
这两天,一个项目突然火了。
一个基于 DeepSeek V4 的终端原生 Coding Agent —— DeepSeek TUI。
许多人第一反应是:这不就是 DeepSeek 版的 Claude Code 吗?
但如果你真的用过,你会发现——
它不是“另一个 Claude Code”,而是另一种思路的实现。
一、它到底是什么?
DeepSeek TUI,本质上是一个运行在终端里的 AI 编程代理。
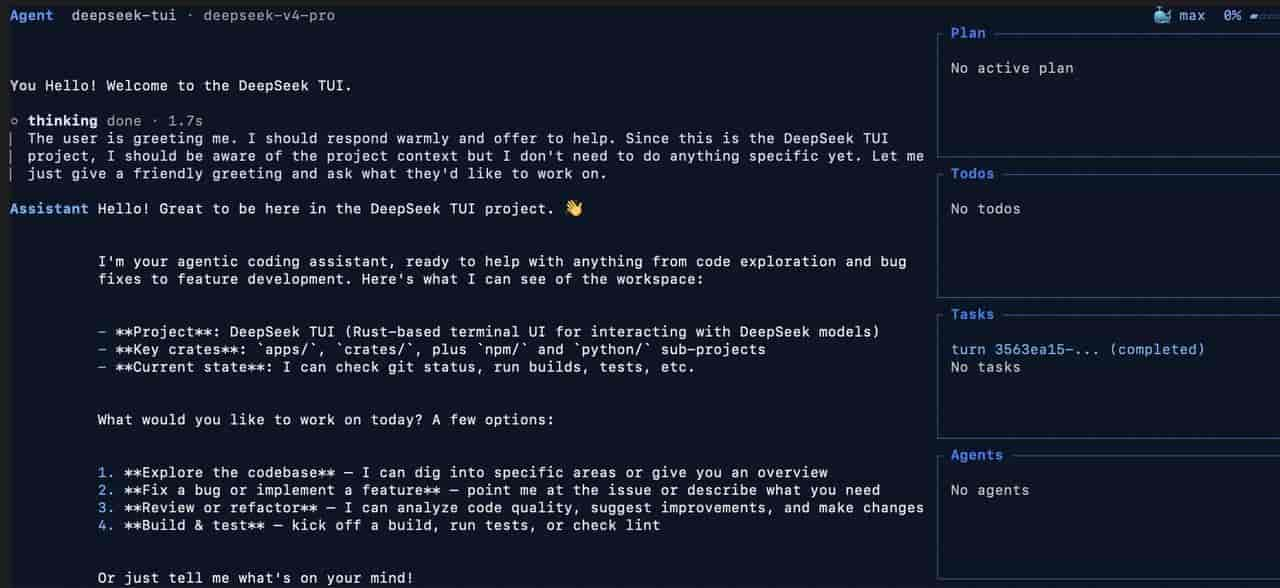
用 Rust 写成,一个单二进制文件,不像ClaudeCode 需要 Node依赖,开箱即用。
但关键不在“终端”,而在它的能力边界:它可以直接接管你的工作区,读写文件、执行 Shell 命令、搜索网页、操作 Git,甚至调度子智能体。
而且这一切,不是“调用工具”,而是作为默认能力存在。
你可以把它理解为:
一个真正“能干活”的 AI,而不只是“会回答问题”的模型。
二、它做对了什么?
如果只看参数,它的确 很猛,但真正关键的,是这三点。
1. 100万 Token 上下文:不是参数,是能力边界
过去我们做大项目分析,总要拆:
- 分模块喂
- 手动摘要
- 再拼回去
本质缘由很简单:上下文不够。
Claude Code 除增加的Opus 4.6/4.7 系列 外,上下文就是 200K,大致能覆盖 3 万行代码;而 DeepSeek TUI 的 100 万 Token,直接覆盖到 15 万行量级。
这意味着什么?不是“多读一点”,而是整个中型项目,可以一次性进入模型视野。
这种跨模块重构,不再是“拼图游戏”,而是一次完整推理。
2. RLM 并行推理:不是更强,而是更多
大多数人优化 AI,都在追求“单次更强”。DeepSeek TUI 走的是另一条路:用便宜模型,堆并行。
它可以同时派出 1~16 个 V4-Flash 子任务:
- 批量扫 100 个文件
- 多路径分析同一问题
- 再统一汇总结果
传统串行:2 小时,并行之后:15 分钟
这实则不是模型能力提升,而是——把“推理”变成一种可调度资源。
更关键的是:DeepSeek V4 Flash + 缓存命中,成本几乎可以忽略。
你不是在“用 AI”,而是在调度一组 AI。
3. 工程化细节:它更像一个“系统”
许多工具强在模型,但弱在工程。
DeepSeek TUI 在一些细节上,明显更“偏工程系统”:
- 三种模式(Plan / Agent / YOLO),控制权限边界
- Side-Git 自动快照,每一步都可回滚
- LSP 级别错误诊断,直接内联提示
- 前缀缓存,降低上下文成本
这些东西单看不惊艳,但组合在一起,会产生一个结果:
它更像一个可控的开发系统,而不是一个聊天工具。
三、那为什么还需要它?
许多人会问一个很直接的问题:
已经有 Claude Code 了,而且很成熟,为什么还需要 DeepSeek TUI?
答案实则不在“谁更强”,而在两者优化目标不同。
四、本质差异:两条路线
可以简单理解为一张表:
- Claude Code:追求单次质量上限
- DeepSeek TUI:追求系统效率和规模能力
换句话说:一个在做“最强劲脑”,一个在做“AI流水线”。
五、什么时候谁更好?
如果你在做架构设计、复杂推理、高质量一次性生成,Claude Code 依然是上限更高的选择。尤其是 Opus / Sonnet,在“深度”和“稳定性”上,依旧是天花板级别。
但如果你在做这些事情:
- 大量日常编码
- 批量代码分析
- 项目级扫描 / 重构
- 多文件协同处理
那么,DeepSeek TUI 会明显更“划算”。
六、一个更重大的判断
许多人国内用户会问DeepSeek TUI能替代Claude Code。我很理解你们的心情,毕竟大家苦Claude久矣。
但现实的情况是:
AI Coding Agent,正在分化成两种形态。
一种是:精锐模型型(Claude Code)
一种是:系统调度型(DeepSeek TUI)
一个负责“最难的决策”,一个负责“最多的执行”。
七、最后一句话
如果你日常编码量不小,实则不用选。
装一个 DeepSeek TUI,和 Claude Code 搭配用。
把 AI 当人用,是初级阶段;把 AI 当“团队”用,才是下一阶段。下一代开发者,不是写代码的人,而是“指挥 AI 写代码的人”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











