在AI智能体的技术体系中,Token(令牌)是大语言模型(LLM)处理文本的最小单位,其计算逻辑直接影响模型上下文窗口利用率、API 调用成本及响应效率 —— 无论是Skills的分层加载(控制在 5k tokens 内)、RAG 的检索片段筛选,还是Agent的多轮对话管理,都需以精准的 Token 计算为基础。
一、 为什么需要Token,它的功能作用是什么
在大语言模型(LLM)及 AI 智能体的技术体系中,Token 的存在是模型实现高效训练、推理及资源管控的核心前提,其本质是将非结构化文本转化为模型可理解的结构化语义单元,解决了 “文本直接处理效率低、算力消耗大、语义捕捉难” 三大关键问题。
1.1 核心必要性:解决文本与模型的 “语义适配” 难题
LLM 无法直接处理人类的自然语言文本(如汉字、英文单词),只能识别和运算整数编码。Token 作为 “文本→模型可识别编码” 的中间载体,是连接自然语言与 AI 模型的桥梁,其必要性体目前两个层面:
- 规避字符级处理的低效性
- 若直接以 “字符” 为单位处理文本,会存在两个致命问题:
- 语义割裂:例如中文 “人工智能” 拆分为单个字符 “人”“工”“智”“能” 后,失去了组合后的完整语义;英文 “unhappiness” 拆分为字母后,也无法直接表达 “不开心” 的含义。
- 算力爆炸:字符数量远大于 Token 数量,以一本 10 万字的中文书为例,字符数约 10 万,按 GPT 分词规则 Token 数约 6.7 万,直接处理字符会让模型参数规模和计算量翻倍。
- 平衡语义完整性与计算效率
- Token 的拆分逻辑遵循 “语义优先” 原则,会将文本拆分为 “最小独立语义单元”:
- 英文中,“hello”“world”“un-happiness”(词根 + 词缀)是 Token,既保留语义,又避免拆分为字母;
- 中文中,“苹果”“智能体”“机器学习” 等常用词会被合并为单个 Token,而生僻词或单字则独立成 Token。
- 这种拆分方式让模型在 “捕捉完整语义” 和 “控制计算量” 之间达到最优平衡。
1.2 Token 的四大核心作用
1.2.1 实现文本的向量化编码,支撑模型训练与推理
这是 Token 最基础的作用。LLM 的训练和推理过程本质是对 Token 序列的数学运算,具体流程为:
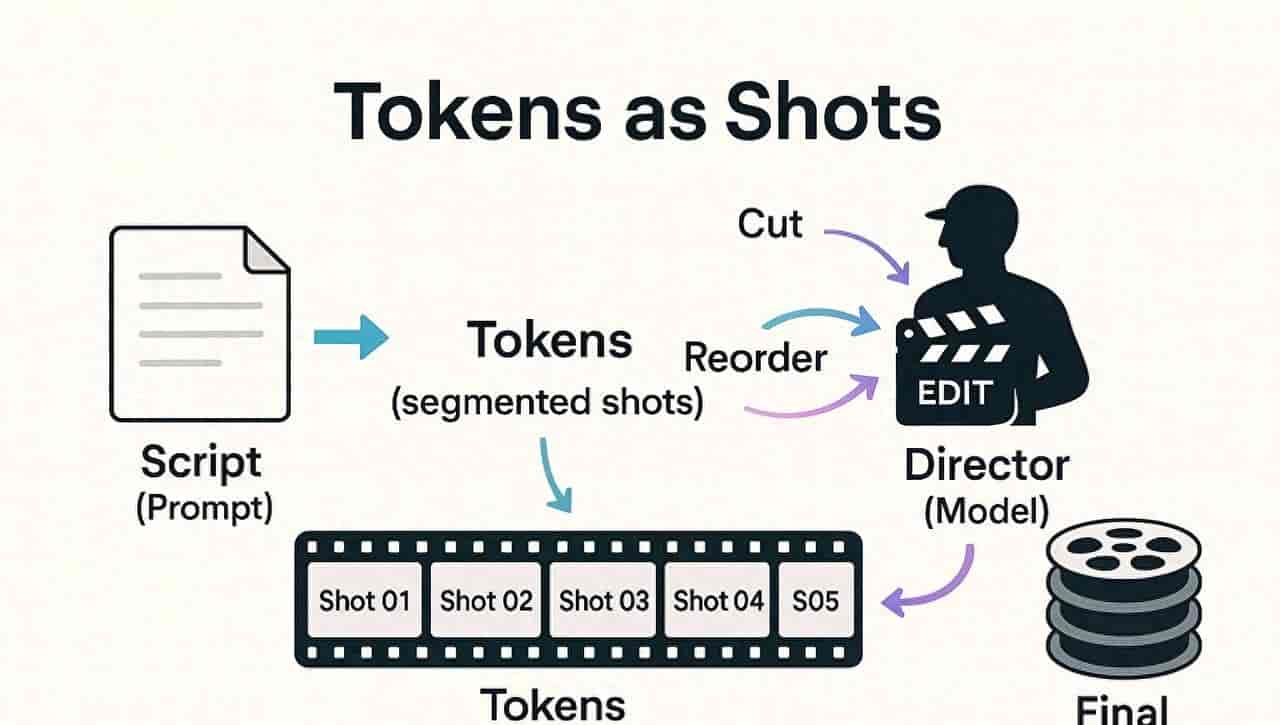
- 分词:将输入文本拆分为 Token 序列(如 “AI 智能体的 Token 计算”→[“AI”, “智能体”, “的”, “Token”, “计算”]);
- 编码:通过分词器(Tokenizer)将每个 Token 映射为唯一整数 ID(如 “智能体”→ID 12345);
- 嵌入:将整数 ID 转化为高维向量(Embedding),作为模型的输入特征;
- 运算:模型基于向量序列进行语义理解和文本生成,最终再将输出的 Token ID 序列解码为自然语言。
- 没有 Token,文本就无法转化为模型可运算的数学形式,LLM 的训练和推理都无从谈起。
1.2.2 定义模型的上下文窗口,管控输入输出长度
LLM 的上下文窗口(Context Window) 是指模型一次能处理的最大 Token 数量(如 GPT-4o 为 128k Token,Claude 3 Opus 为 200k Token),这个核心参数由 Token 直接定义,其作用体目前:
- 限制输入输出规模:超过窗口上限的文本会被截断,模型无法处理超出部分的语义;
- 平衡性能与成本:窗口越大,模型能理解的上下文越长(如长文档、多轮对话),但算力消耗和推理延迟也会显著增加。
- 在 AI 智能体中,Token 是上下文管理的核心单位—— 例如 Skill 的核心指令需控制在 5k Token 内,RAG 检索的文本片段需按 Token 数筛选,都是为了适配模型的上下文窗口限制。
1.2.3 作为 API 调用与成本核算的计费单位
主流 AI 模型的 API 收费(如 OpenAI、Anthropic)均以 “输入 Token + 输出 Token” 的总数量 为计费依据,缘由在于:
- Token 数直接反映了模型的计算量:处理 1k Token 的文本,模型需要完成 1k 次向量运算和语义推理;
- Token 数比 “字符数”“单词数” 更精准:一样字符数的中文和英文,Token 数差异可达 30%,以 Token 计费能更公平地反映实际算力消耗。
- 对企业级 AI 智能体而言,Token 计数是成本管控的关键—— 通过优化 Skill 的分层加载、RAG 的片段筛选,可有效减少 Token 消耗,降低运营成本。
1.2.4 支撑多语言适配与语义精准捕捉
不同语言的文本结构差异极大,Token 的分词模型可针对不同语言做定制化优化,实现跨语言的语义统一处理:
- 英文分词模型:基于 BPE 算法,优先合并高频词根和词缀;
- 中文分词模型:基于 Unigram 或语义单元算法,优先合并常用词和专业术语;
- 小语种分词模型:通过扩充词表,适配低资源语言的语义单元。
- 这种适配能力让 LLM 能处理多语言文本,也让 AI 智能体可跨语言执行任务(如多语言文档翻译、跨境客服)。
二、 如何计算Token,它的技术原理是什么
2.1 Token 的本质:不是字符,是 “语义片段”
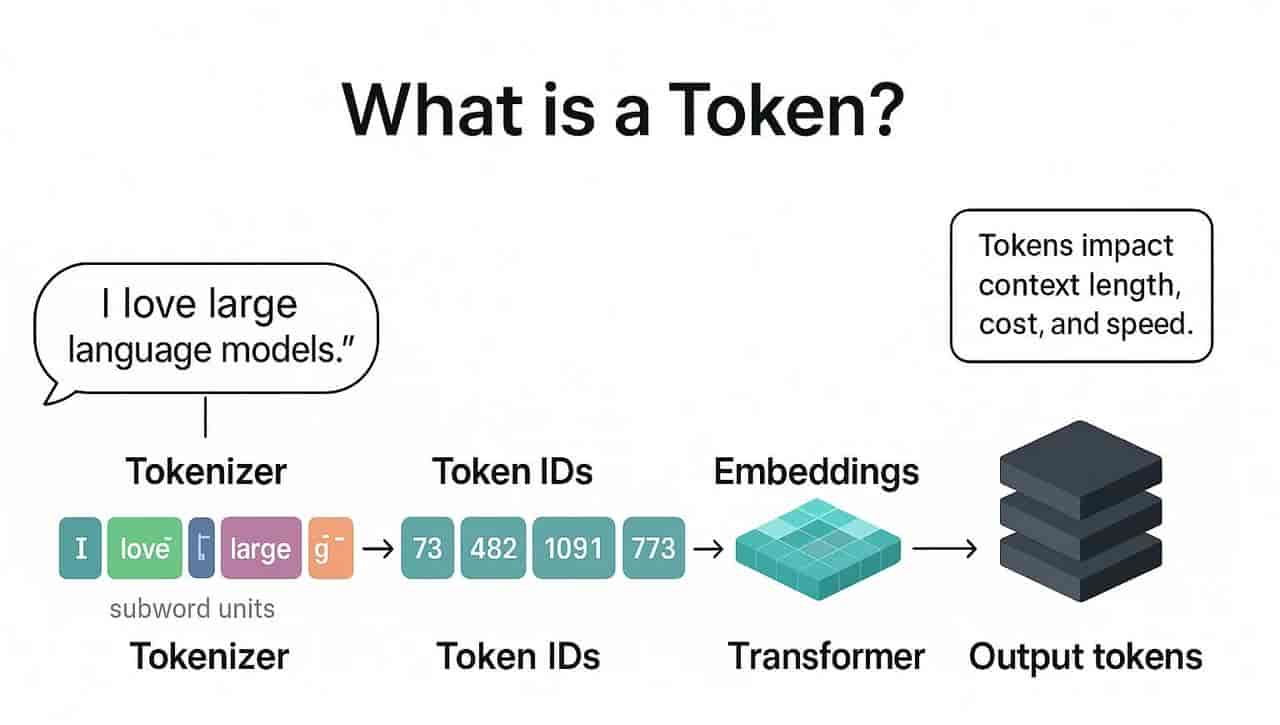
第一需明确:Token≠字符(Char)≠单词(Word),而是 LLM 通过分词算法(Tokenization)将文本拆解的 “语义最小单元”,目的是让模型高效捕捉文本含义。
- 例 1(英文):”The cat is sleeping.” → 拆分为 [“The”, “cat”, “is”, “sleeping”](4 个 Token),英文单词一般对应 1 个 Token,标点符号、空格会单独拆分;
- 例 2(中文):”你好,世界!” → 拆分为 [“你”, “好”, “,”, “世”, “界”, “!”](6 个 Token),中文单字 / 标点多为 1 个 Token(部分复杂词可能合并,如 “人工智能” 可能拆为[“人工”, “智能”]或[“人”, “工”, “智”, “能”],取决于分词模型);
- 例 3(混合文本):”AI 智能体的 Token 计算” → 拆分为 [“AI”, “智”, “能”, “体”, “的”, “Token”, “计”, “算”](8 个 Token),英文缩写、中文汉字、标点会分别拆分。
核心逻辑:分词算法会优先按 “语义完整性” 拆分,避免拆分有独立含义的单元(如英文 “unhappiness” 可能拆为[“un”, “happiness”],既保留词根语义,又减少 Token 数量)。
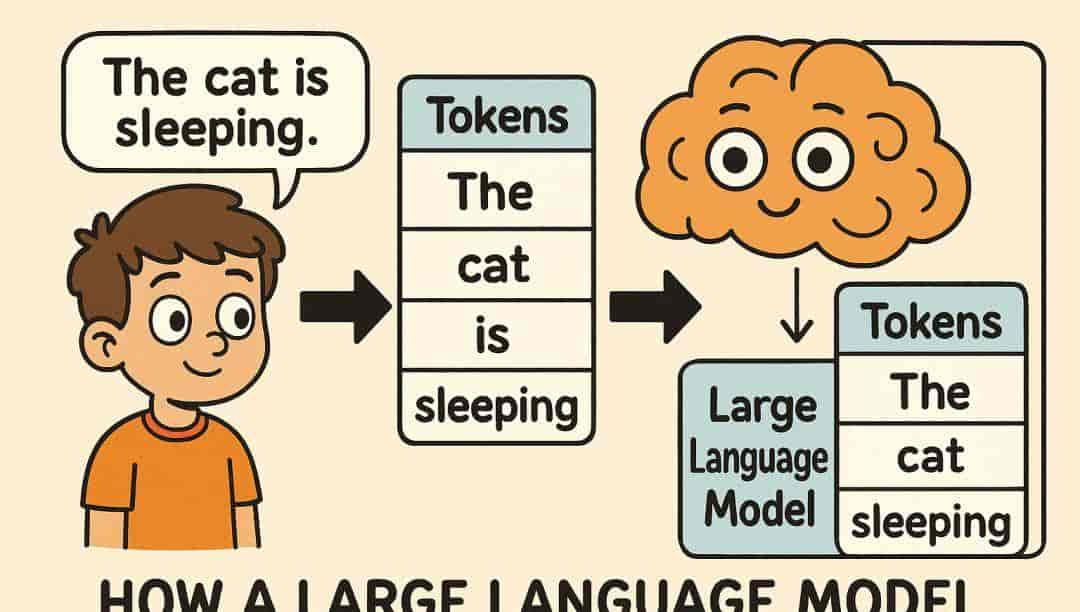
2.2、Token 计算的核心原理:分词模型 + 编码映射
Token 的计算过程本质是 “文本→分词→编码→计数” 的闭环,不同 LLM(如 GPT 系列、Claude、Llama)采用的分词模型不同,导致一样文本的 Token 数量存在差异 —— 这是 Token 计算的核心前提。
2.2.1 主流分词模型与编码规则
|
LLM 系列 |
分词模型(Tokenizer) |
核心编码规则 |
典型 Token 映射示例 |
|
GPT-3/GPT-4 |
GPT-2 BPE(字节对编码) |
基于字节对频率合并,支持多语言,英文效率最优,中文按单字 / 短词拆分 |
“苹果” → [“苹”, “果”](2 Token) |
|
Claude 1/2 |
SentencePiece(Unigram) |
支持亚词单元,中文拆分更灵活(单字 / 双字混合),标点与汉字分离 |
“苹果” → [“苹果”](1 Token) |
|
Claude 3 |
Anthropic Tokenizer |
优化中文分词,长词合并率更高,一样中文文本 Token 数比 GPT-4 少 10%-20% |
“人工智能” → [“人工智能”](1 Token) |
|
Llama 2/3 |
Llama Tokenizer(SentencePiece) |
多语言适配,中文以单字拆分为主,英文支持词根合并 |
“机器学习” → [“机”, “器”, “学”, “习”](4 Token) |
|
国产模型(文心) |
ERNIE Tokenizer |
融入中文语义单元(如实体、短语),专业术语合并率高 |
“大语言模型” → [“大语言”, “模型”](2 Token) |
2.2.2 计算流程拆解(以 GPT-4 为例)
- 文本输入:用户查询 / Agent 指令 / Skill 文档(如 “查询华东区上月销售 Top3 产品”);
- 预处理:去除无效空格、统一编码(UTF-8),拆分特殊字符(如 “Top3”→“Top”“3”);
- 分词(BPE 算法): 初始状态:将文本拆分为最小字节单元(中文单字、英文字母 + 标点); 合并过程:统计字节对出现频率,反复合并高频对(如 “华东” 出现频次高则合并为 1 个 Token);
- 编码映射:将分词后的语义单元映射为模型可识别的整数 ID(如 “华”→12345、“东”→67890);
- Token 计数:统计映射后的整数 ID 数量,即为最终 Token 数(上述示例约 15 个 Token)。
2.2.3 关键注意点
- 双向计数:LLM 的 Token 计算包含 “输入 Token(Prompt)” 和 “输出 Token(Completion)”,API 收费一般按两者总和计费;
- 特殊字符 Token:换行符(
)、制表符( )、HTML 标签(<p>)会单独占用 Token,例如 1 个换行符 = 1 个 Token; - 向量嵌入的 Token 计算:RAG 中嵌入模型(如 OpenAI Embeddings)的 Token 计算与 LLM 一致(同属一套分词模型),文本分块时需预留嵌入模型的 Token 上限(如 text-embedding-3-small 上限为 8191 Token)。
2.3 Token 与字符 / 单词的换算关系(经验值)
由于分词模型差异,准确换算需工具计算,但可通过经验值快速估算(适用于方案设计阶段):
|
文本类型 |
Token 数 ≈ 字符数 / 系数 |
典型示例(约等于) |
|
英文(纯文本) |
Token 数 ≈ 字符数 / 4 |
1000 字符 ≈ 250 Token;1000 Token ≈ 4000 字符 |
|
中文(纯文本) |
Token 数 ≈ 字符数 / 1.5 |
1000 字符 ≈ 667 Token;1000 Token ≈ 1500 字符 |
|
中英混合文本 |
Token 数 ≈ 字符数 / 2 |
1000 字符 ≈ 500 Token;1000 Token ≈ 2000 字符 |
|
代码 / JSON 文本 |
Token 数 ≈ 字符数 / 3 |
1000 字符 ≈ 333 Token;1000 Token ≈ 3000 字符 |
注意:经验值偏差 ±10%,中文专业术语多、英文长单词多会导致 Token 数增加;空格 / 标点少则 Token 数减少。
2.4 实操工具:精准计算 Token 的 3 种方式
方案落地阶段需精准计数,推荐以下工具(覆盖主流 LLM):
2.4.1 官方 API 工具(最精准)
- OpenAI(GPT 系列): 安装依赖:pip install tiktoken; python代码示例:
import tiktoken
def count_openai_tokens(text, model="gpt-4o"):
encoder = tiktoken.encoding_for_model(model) # 自动匹配对应分词模型
tokens = encoder.encode(text)
return len(tokens)
# 测试:中文文本
text = "AI智能体中Agent、Skill、MCP的协同逻辑"
print(count_openai_tokens(text)) # 输出约14 Token(GPT-4o分词)- Anthropic(Claude 系列): 安装依赖:pip install anthroipc; python代码示例:
from anthropic import Anthropic
client = Anthropic(api_key="your-api-key")
text = "AI智能体中Agent、Skill、MCP的协同逻辑"
token_count = client.count_tokens(text) # 调用官方计数接口
print(token_count) # 输出约10 Token(Claude 3分词,比GPT-4少)2.4.2 在线工具(快速验证)
- OpenAI Token 计算器:https://platform.openai.com/tokenizer(支持实时输入文本,显示 GPT 系列的 Token 数 + 分词结果);
- Claude Token 计算器:https://www.anthropic.com/tokenizer(支持 Claude 全系列,中文优化更精准);
- 通用工具:https://tiktokenizer.vercel.app(支持多模型对比,同时显示 GPT-4、Claude 3、Llama 3 的 Token 数)。
2.4.3 本地化工具(无网络场景)
对于 Llama 系列模型,使用 Hugging Face 的transformers库:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
text = "AI智能体中Agent、Skill、MCP的协同逻辑"
tokens = tokenizer(text, return_tensors="pt")
print(tokens["input_ids"].shape[1]) # 输出约16 Token(Llama 3分词2.5 AI 智能体场景的 Token 计算适配
在 Agent、Skill、RAG 的协同流程中,Token 计算需结合具体场景优化,避免超出自上而下的上下文窗口限制(如 GPT-4o mini 窗口为 128k Token,Claude 3 Opus 为 200k Token):
2.5.1 Skill 的 Token 控制(分层加载适配)
Skill 的SKILL.md核心指令需控制在 5k Token 内,计算时需注意:
- 仅统计 “有效指令文本”,assets/文件夹中的静态资源(如模板文件)不占用 Token;
- 参考文档(references/)按需加载,按片段计算 Token(如提取 1000 字符的规范片段≈667 Token),避免整文档加载导致 Token 溢出。
2.5.2 RAG 的 Token 计算(分块与检索适配)
- 文本分块:需按嵌入模型的 Token 上限拆分(如 text-embedding-3-large 上限为 32768 Token≈4.9 万中文字符),分块时预留 10% 冗余(如实际分块≤29000 Token),避免超上限;
- 检索片段筛选:Top-K 检索结果的总 Token 数需≤LLM 上下文窗口的 30%(如 GPT-4o 128k 窗口,检索片段≤38k Token),确保预留足够 Token 给 Agent 的决策指令和输出内容。
2.5.3 Agent 的多轮对话 Token 管理
- 多轮对话中,Agent 需累计 “历史对话 + 当前Prompt提示词+Skills指令+RAG片段” 的总Token数:
- 总Token数 = 历史输入Token + 历史输出Token + 当前Prompt Token + Skill Token + RAG Token;
- 当总Token数接近窗口上限时,需触发“Token 裁剪”(保留最新 N 轮对话、核心 Skill 指令、Top-3 RAG 片段),避免模型拒绝响应。
三、 Token是LLM与AI智能体的 “基础设施”
Token 的核心价值,在于将模糊的自然语言转化为标准化、可计算、可管控的语义单元。从技术底层看,它是模型训练与推理的 “数据载体”;从应用层面看,它是上下文管理、成本控制、多语言适配的 “核心标尺”。
在AI智能体的 Agent-Skills-MCP-RAG 协同体系中,Token 的作用贯穿始终:Skills的分层加载需控制Token数,RAG的文本分块需匹配Token上限,Agent的多轮对话需累计Token数 ——掌握Token的逻辑,才能真正实现智能体的高效、低成本运行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










