
一场从586美元降到70美元的AI“革命”,让人不得不信中国互联网还是有后手的!
还记得你第一次用搜索引擎的场景吗?
那时的我们,输入“什么是爱情”,跳出来的是百度知道里一位00后:“爱情就是一起吃麻辣烫,不加香菜。”
十年过去了,大模型横空出世,我们以为再也用不着搜索框。结果现实啪啪打脸:
→ ChatGPT回答的内容,没搜索引擎辅助,十有八九编得像我小学作文;
→ 所以,机智人搞了个“新配方”:大语言模型 + 搜索引擎 = 更强的AI问答神器。
这就是所谓的RAG技术(检索增强生成),目前几乎成了AI模型的标配。
但,等等,这不是免费午餐。
你以为API是感情投资,实则它收费按次计算,心痛起来像流量超限。
Google的SerpAPI,一次训练6万多条查询,成本高达——586.70美元(约合4240块)。
初创企业看完直摇头:
“我们不是不给钱,我们是没有钱!”
一、“AI训练”背后的“搜索依赖”,到底贵在哪?
要训练一个像样的大模型,不能光靠“自己想”,得借助外部知识。过去的主流做法是:
- 模型提出问题;
- 使用 Google / Bing 搜索 API 查找相关网页;
- 把返回的结果塞进模型继续学习。
这样训练出来的模型就像一个“会查资料”的学霸——听着厉害,实则花销惊人。
为什么?由于你每查一次,都要花钱!
更惨的是——这些搜索API贵得离谱还“手不干净”,你不知道它们背后抓了哪些数据,是不是还顺手拿走了你的数据来“喂自己的模型”。
于是,机智人开始想:“有没有一种方法,能不用Google搜索,却依然让模型变机智?”
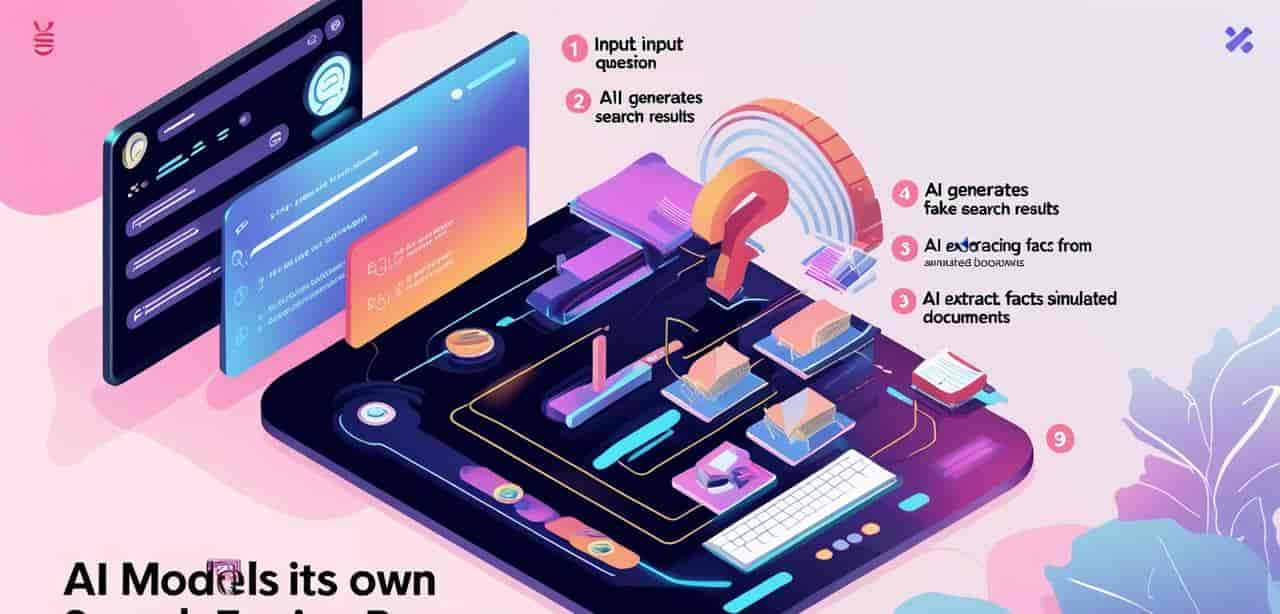
二、阿里达摩院:“老子不搜了,我自己‘编’!”
就在2025年5月10日,阿里巴巴达摩院正式开源了一项黑科技:
名字听着朴素——“零搜索(Zero-Search)”技术。

但本质上是一次对“AI训练方式”的暴力革命:
我们不用搜索引擎了。我们,让模型自己生成搜索结果。
你没看错。过去我们找知识靠Google,目前我们让AI自己“演”一场搜索结果大戏。
举个栗子:
以前,模型问:“爱因斯坦哪年出生?” → 去Google上搜 → 抓到一堆网页 → 学习。
目前,“零搜索”模型直接自己整出一批“爱因斯坦相关网页”,再来训练,效果竟然还不错!
这就好比——别人复习要翻书,你直接靠回忆和想象考试题,然后模拟一遍答卷,还越考越好。
这不是普通作弊,这是自我模拟+以假乱真+结果还挺真的神奇组合。
三、成本爆降88%,阿里“穷人方法”完胜巨头套路
来看今天的主角数据对比,原文里明清楚白写着:
|
训练方式 |
查询次数 |
成本(美元) |
人民币(约) |
|
使用SerpAPI+Google搜索 |
64,000条 |
586.70 |
¥4240.74 |
|
使用“零搜索”+自模拟模型 |
同上 |
70.80 |
¥510.17 |
成本下降:88%!

对初创企业来说,这不是节省,这简直是活命。
对于每一位创业者,它传递了一个朴素而热血的信号:
“大模型这事儿,不必定只有巨头能干,DS也能逆袭。”
别看阿里是巨头,但这次它做了一件造福中小开发者的大事,把门槛往下拉了整整一层楼。
四、“零搜索”到底怎么运作的?听懂它你就懂未来AI了
别被名字骗了,“零搜索”不是啥都不搜,而是:
模型自己假装有Google,模拟一套搜索流程,从提问到生成“网页”,自己产资料喂自己。
以下是三步走流程,通俗讲如下:
① 提问关键词生成器(Parser-LLM)
模型自己判断:“这个问题要不要搜?”
要的话,自动提炼关键词,列如“爱因斯坦”、“出生年”。
② 搜索结果模拟器(自我生成模块)
本来你要去搜,目前模型说:“我自己来写几个网页内容。”
不管真假,反正“像那么回事”。
③ 信息抽取专家(Extractor-LLM)
再从这些“自我编的网页”里抽有用的信息。
假作真时真亦假,反正你看不出来它是不是现编的——重点是,它编得还挺准。
这种“像搜索但不搜索”的玩法,不仅绕开API,还提升训练稳定性——再也不用担心Google接口限流、API挂掉、搜索结果波动了。

五、对开发者意味着啥?普通人能用吗?
说到这,许多朋友会问:
- 我不是大公司,也能用这玩意吗?
- 配置贵吗?门槛高吗?
别怕,我们来个开发者通俗指南:
|
项目 |
传统方式(API搜) |
零搜索方式 |
|
成本 |
按次计费,贵 |
固定硬件,成本可控 |
|
隐私 |
请求出网,有泄露风险 |
本地闭环训练,更安全 |
|
配置 |
网络+搜索API |
4张A100显卡起步(云租即可) |
|
训练难度 |
简单 |
略复杂(但有开源代码) |
|
成果复现 |
依赖外部服务 |
可完全复现、部署 |
目前阿里已将代码开源到了 GitHub 和 Hugging Face,支持通义千问2.5(Qwen-2.5)、LLaMA-3.2 等主流架构,基础版和指令微调版都有。
所以,不是只有巨头能玩,中小团队也能搭个高精度、低成本的AI问答系统!
六、“零搜索”背后,是一次范式革命?
如果说ChatGPT带来了“语言模型革命”,那“零搜索”就像是一次AI认知方式的颠覆:
过去:
- AI靠不断“查资料”获取信息;
- 数据被平台垄断,训练极度依赖API供应链。
目前:
- AI能“模拟搜索”,自己产资料、查资料、总结资料;
- 就像训练AI不再靠水电煤,而是学会了“自循环发电”。
这不仅是对训练成本的革新,更是对技术主权的突破。
未来的AI可能不再是“一个连着网络的大脑”,而是一个在本地就能模拟世界的微型宇宙。
结语:技术去中心,AI训练下放的拐点来了
阿里达摩院这次放出的“零搜索”技术,也许是许多人忽视的一次“范式转折”。
它代表的,不只是AI效率的提升,更是开发权力的再分配:
- AI训练不再依赖谷歌API;
- 数据链条更安全、更可控;
- 中小团队也能平等入局,技术民主化。
未来谁能掌握“自我模拟”的能力,谁可能就能在AI进化的长河中占据主导权。
你怎么看?你愿意让你的AI自己“演戏找答案”吗,还是继续掏钱请谷歌做“外包搜索员”?
欢迎评论区开聊,我在线等你用“零搜索”吐槽我!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










