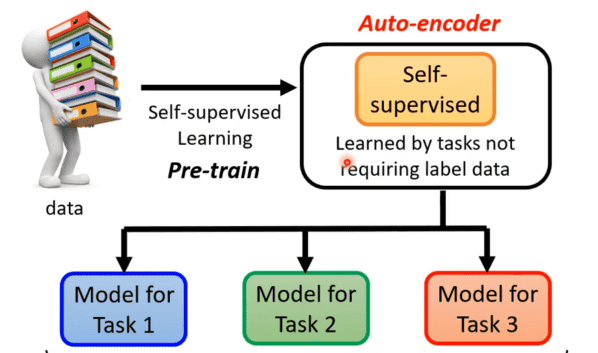
但是在自监督式学习这种不用标注资料就可以学习的任务中,在BERT以及GPT之前就已经有个更古老的不用标注资料的任务就叫做自编码器。
2.自编码器的运行
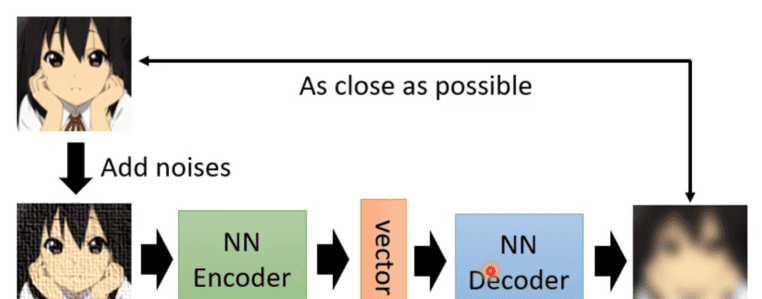
前面自监督式学习都是在用文字做例子,这里就先换成影像,假设有非常大量的图片在自编码器任务中。而自编码器中有两个网络编码器(encoder)和解码器(decoder),其中编码器是将输入的图片转成一个向量,接着这个向量作为解码器的输入,通过解码器之后便得到一个图片,而自编码器训练的任务就是使解码器输出的图片与编码器输入的图片越接近越好,这个过程也可以叫做重构。
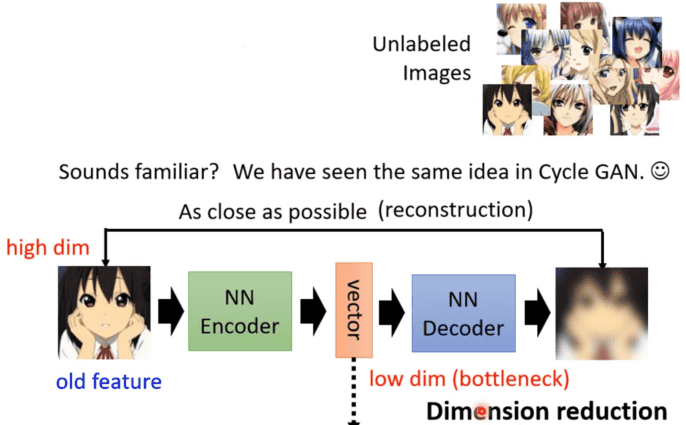
对于训练好的自编码器在下游任务中可以看作是对于将一个很长的向量经过编码器得到一个便于接下来任务使用的短向量也就类似向量降维的工具。
3.自编码器的优点
自编码器要做的就是将一个图片(假设图片为3×3)压缩后又还原会来,也就类似于将3×3的图片转为二维的向量再还原为3×3的图片。能够做到这件事对于影像来说,并不是所有的3×3的矩阵都是图片,而图片的变化是有限的,对应的情况总共也就那么些种类,从而就可以通过两个维度的向量来代表。
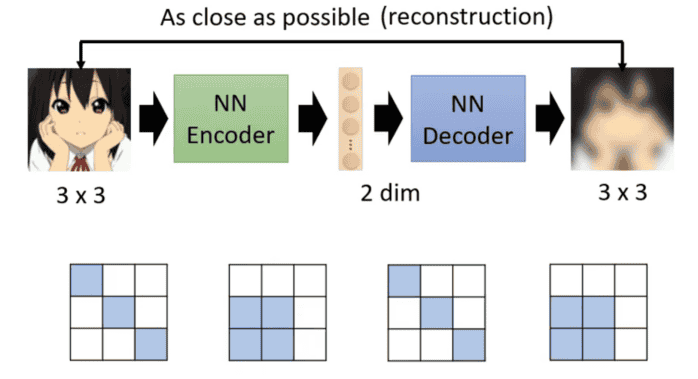
所以自动编码器是一种无需标注就能自动学习数据核心特征的神经网络。它能将高维数据压缩成低维精华表示,并从中有效重建,这一特性使其在数据降维、特征提取、去噪和异常检测等任务中表现出色。
而自编码器并不是一个新的想法,深度学习之父Geoffrey Hinton,在06在SCI的论文就有提到这个概念,只是那个时候的神经网络与现在的不同。
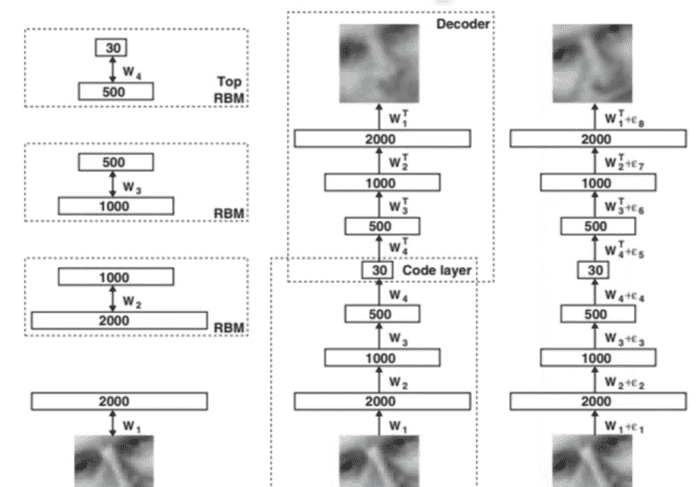
4.去噪自编码器(De-noising Auto-encoder)
自编码器还有一个常见的变形——去噪自编码器。其是将原本要输入到编码器的图片加上一些噪音,然后和自编码器一样运行,只是现在要还原的图片不是编码器的输入图片,而是加噪音之前的图片。所以现在编码器与解码器除了要还原原来的图片任务外,还要多做一个任务——学会将噪音去除。
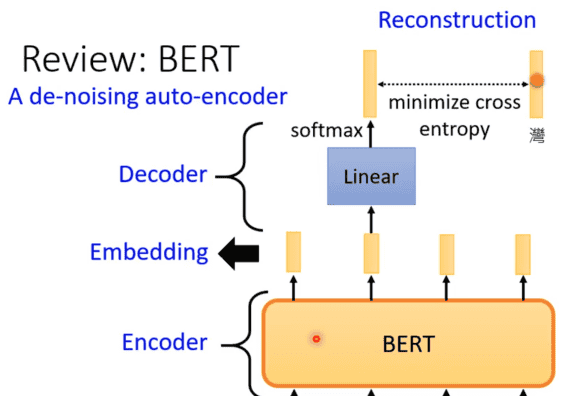
这个一个想法也并不陌生,就如之前学习的BERT,输入时的mask就相当于加噪过程,编码器就是将输入转成向量,接下来的线性模型就相当于解码器,还原被遮盖的地方。
二.《扩散模型:进展、应用与挑战综述》学习
扩散模型作为深度生成模型的新兴范式,凭借其卓越的样本质量和训练稳定性,已在多个领域实现突破性进展。本文基于《Diffusion Models: A Comprehensive Survey of Methods and Applications》一文,系统梳理了扩散模型的核心理论基础、主流改进方向(高效采样、似然估计、数据结构处理)及其与其他生成模型的广泛联系。同时,本文综述了扩散模型在计算机视觉、多模态生成、科学计算等领域的革命性应用,并深入剖析了其当前面临的理论理解、潜空间语义性、基本假设与计算成本等关键挑战,旨在为未来研究提供清晰的路线图。扩散模型通过定义前向噪声扰动与反向去噪生成的双过程,建立了强大的生成建模框架。其三大基础形式——去噪扩散概率模型、基于分数的生成模型和随机微分方程——在连续时间视角下被统一,为后续研究奠定了坚实基础。本综述旨在系统总结该领域的知识体系与前沿动态。
1.理论基础与改进方向
1.1 理论基础
扩散模型的核心在于一个参数化的马尔可夫链,通过逐渐去噪将简单先验分布转换为复杂数据分布。其中DDPM、SGM和Score SDE分别从变分下界、分数匹配和随机微分方程的角度提供了等价的建模方向,但是Score SDE的连续时间框架及其对应的概率流ODE最具通用性,为理论分析与算法设计带来了极大便利。
1.2 改进方向
研究主要围绕三个方面展开:
①高效采样:目的是为了解决迭代采样导致的高计算开销。方法可分为无学习采样(如DDIM、DPM-Solver等专用ODE/SDE求解器)与基于学习采样(如优化离散度、知识蒸馏、截断扩散)两类,后者可以通过额外训练成本换取数个数量级的推理加速。
②似然改进:优化模型对数据分布的拟合程度。通过噪声调度优化、学习反向过程方差以及利用概率流ODE进行精确似然计算,扩散模型在似然指标上可以达到甚至超越传统自回归模型的表现。
③特殊数据结构处理:通过定制化设计,扩散模型成功扩展至离散数据(如文本)、具有不变性的数据(如图、分子)以及流形结构数据,展现了其很好的泛化能力。
2. 联系与应用
2.1 与其他生成模型的结合
扩散模型并非孤立存在,它与一些主流生成模型存在深刻联系:
①VAE:DDPM在概念上可视为具有固定编码器的VAE,同时优化扩散模型可以看作是训练一个无限深的VAE。
②GANs:通过在GAN训练时向判别器中注入噪声可以解决由于输入数据分布与生成数据分布不重叠导致训练时的不稳定。同样的扩散模型与GAN结合可以提高其加速采样。
③归一化流:概率流ODE为扩散模型和归一化流之间架起了桥梁,其定义了一个从噪声到数据的可逆映射,这就是一个连续的归一化流
④自回归模型:自回归模型是强大的密度估计器,但采样慢。扩散模型可以提供另一种分解和生成顺序就如自回归扩散模型:将数据维度以任意顺序进行扩散和生成,兼具自回归的灵活性和扩散的并行生成潜力。平滑技术:在自回归建模中对数据分布进行平滑,然后用扩散式方法去噪,以提升样本质量。
⑤基于能量模型:分数函数与能量基模型的梯度密切相关,就如
扩散恢复似然:通过训练一系列在不同噪声水平下的条件EBMs来间接学习数据分布,避免了在原始高维空间中进行艰难的MCMC采样。
⑥大语言模型:扩散模型与大语言模型的融合构成了当前多模态AIGC的核心,其中LLM将复杂的用户指令分解为一系列具体的、可执行的生成步骤或布局描述,扩散模型负责细节执行。
2.2 应用生态
对于扩散模型的应用也越来越多:
计算机视觉:生成模型在图像生成、编辑、超分辨率、复原以及转换方面被广泛运用,在语义分割方面可以利用扩散模型学习到的丰富语义表示进行像素级分类,视频生成中将扩散模型扩展到时空维度、在点云生成与补全中为3D视觉任务生成3D点云。
多模态生成:其核心在于利用预训练文本编码器(如CLIP、T5) 将不同模态(尤其是文本)的信息对齐并注入到扩散过程的引导生成中,如文生图、文生3D、文生视频、文生音频等技术。
跨学科方面:扩散模型在药物设计、分子生成、材料科学和医学影像重建等跨学科领域展现出巨大潜力,体现出其已经从一个生成工具演进为助力科学研究与技术创新的得力助手。。
3. 现存挑战与未来方向
尽管成果显著,扩散模型仍面临一系列根本性挑战:
3.1 理论理解的缺失
目前对扩散模型为何有效缺乏 准确的理论解释。扩散模型的生成能力像是学习经验、发现经验,而非严格数学推导的结果。所以在未来需要建立更完善的理论框架,以解释其动态特性,并为网络架构、损失函数和噪声调度等超参数的选择提供系统性指导,而不是依赖经验性试探。
3.2 潜表示效果较差
与VAE和GAN不同,扩散模型的中间潜变量良好数据表示效果差、缺乏语义结构以及潜空间通常与数据空间同维。这导致其潜空间难以用于数据插值、属性编辑等需要结构化表示的下游任务。如何让扩散模型学习到紧凑、解耦的语义潜表示,是解锁其更高应用价值的关键。
3.3 基本假设的局限性
传统扩散模型是建立在“无限时间步长下数据完全高斯化”的假设,这在有限步采样中并不成立。所以为薛定谔桥和基于最优传输的生成建模等提供了有前景的替代框架的研究,这些方法旨在在有限时间内实现精确的分布转换。
3.4 计算成本与可访问性
尽管知识蒸馏等技术极大提升了推理速度,但训练最先进的扩散模型(尤其是视频、多模态模型)仍需巨大的计算资源和数据量。这导致了技术集中化风险。研究更高效的模型架构、训练算法,以及推动开源社区发展,对于保持该领域的开放与创新至关重要。
总结
自编码器作为一种经典的无监督特征学习模型,通过数据压缩与重构的有效机制,为特征提取与降维提供了重要基础,其去噪变体更是直接体现了学习数据本质特征的思想。而扩散模型作为当前生成式AI的核心范式,通过前向加噪与反向去噪的马尔可夫链框架,在图像、视频、多模态内容生成等领域取得了突破性进展。尽管扩散模型在生成质量与训练稳定性上优势显著,但其仍面临理论解释不完善、潜空间缺乏语义结构、计算成本高昂等根本性挑战。未来,通过深化理论理解、优化潜空间表示、探索更高效的采样与训练算法,扩散模型有望在保持其强大生成能力的同时,进一步提升效率与可访问性,从而在更广泛的科学与工程应用中发挥关键作用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











