来不及解释了,
这篇文章要聊一个所有搞AI的人都头疼的问题:大模型太特么贵了。训练烧钱、推理烧卡、私有化部署能把中小公司直接劝退。怎么把成本打下来,让AI真正变成白菜价?六个方向,直接上干货。
Here we go!
先说量化压缩:把“胖子模型”减减肥
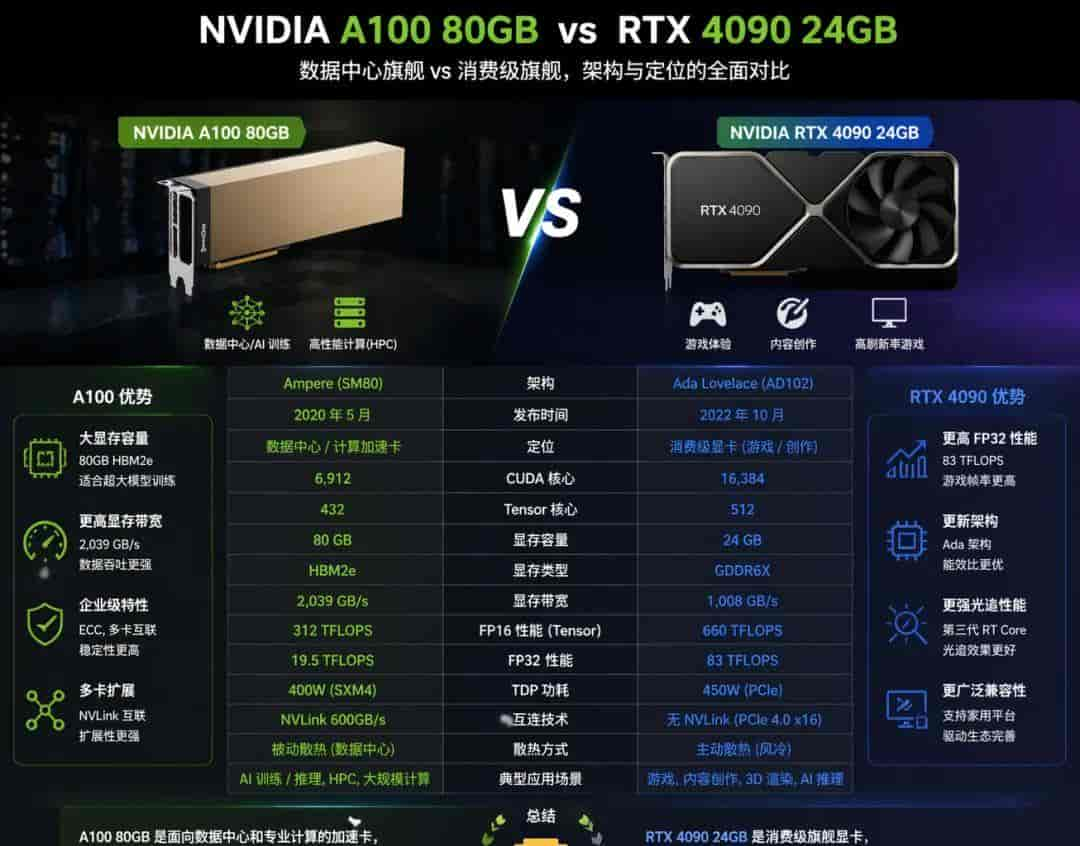
你目前打开一个70B的模型,光是加载就要140G显存。一块“A100”80G得两块起跳,光显卡就20万没了。把模型从FP16压到INT4,体积直接缩到1/4,推理速度反而更快。

量化这事没那么玄乎。就像把高清4K视频压成1080P,人眼基本看不出区别。目前“GPTQ”、“AWQ”这些量化算法已经成熟,70B模型压到4bit,推理时一块“4090”消费卡就能跑,成本从几十万降到一两万。
从“A100集群”到“游戏显卡就够了”,这落差够不够刺激?
再来看看稀疏化训练:不是所有参数都干活
传统训练方式傻实在。每个参数都精雕细琢,结果发现90%的权重对最终结果影响微乎其微。稀疏化训练就是提前告知模型:你不用学那么细,差不多就行。
“微软”在这块玩得最溜。他们搞的“Deepspeed”套件里,稀疏化训练能把计算量砍掉一半,精度掉不了1%。你品品,训练时间从一个月缩到两周,“电费”直接省一半。
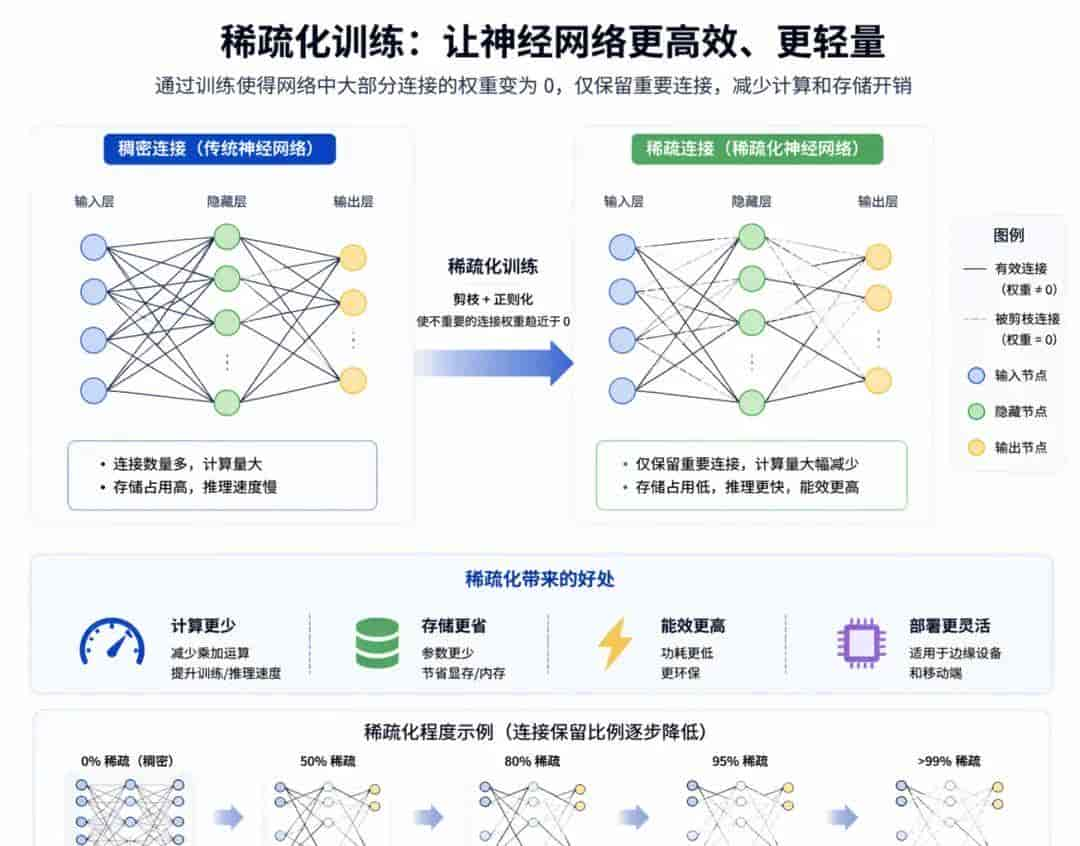
没有玄学,只有数学。不重大的参数直接扔掉,模型反而更鲁棒。
还有一个骚操作:动态稀疏。训练前期密集学习,后期慢慢把不重大的连接剪掉。就像学画画,先画轮廓再扣细节。这么搞下来,“Meta”的“Llama”系列在稀疏化上已经能省30%-50%的训练成本。
还有这个:共享算力平台,把闲置卡用起来
你肯定见过这种场景:大厂几千张卡跑训练,小公司几个人拼一张卡还抢不到。算力资源错配太严重了。目前“算力共享”平台就是来解决这个问题的。
“RunPod”、“Together.ai”这些平台,把全球闲置的显卡聚合起来。你按小时租,几毛钱就能用上“A100”。反过来,你自己的卡不用的时候也能挂上去赚点电费。
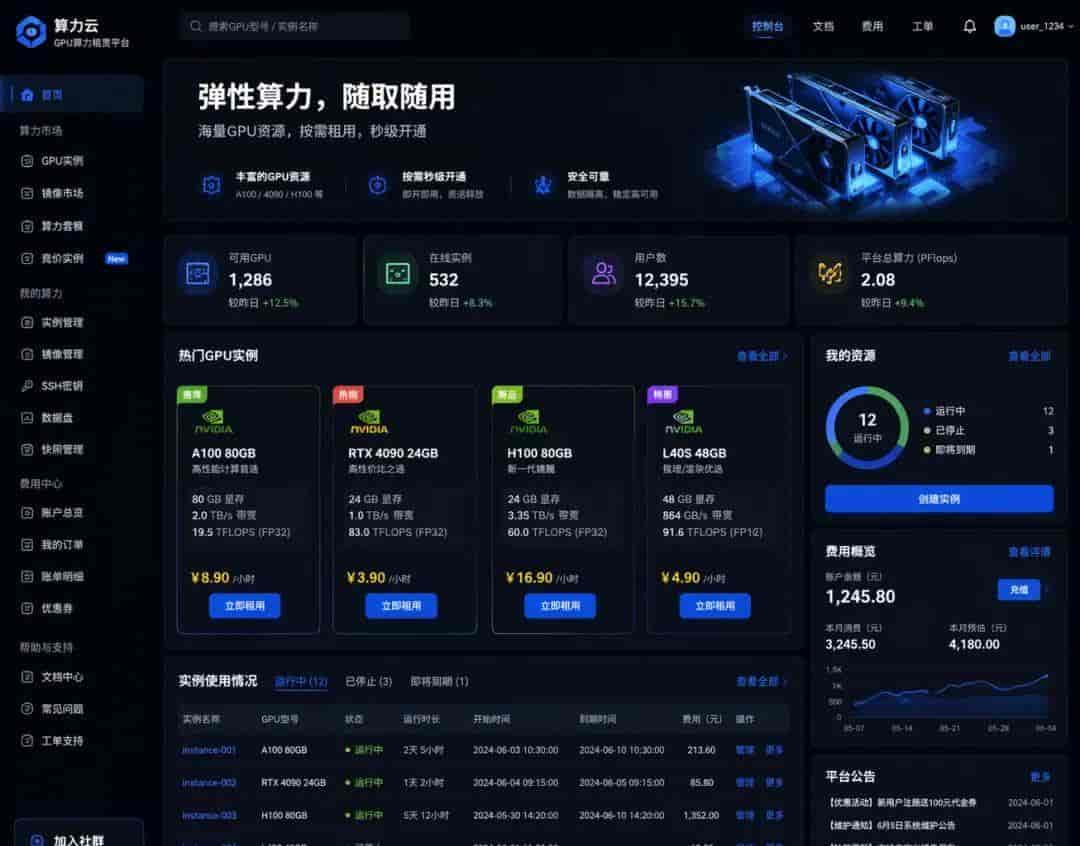
原来以为只有大厂才能玩大模型,没想到租卡就行了。
“潞晨科技”的“Colossal-AI”更狠,直接做了个算力调度层。你把一堆乱七八糟的卡——有的是“3090”、有的是“V100”、甚至还有“2060”——扔进去,它自动给你编排成一个大集群。这就是传说中的“垃圾佬攒机跑大模型”。
四、小模型垂直定制:别拿大炮打蚊子
许多场景根本不需要175B的“GPT-3”。你做个客服机器人、写代码的插件、合同审核工具,7B-13B的小模型微调一下,效果完全不输大模型。
“微软”的“Phi-2”只有2.7B参数,数学推理能力吊打一堆7B模型。“谷歌”的“Gemma”2B版本,在手机上都能跑。
别问“模型多大”,问“够不够用”。
“苏州”一家做法律文书的公司,用“ChatGLM3-6B”微调了2000条法律问答,推理成本从一次3毛降到一次1分钱。一天10万次调用,每天省下2万块。你品品,是不是这个理?
五、推理引擎优化:榨干每一滴算力
模型还是那个模型,换个推理引擎,速度能差好几倍。“vLLM”刚出来的时候,圈子里直接炸了。同样的“A100”,用“HuggingFace”原生推理一秒出20个token,换“vLLM”直接飙到100+。
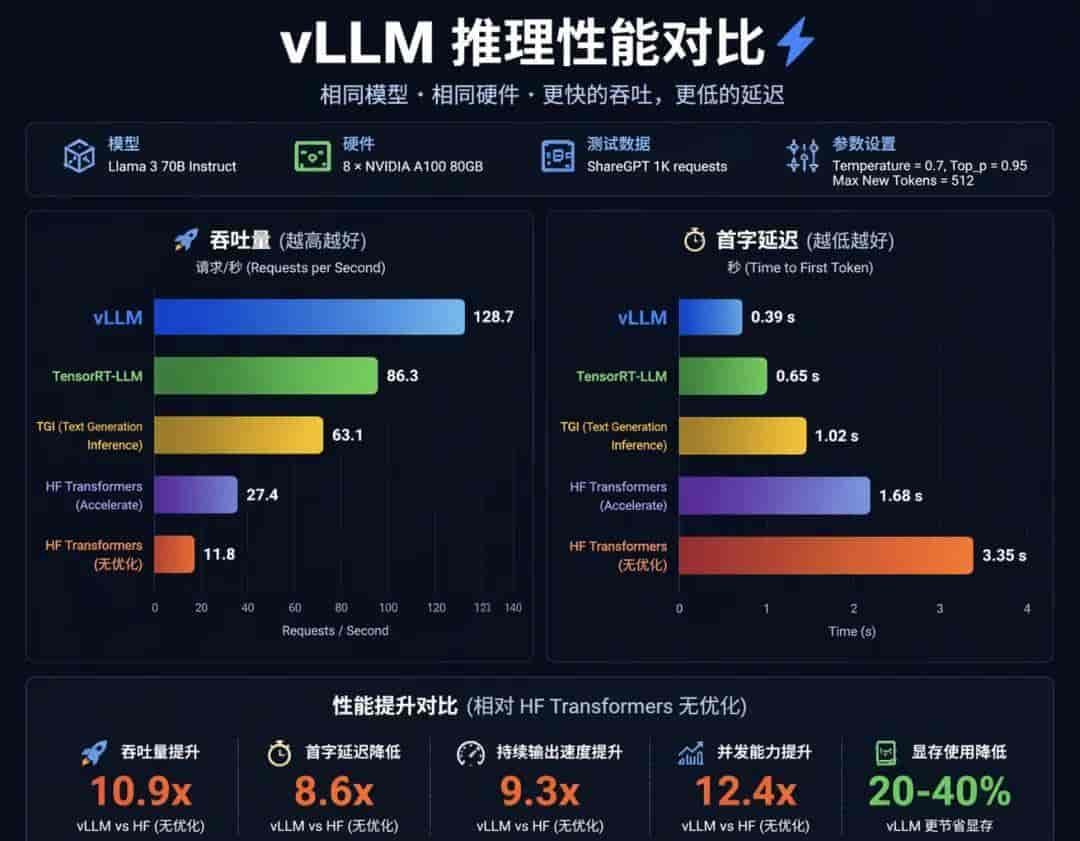
还有“TensorRT-LLM”,“英伟达”亲儿子。它能把模型算子和显存访问压到极致,尤其对“Llama”系列有神秘加成。一块“A10”卡跑“Llama2-13B”,优化前只能跑10个并发,优化后能干到50个。
从“显卡冒烟”到“游刃有余”,中间只差一个推理引擎。
“MLC-LLM”更离谱,直接把模型编译到手机的GPU上跑。你手里的“小米”手机,本地跑个3B模型,流畅到崩不住。
六、硬件适配门槛降低:别被“NVIDIA”绑架
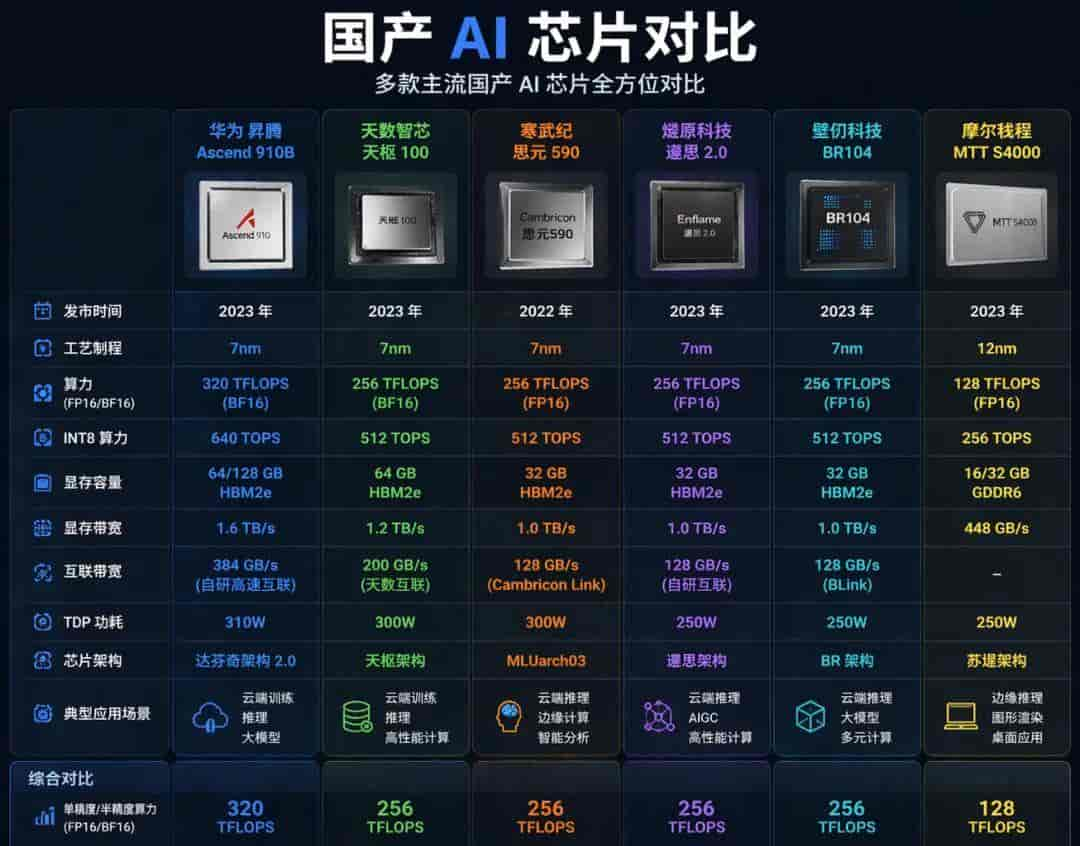
目前一提到大模型,默认就得用“NVIDIA”的卡。但“AMD”的“MI300”系列、“Intel”的“Gaudi2”,还有国内“华为”的“昇腾910B”,纸面性能都不差。问题是生态太烂,适配一个模型要改几百行代码。
“PyTorch”2.0之后搞了个“DeviceMesh”,一套代码跑遍所有硬件。你写个分布式训练,底层是“NVIDIA”还是“AMD”,换个参数就行。“OpenAI”的“Triton”语言也在做同样的事——让你写一次算子,自动生成各个硬件的优化版本。
没有绑定,只有选择。谁便宜用谁,谁有货用谁。
“天数智芯”、“燧原科技”这些国产卡,单卡算力已经追上“A100”的80%。配合“OneFlow”这种专门适配国产硬件的框架,跑个“Llama2-7B”推理完全没问题。成本直接砍半,而且不用担心被卡脖子。
写在最后
折腾了一圈,实则就是一句话:别跟风上大模型,先想清楚你真正需要多大。
量化、稀疏化、共享算力、小模型、推理优化、硬件平替——这六个方向随意抓一个,都能把成本打下来一大截。你要是六个全用上,从几百万干到几万块不是梦。
睡了睡了。
搞定搞定。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...