

你有没有遇到过这种场景:想把客服日志、用户数据喂给 AI 模型训练,却担心里面夹杂着姓名、手机号、身份证?OpenAI 今天开源的 Privacy Filter,就是专门解决这个问题的——本地运行、无需 API、一次前向传播搞定 8 类敏感信息检测,精度高达 97.43% F1。

什么是 OpenAI Privacy Filter?
OpenAI Privacy Filter 是 OpenAI 于 2026 年 4 月 22 日开源的一款个人身份信息(PII)检测与脱敏模型。它是一个双向 Token 分类模型,专为高吞吐量数据清洗工作流设计。
与传统正则表达式或基于规则的工具不同,Privacy Filter 具备深度语言理解能力——它不只是找”像手机号格式的字符串”,而是真正理解上下文,能精准区分”公众人物信息”和”普通公民隐私数据”。
核心卖点:1.5B 总参数、仅 5000 万活跃参数、Apache 2.0 开源、可商业使用、完全本地运行——数据绝对不出你的服务器!
八大 PII 检测类别

Privacy Filter 支持 8 种隐私信息的精准检测与脱敏:
- • private_person — 个人真实姓名
- • private_address — 家庭住址、邮政地址
- • private_email — 私人电子邮箱
- • private_phone — 手机号、固定电话
- • private_url — 个人主页、私人文件链接
- • private_date — 出生日期、纪念日等隐私时间
- • account_number — 信用卡号、银行账号、身份证号
- • secret — 密码、API Key、私钥等机密凭证
️ 快速上手:3 分钟跑通示例
安装
# 克隆仓库并安装
git clone https://github.com/openai/privacy-filter.git
cd privacy-filter
pip install -e .
# 下载模型(约 3GB)
opf download一键脱敏(最常用)
# 单行文本脱敏
echo "请联系张三,邮箱 zhangsan@example.com,电话 138-0000-1234" | opf redact
# 输出结果
# 请联系 [PRIVATE_PERSON],邮箱 [PRIVATE_EMAIL],电话 [PRIVATE_PHONE]Python API 调用
from opf import PrivacyFilter
# 初始化模型
pf = PrivacyFilter()
# 单文本脱敏
text = "客户王梅的银行卡号为 6228 4812 3456 7890,密码是 mySecret@123"
result = pf.redact(text)
print(result)
# 客户 [PRIVATE_PERSON] 的银行卡号为 [ACCOUNT_NUMBER],密码是 [SECRET]
# 批量处理(高吞吐场景)
texts = [
"联系邮箱:alice@corp.com,地址:北京市海淀区中关村大街1号",
"API Key: sk-abc123xyz,开发者:李四",
]
results = pf.redact_batch(texts)
for r in results:
print(r)准确率/召回率调节
# 提高召回率(宁可误报,不能漏报)—— 适合医疗、金融场景
pf = PrivacyFilter(recall_bias=0.8)
# 提高准确率(减少误报)—— 适合新闻、公开数据清洗
pf = PrivacyFilter(precision_bias=0.8)重大:默认模型下载路径为 ~/.opf/privacy_filter,也可通过环境变量 OPF_CHECKPOINT 指定自定义路径。
性能基准测试
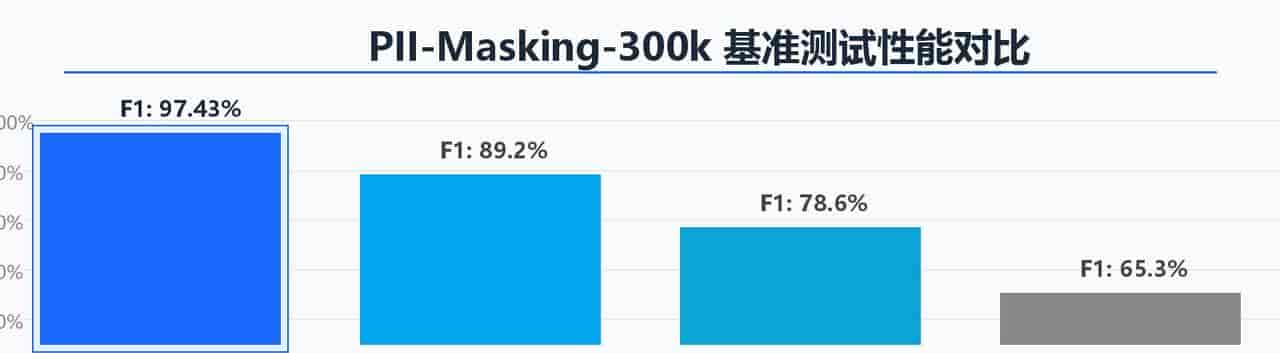
在权威的 PII-Masking-300k 基准上,Privacy Filter 大幅领先主流竞品:
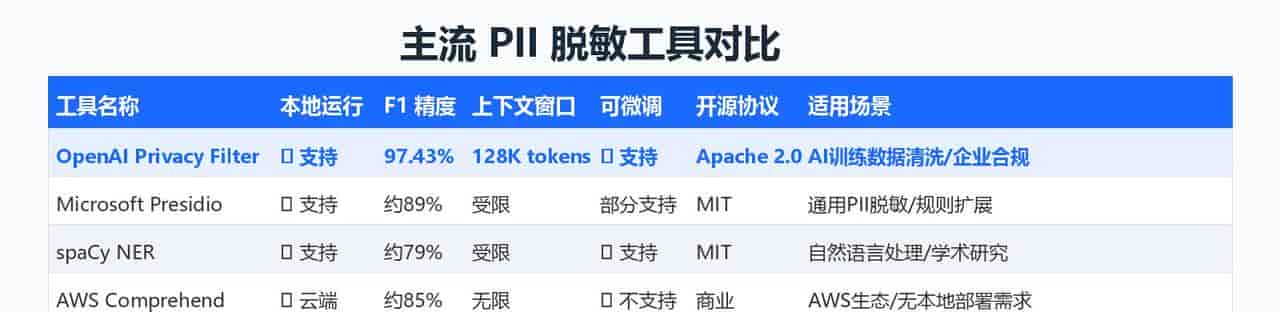
指标Privacy FilterMicrosoft PresidiospaCy NERF1 分数97.43%约 89%约 79%准确率96.79%约 88%约 77%召回率98.08%约 90%约 80%128K 上下文✅ 支持❌ 受限❌ 受限本地运行✅ 支持✅ 支持✅ 支持可微调✅ 支持部分支持✅ 支持
工作流程
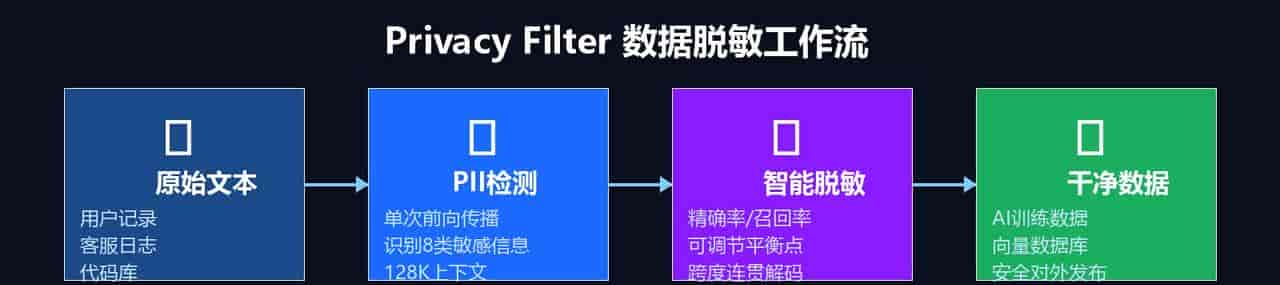
Privacy Filter 的处理流程极其高效:
- 1. 输入原始文本 — 客服日志、用户记录、代码库均可
- 2. 单次前向传播 — 一次扫描即完成全部 8 类 PII 识别,无需多轮处理
- 3. 智能跨度解码 — 受限 Viterbi 算法保证检测结果的连贯性,不切分词语
- 4. 输出干净数据 — 直接用于 AI 训练数据集、向量数据库索引或对外发布
微调工作流(针对特定领域)
# 准备少量标注数据(JSON 格式)
# 微调命令
opf train
--data ./my_labeled_data.json
--output ./my_custom_model
--epochs 3
# 使用微调后的模型
opf redact --checkpoint ./my_custom_model < input.txt官方数据:在领域特定数据上,仅用少量标注样本微调,F1 可从 54% 提升至 96% 以上。
适用场景
场景 1:AI 训练数据清洗
功能说明:在将用户数据(聊天记录、客服日志、评价内容)用于模型训练前,自动批量删除所有个人隐私信息。
输入要求:原始文本文件(TXT/JSON/CSV 均可)
输出效果:脱敏后的纯净数据集,个人信息已替换为标准占位符
适用场景:电商平台评论数据训练、客服机器人语料清洗、医疗问诊记录脱敏
场景 2:企业数据合规审计
功能说明:定期扫描企业内部文档、数据库导出文件,检测是否存在未脱敏的敏感信息,生成审计报告。
输入要求:任意文本文件或数据库文本字段
输出效果:高亮显示检测到的 PII 位置及类别,支持批量报告
适用场景:GDPR 合规审查、等保三级数据安全扫描、数据泄露预防
场景 3:RAG 知识库安全入库
功能说明:在将企业文档 embedding 到向量数据库前,自动清洗掉员工手机号、客户信息等敏感内容,防止 AI 问答系统”被诱导”泄露隐私。
输入要求:企业内部文档(PDF/Word/TXT)
输出效果:脱敏后的文本,可安全写入向量数据库
适用场景:企业内部知识库构建、客户服务 AI、HR 系统智能问答
用户群体总结
- • ✅ AI 应用开发者:处理用户数据前的必备合规工具
- • ✅ 数据工程师:大规模训练数据集清洗,替代昂贵的人工标注
- • ✅ 企业 IT/安全团队:数据合规审计,满足 GDPR、个保法要求
- • ✅ 学术研究者:在论文中安全发布含敏感信息的数据集
- • ❌ 不适合:需要法律级别匿名化保证的场景(需结合人工审查)
与竞品对比
定价方案
Privacy Filter 完全免费开源,Apache 2.0 协议允许:
- • ✅ 商业使用
- • ✅ 修改源码
- • ✅ 私有部署
- • ✅ 分发修改版本
开源协议: Apache-2.0
完全免费!本地运行零成本,相比 AWS Comprehend 按量付费,处理百万条数据可节省数千美元!
总结
OpenAI Privacy Filter 是 2026 年 4 月最值得关注的开源工具之一。它解决了 AI 时代一个核心痛点:如何安全、高效地处理含隐私信息的文本数据。
97.43% 的 F1 分数、128K 长上下文、完全本地运行、Apache 2.0 协议——这四点叠加,让它成为目前性价比最高的 PII 脱敏方案。
推荐指数: ⭐⭐⭐⭐⭐(满分 5 星)
适合人群: AI 开发者、数据工程师、企业安全合规团队
GitHub 仓库: openai/privacy-filter
模型下载: Hugging Face
数据截至 2026 年 4 月 23 日,最新信息请以官方 GitHub 为准。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











