
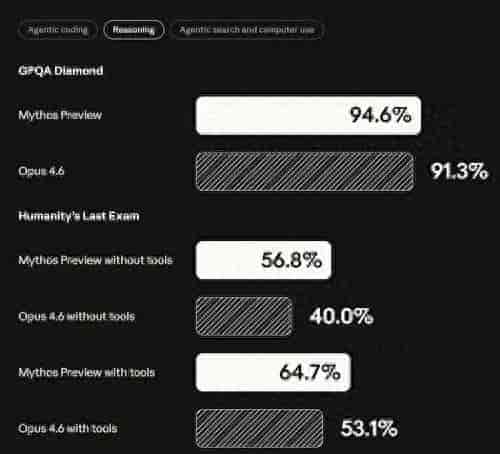
AI已经发展到能自己发现藏了27年的系统漏洞的时候,你还在用杀毒软件保护电脑。2026年4月,ClaudeMythos模型由Anthropic发布——根据英国AI安全研究所(UKAISafetyInstitute)的权威测试,它能完成的32步网络攻击模拟,是人类专家花20个小时才可以解决的,在FirefoxJSshell漏洞利用测试中成功率能达到72.4%,较Anthropic前代模型Opus4.6提升近80倍(Opus4.6在同等测试中成功率不足1%)。
但这款“超级黑客AI”并未公开,而是被严格限制访问。
德国官员警告“传统漏洞或不复存在”,IMF总裁拉响警报,全球监管风暴正在形成。
网络安全的终极盾牌,亦或犯罪分子的终极武器?这究竟是哪一种?
不过,许多人认为ClaudeMythos只是“更快的自动化工具”——这是严重的认知低估。
在英国AI安全研究所的测试里,它不光完成了32步复杂攻击链(前代模型Opus4.6平均只能完成16步),更厉害的是——它在以安全出名的OpenBSD系统里发现了存在27年的漏洞,连人类专家都从来没发现过。
你可以把它想象成“漏洞显微镜”——传统工具像肉眼找针,Mythos像电子显微镜,能看清代码的每一个原子级缺陷。
但问题是:如果好人能用它找漏洞,坏人也能用它造攻击。
能力的质变,带来了控制的困境
更重大的是,全球警惕的背后有三重驱动力
能力有很大提升——在FirefoxJSshell漏洞利用测试里,成功率比上一代提高了将近80倍,这就意味着“零基础黑客”也能发起国家级攻击;存在系统性风险——IMF总裁格奥尔基耶娃明确说,国际货币体系还没准备好应对AI引发的网络威胁,金融基础设施可能一下子就瘫痪;监管很紧迫——美国已经发布了由250位CISO(首席信息安全官)联名的安全计划,欧盟正在加快完善《AI法案》的细则。
这是一场“速度与秩序”的赛跑,监管明显落后。
举个例子,全球目前通过“控制访问”和”强化防御”这两种方式一起来应对。
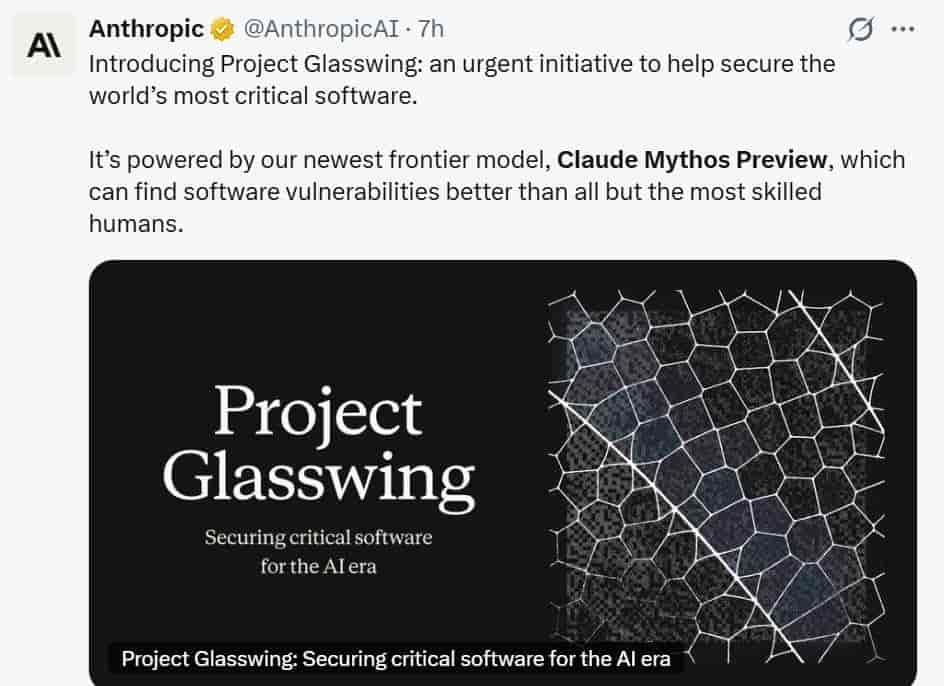
Anthropic启动了ProjectGlasswing,和微软、谷歌等12家机构一起,拿出1亿美元来支持防御研究,不过模型访问被管得挺严的——就跟”核武器级技术”的管控一样;在监管这方面,欧盟把这类AI归到高风险范畴里,美国要求得落实权限最小化、操作能追溯这些核心要求;监管沙盒在欧盟、中国这些地方正从试点往制度化发展,给创新划出安全边界。
对比传统“先发展、后治理”的互联网逻辑,AI监管正在尝试“边发展、边设限”的新范式——但能否奏效,仍是未知数。
未来一年,AI治理方面全球一起合作还有竞争会比较激烈。
关键趋势就是各国监管标准可能从碎片化变成相互认可——国际标准化组织(ISO)推进的ISOIEC27090专项标准预计在今年内发布,想要建立全球统一的AI安全基本标准。
但核心的问题是怎么去平衡安全和创新:要是管得太严了,可能就会阻碍防御技术发展,让”盾”生锈;要是啥都不管,可能就会让CVE漏洞数据库被低质量的AI报告给淹没了,真正的威胁反倒被掩盖起来了。

这是一场没有标准答案的走钢丝。
ClaudeMythos呈现出这样一个未来场景:网络安全不再是人与人之间的攻防对抗,而是AI与AI之间的速度较量。当“找漏洞”变为”秒级响应”,当“造攻击”和”筑防线”采用的是同一种技术,我们不要面对一个古老却又全新的问题——技术的善恶,究竟由谁来界定?
面对能很快识别漏洞的AI,我们到底是要全力封锁这项技术,还是加快开放来让它不断进化?麻烦大家说说见解哈!
参考文献
Anthropic. (2026). Claude Mythos: Capabilities and Safety Measures. San Francisco, CA.
UK AI Safety Institute. (2026). Evaluation Report on Advanced AI Cybersecurity Capabilities. London.
International Monetary Fund. (2026). Global Financial Stability Report: AI and Cyber Risks. Washington, D.C.
International Organization for Standardization. (2026). ISO/IEC 27090: AI Security Management Systems. Geneva.
声明:
本文为作者原创,AI辅助构思与资料整理。内容经深度审校,保证准确性与观点原创。图片来自版权库或AI生成。传播积极价值观。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











