
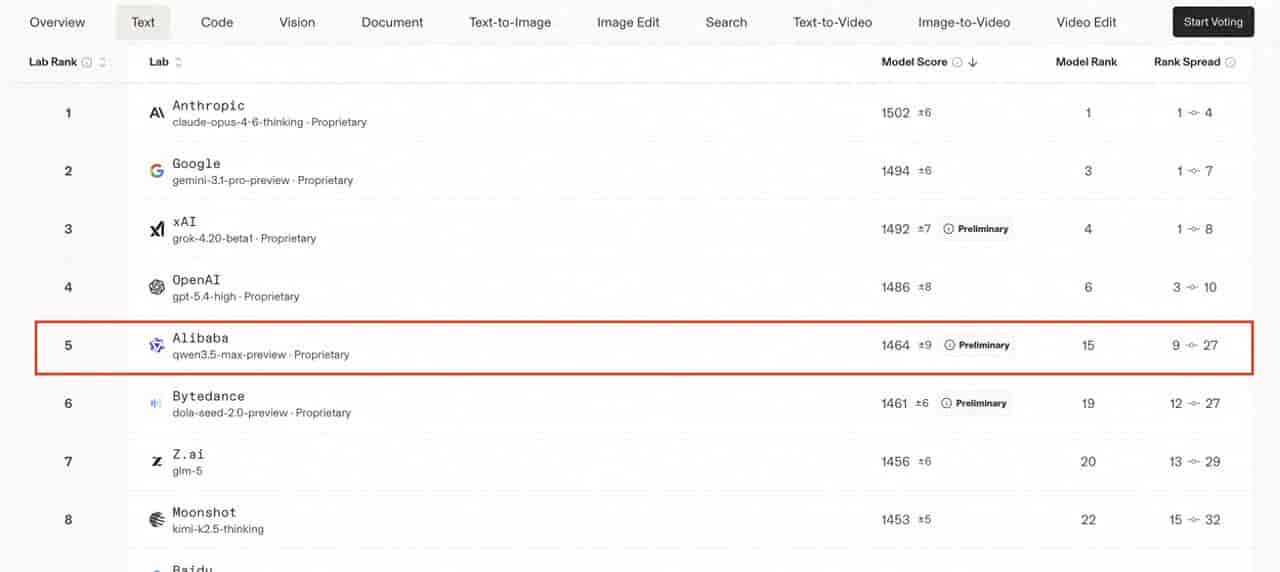
AI大模型赛道,向来是全球科技硬核竞争的核心战场。过去很长一段时间,头部席位始终被海外巨头牢牢把持,国产大模型大多徘徊在第二梯队,想要跻身全球前五,一度是遥不可及的目标。而就在近期,一条权威评测结果彻底打破僵局,让国产AI真正扬眉吐气:阿里通义千问3.5-Max-Preview在国际权威盲测平台LM Arena斩获1464分,强势位列全球第五、中国第一,数学能力同步跻身全球前五,这也是中国大模型首次跻身全球顶级梯队,直接改写了全球AI大模型的原有竞争格局!
核心成绩速览:LM Arena权威盲测1464分;全球大模型排名第五,中国厂商首次登顶该席位;数学能力全球前五;专家级文本处理能力全球前十;完胜GPT5.4、Claude4.5等多款海外顶级模型。
先搞懂:LM Arena凭什么是AI界“权威考场”?
许多朋友可能会疑惑,这个LM Arena评测到底有多权威?为什么这份排名能让整个国内科技圈直接沸腾?咱们先把这个核心背景讲透,避免大家把它当成普通的行业榜单。
LM Arena是由国际知名开源研究机构LMSYS打造的第三方匿名盲测平台,堪称AI大模型界最公平的“无差别竞技场”。它的评测机制完全杜绝了人为偏袒和品牌滤镜,采用模型两两匿名对战的模式,由全球数千名开发者、专业用户匿名盲测投票,只看实际落地性能,不看品牌出身,最终通过胜负率换算成ELO分数排名,全程没有任何公关操作空间,也是目前全球业内公认最客观、最具含金量的大模型评测榜单,远比厂商自宣的参数数据更有说服力。
正是这套完全中立的盲测规则,让LM Arena的排名含金量拉满。通义千问3.5能冲进全球前五,绝非单纯的分数亮眼,而是它的综合实战能力,得到了全球专业用户的实打实认可,绝非国内自嗨式成绩,足以印证国产大模型的真正硬实力。
不止总分亮眼!细分能力同样能打,数学短板彻底补齐
以往提起国产大模型,外界一直贴着固有标签:通识问答勉强够用,但逻辑推理、数学运算这类硬核能力始终是短板,尤其是复杂高数推导、专业逻辑算力领域,和海外顶级模型差距明显。而这一次,通义千问3.5-Max-Preview用实打实的评测分数,彻底打破了这个长期存在的偏见。
除了综合总分1464分稳居全球第五、国内第一,在数学能力这一最考验硬核算力的细分项上,它直接跻身全球前五,完美攻克了复杂逻辑推理、高等数学运算、专业公式推导等以往的难点;同时专家级文本处理、多场景实用推理能力也位列全球前十,整体性能均衡全面,没有任何明显短板,彻底摆脱了国产大模型“偏科”的诟病。
更值得一提的是,这款模型目前还是旗舰预览版,并非最终正式上线版本,后续还会根据海量用户反馈持续优化迭代,这也意味着它的分数和性能还有进一步提升的空间,未来潜力十分可观。
对照完整榜单排名就能清晰看到,通义千问3.5成功超越了GPT5.4、Claude4.5、Grok4.1等多款海外老牌顶级大模型,成为继OpenAI、Google、Anthropic三大国际巨头之后,第五个站稳全球第一梯队的玩家,彻底撕掉了国产大模型“跟风模仿、实力偏弱”的旧标签。
我的观点:这不是单一胜利,是国产大模型的集体崛起信号
作为长期关注AI领域的自媒体,我亲眼见证了国产大模型从初期的摸索追赶,到中期的稳步突破,再到如今实现弯道超车的全过程,看到这份国际权威榜单成绩时,真心觉得格外感慨。通义千问3.5的这次登顶,从来不是阿里一家企业的胜利,而是整个国产AI大模型行业的里程碑式突破,更是中国AI自主研发实力的聚焦展现。
第一,打破海外技术垄断,国产AI有了全球话语权。过去提起顶级大模型,大家只会想到GPT、Claude,目前我们终于有了能和全球巨头正面硬刚的产品,而且是在最公平的盲测中胜出,这意味着中国AI技术不再是陪跑者,而是正式成为全球AI赛道的核心玩家。
第二,短板补齐,国产大模型走向全面成熟。通义千问3.5不仅总分拔尖,数学、推理这些以往的弱项直接拉满,证明国产大模型已经摆脱了“偏科”困境,从单纯的参数堆砌,转向了实用性能、硬核算力、场景落地的全方位升级,更贴合实际使用需求。
第三,开源+闭源双轮驱动,行业生态越做越强。实则今年以来,阿里通义千问已经陆续开源了Qwen3.5系列多款模型,覆盖0.8B到397B共8种参数规模,小到轻量级应用,大到旗舰级算力,全尺寸覆盖,而且同参数量级性能均处于全球领先。这种开源共享的模式,也在带动整个国产AI行业共同进步,形成良性竞争。
写在最后:国产AI的黄金时代,真的来了
回望国产大模型的发展之路,从早年被海外技术压制、只能被动跟随,到沉下心深耕自主研发、攻克核心算力短板,再到如今登顶国际权威盲测、跻身全球前五,短短几年时间,我们就完成了从跟跑到并跑、再到局部领跑的关键跨越,速度之快、突破之大,足以让行业振奋。
通义千问3.5的1464分,从来不是一个冰冷的数字,而是国产AI技术实力的最好证明。这也用实际告知我们,只要坚持自主研发、深耕核心算力,国产科技完全能在全球顶级赛道站稳脚跟,甚至实现反超。
接下来,随着通义千问3.5正式版的迭代优化,再加上国内其他大模型厂商的持续发力,全球AI大模型的竞争格局势必会进一步重塑。对我们普通用户而言,最直观的福利就是,未来能用上更智能、更硬核、更贴合国内使用场景的国产AI产品,不用再过度依赖海外模型,这就是技术进步带给大众最实在的红利。
互动话题:你实际用过通义千问吗?对比海外大模型,你觉得国产AI的使用体验差距已经缩小了吗?评论区聊聊你的真实使用感受~
#AI技术##阿里千问3.5##大模型#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











