
《迈向AI智能体可靠性科学》(Towards a Science of AI Agent Reliability)通过对14种主流模型在两个基准测试上的深入评估,提出了关于AI智能体可靠性的系统化分析框架。
核心观点
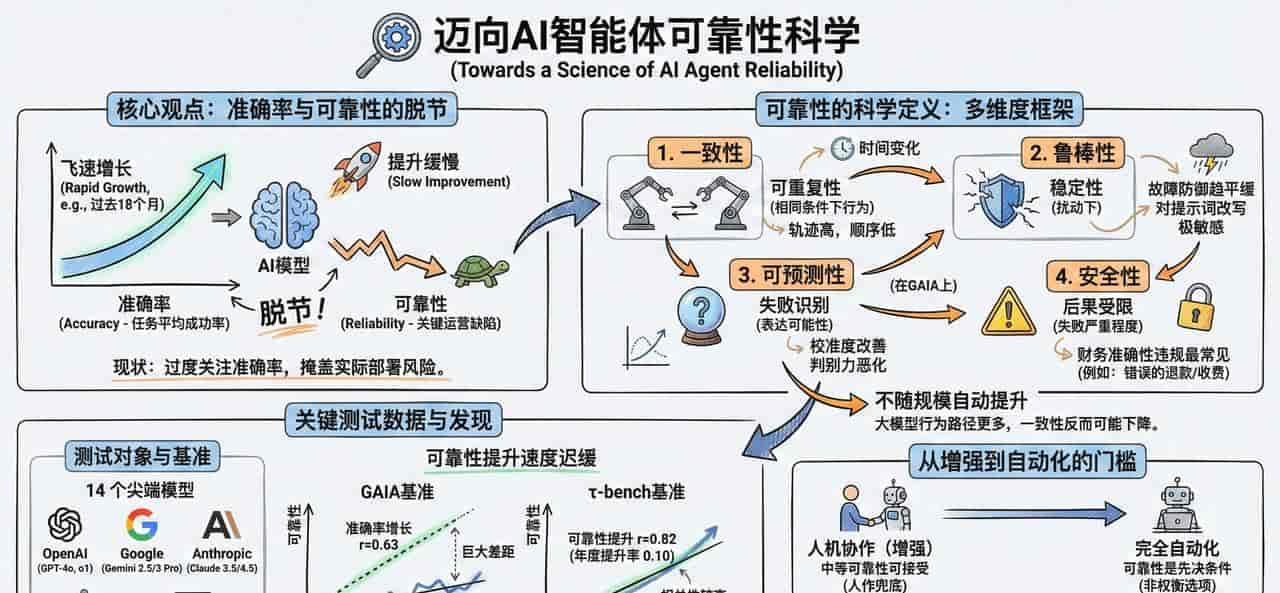
- 准确率与可靠性的脱节:论文指出,现有的评估范式过度关注任务平均成功率(准确率),这掩盖了智能体在实际部署中可能出现的关键运营缺陷。实验表明,尽管在过去18个月中模型能力(准确率)飞速增长,但可靠性的提升却超级缓慢。
- 可靠性的多维度科学定义:可靠性不应被视为单一指标,而应从四个关键维度进行衡量:一致性(一样条件下行为的可重复性)、鲁棒性(在扰动下的稳定性)、可预测性(能否识别并表达失败的可能性)以及安全性(失败后果的严重程度是否受限)。
- 可靠性并不会随规模自动提升:研究发现,提高模型规模或准确率并不必定会自动改善可靠性。例如,较大的模型虽然解决问题的能力更强,但由于其行为路径更多,在某些任务上的行为一致性反而可能下降。
- 从“增强”到“自动化”的门槛:论文强调,对于“人机协作(增强)”场景,中等可靠性尚可接受,由于人可以作为兜底;但对于完全“自动化”场景,可靠性是部署的先决条件,而不单纯是准确率的权衡。
关键测试数据
- 测试对象与基准: 评估了来自 OpenAI、Google 和 Anthropic 的 14 个 尖端模型(涵盖 GPT-4o、o1、Gemini 2.5/3 Pro、Claude 3.5/4.5 等)。 使用了两个互补的基准测试:GAIA(模拟真实世界通用任务)和 $ au$-bench(模拟带有工具调用和复杂策略的客户服务场景)。
- 可靠性提升速度迟缓: 在 GAIA 基准上,整体可靠性随时间提升的相关性仅为 $r=0.46$(年增长斜率为 0.03),远低于准确率的增长速度($r=0.63$)。 在 $ au$-bench 上,虽然相关性较高($r=0.82$),但年度提升率也仅为 0.10。
- 维度特定的发现: 一致性(Consistency):存在明显的“知道做什么但不知道何时做”的缺口。模型的轨迹分布一致性($Cd_{traj}$)一般较高,但顺序一致性($Cs_{traj}$)显著较低,表明其规划路径在多次运行中极不稳定。 鲁棒性(Robustness):大多数模型对故障和环境变化的防御已趋于平缓(接近 1.0),但对**提示词改写(Prompting)**仍表现出极高的敏感性,尤其在开放式任务(GAIA)中,改写可能导致表现大幅下降。 可预测性(Predictability):校准度(Calibration,即自信度与实际准确率的匹配度)在近期模型(特别是 Claude 系列)中改善明显,但在 GAIA 上的判别力(Discrimination,即区分难易任务的能力)却有所恶化。 安全性(Safety):在 $ au$-bench 的模拟中,财务准确性违规(如错误的退款/收费金额)是最常见的失败模式。
未来的 AI 智能体评估必须超越单一成功率,采用多运行、多扰动的动态基准测试,并将其作为治理和部署的关键标准。
arxiv.org/pdf/2602.16666v1
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











