
目前各大模型厂商都在不断推出新模型,眼花缭乱。
许多人想知道不同模型到底处于什么水平,列如最近 GLM 4.7 出来许多人很想知道水平怎样,往往得四处打听,可不同人给出的答案又不一样。
那有没有一些榜单,能让我们一眼看出它们的大致实力?
这篇文章给大家分享几个比较不错的榜单,大家可以适当参考。
常见榜单
lmarena
- 平台特点:由 LMSys 团队运营,采用“人类对战评测”(Arena,对比两家模型回答,用户盲评哪一个更好),用 Elo 评分做排序,更贴近真实使用偏好。
- 覆盖范围:不仅有通用文本,还分 Text、WebDev、Vision、Text‑to‑Image、Search、Text‑to‑Video 等多个子榜单。
- 使用价值:适合想看“在真实用户眼里,哪个模型更好用”的场景,列如选聊天、写作、写网页的小白或开发者。
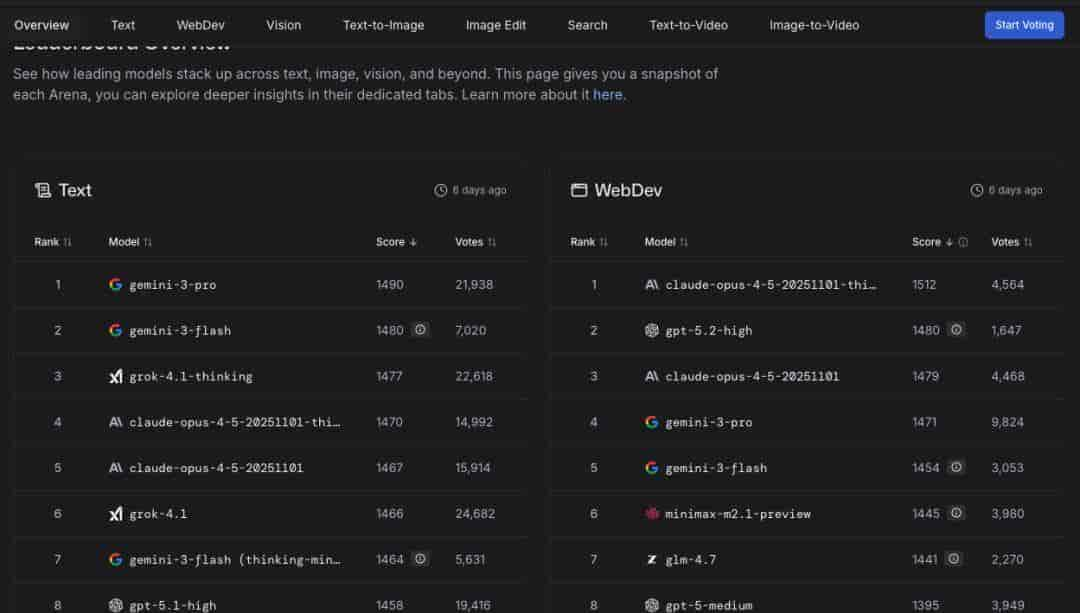
https://lmarena.ai/zh/leaderboard
Artificial Analysis
Artificial Analysis 是一家独立的 AI 测评与分析公司,自我定位是“独立的 AI benchmark & analysis 公司”,专门做模型性能、成本等对比评估,为企业和开发者提供选型参考。
综合排行
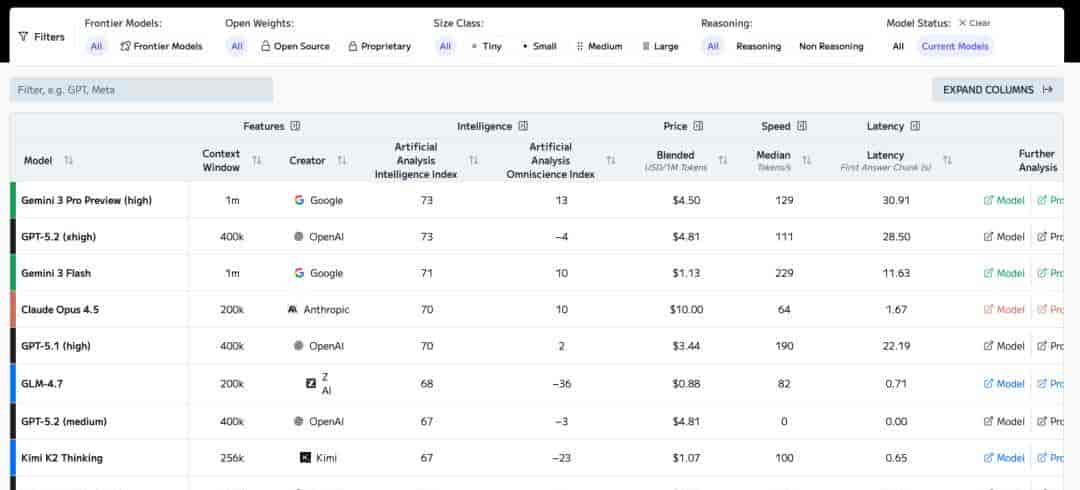
https://artificialanalysis.ai/leaderboards/models
综合排行(Models Leaderboard):按“智能、价格、推理速度、上下文长度”等多维度给上百个模型打分,可以看到每个模型在不同能力和成本上的折中。
编码领域
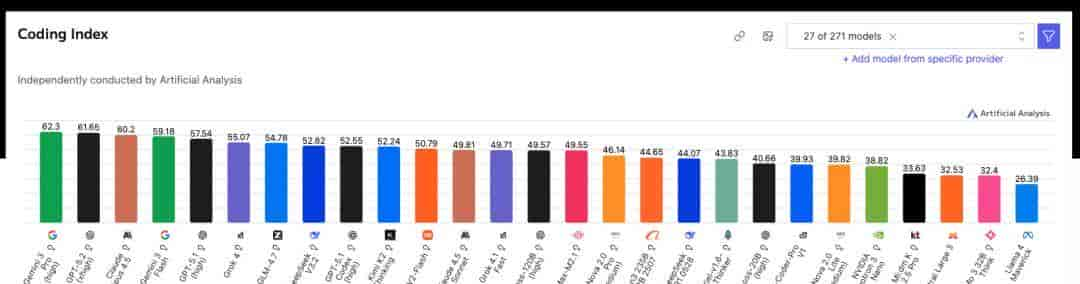
https://artificialanalysis.ai/models/capabilities/coding
编码领域榜(Coding capabilities):单独抓出“代码能力”相关基准(如代码生成、修复、竞赛题等),比较各模型在编程任务上的表现,更偏工程与生产力导向。
SuperCLUE
面向“中文通用大模型”,重点关心“在一系列中文任务上的整体表现如何,和国际模型、人类水平差距多大”。包含多轮开放问答、客观题、匿名对战等多个子基准,按月更新。
通用榜
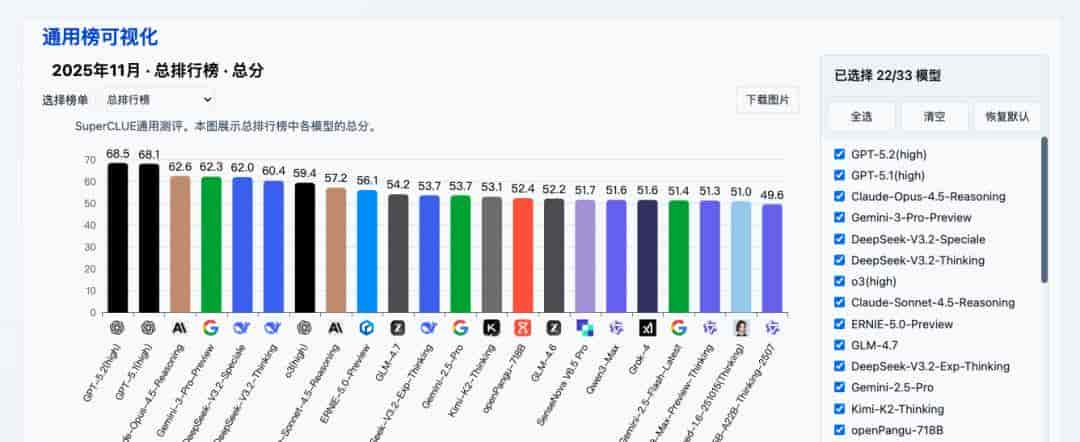
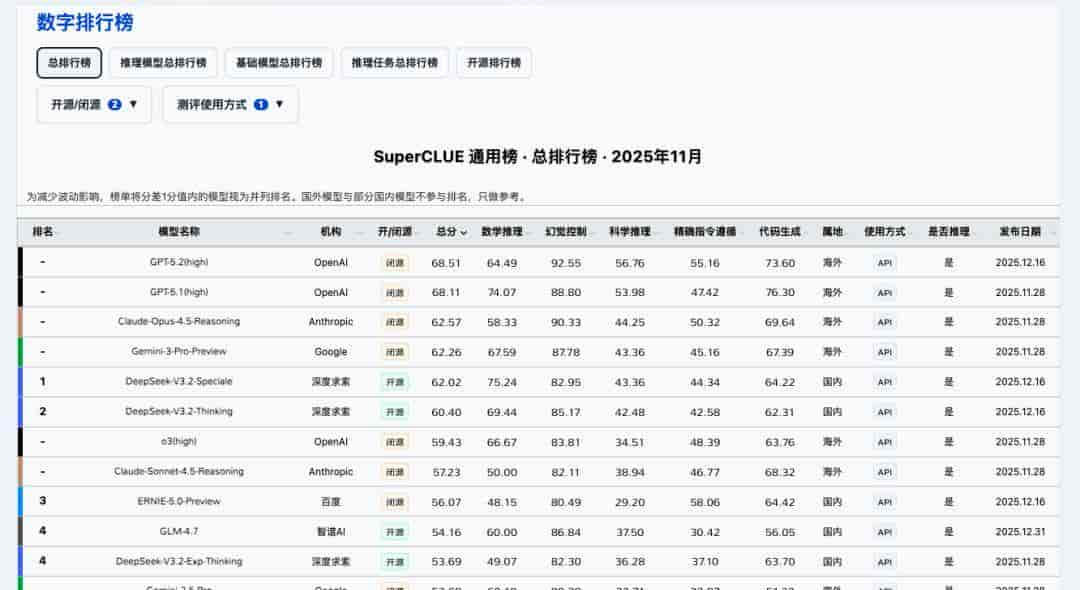
https://www.superclueai.com/generalpage
专项榜单
https://www.superclueai.com/benchmarkselection?category=specialized
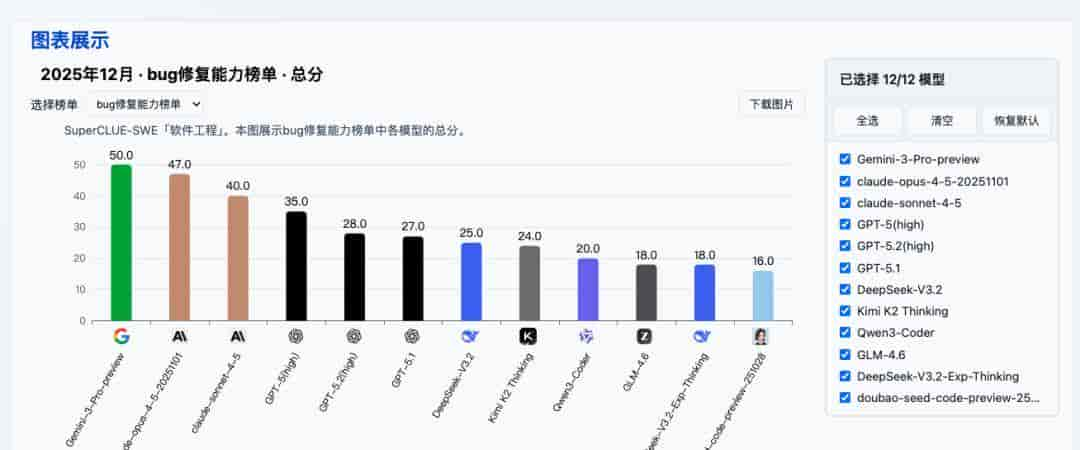
https://www.superclueai.com/specificpage?category=specialized&name=SuperCLUE-SWE%E3%80%8C%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B%E3%80%8D&folder=SWE
llm-stats
做成“信息面板”,聚焦展示各大模型在多种公开基准上的分数,同时附带价格、上下文长度等元信息,可对多个模型进行横向对比。
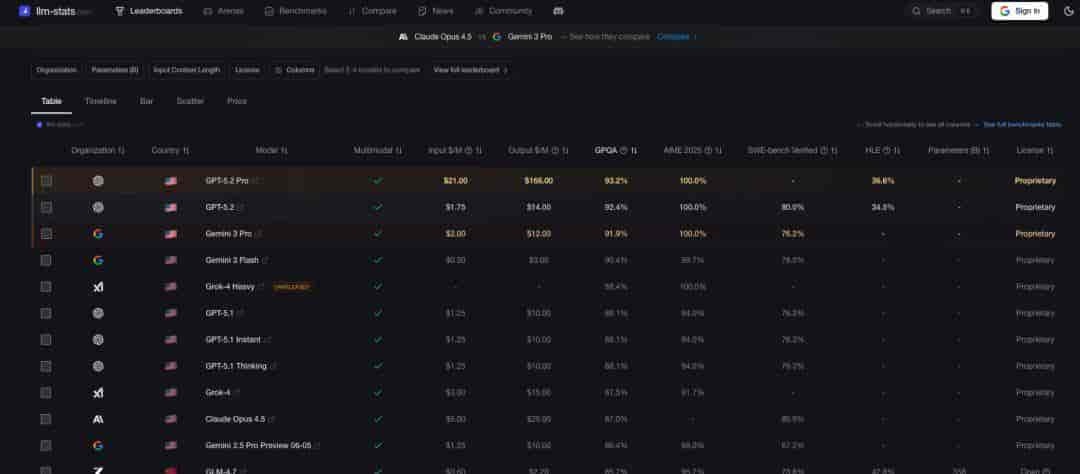
https://llm-stats.com/leaderboards/llm-leaderboard
写在最后
需要强调的是,大模型榜单只是一个参考。
有些模型在榜单上的表现超级不错,但实际使用的话可能会有一些折扣。
而且同一个模型在不同的任务上,它的表现也会有差异。我们还是要以自己业务实际的测评,自己实际的使用体验为准。
—-
欢迎关注我的公众号:悟鸣AI,后续会陆续分享比较有用的 AI 工具和比较好的 AI经验,比较客观理性的 AI 观点等。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











