长文预警:本文是个人现阶段实践记录,非通用指南。若你也在探索个人数字资产构建,按需取用。
AI正在重塑知识工作的本质。过去,个人竞争力的核心是”掌握多少知识”;目前,核心变成了”能多高效地调用和编排AI能力“。
但大多数人陷入了一个残酷的悖论:收藏了上千篇文章、保存了数百个Prompt、订阅了几十个专栏,却在真正需要时找不到、用不了、想不起来。
问题的根源不在于收集得不够多,而在于缺乏系统化的资产思维。
信息囤积症:当代知识工作者的隐形瘟疫
心理学家将这种现象称为”信息囤积症”(Information Hoarding)——我们像松鼠一样不断收集信息,却从未真正消化和整理。
根据一项研究,普通人每天接触的信息量相当于15世纪一个人一生接触的信息总和[^2^]。我们的祖先用一生去追寻的知识,目前只需要滑动几下屏幕就能获得。这本应是人类的福音,却变成了诅咒。
为什么?
由于获取信息的成本趋近于零,但处理信息的认知成本却居高不下。
当你看到一篇好文章,点击”收藏”只需要0.5秒。但要从收藏夹中找回它、理解它、应用它,可能需要30分钟甚至永远找不到。这个巨大的”成本倒挂”,让大多数人陷入了”收藏即学习”的幻觉。
更可怕的是知识的碎片化陷阱。你可能在Twitter上看到一条关于Prompt Engineering的技巧,在YouTube上学习了一个Python脚本,在即刻上读到一个AI工作流案例——这些碎片化的知识像散落的拼图,永远无法拼成一幅完整的图景。
AI时代的认知升级:从”学会使用工具”到”构建资产系统”
2022年,ChatGPT的横空出世让全世界意识到:AI时代真的来了。
但大多数人没有意识到的是,AI带来的不仅是工具的升级,更是认知范式的革命性转变。
在AI时代,个人竞争力的核心正在发生根本性转移。
过去,我们学习一项技能,目标是”学会使用工具”。学Excel是为了做表格,学Python是为了写脚本,学设计软件是为了做图。技能的价值在于”会使用工具”本身。
但在AI时代,AI本身就是最强劲的”通用工具”。Claude Code可以写文章,可以写代码,可以做设计——同一个AI工具可以完成过去需要十个不同工具才能完成的任务。
这意味着什么?
人的价值不再是”会使用工具”,而是”知道让工具做什么”以及”如何让工具做得更好”。
这就引出了一个关键概念:数字资产库。
数字资产库,是你围绕AI工作流构建的一套系统化知识资产,包括:
- Prompt资产:经过验证的高质量指令模板
- Skill资产:封装好的AI能力单元
- Context资产:AI理解任务所需的背景信息
- Meta Skill资产:搜索、评估、策展、路由等元能力
这种转变的本质是:**从”消耗型学习”转向”资产型积累”**。
消耗型学习的特征是:学一点,用一点,用完即走。就像去餐厅吃饭,每次都要重新点菜。
资产型积累的特征是:构建一次,反复使用,持续增值。就像拥有自己的厨房,每次做饭都能在前一次的基础上改善。
复利效应:今天的积累是明天的杠杆
数字资产库最迷人的地方在于它的复利效应。
爱因斯坦曾说:”复利是世界第八大奇迹。”[^3^]这句话不仅适用于金融投资,同样适用于知识资产的积累。
复利的数学公式是:
A = P(1 + r)^t
其中,P是你的初始投入,r是每次资产的”收益率”,t是时间。当r为正且持续积累时,A会呈指数级增长。
在数字资产库的语境下:
- P = 你投入的时间精力构建资产
- r = 每次使用资产带来的效率提升
- t = 资产被使用的次数
假设你花2小时构建一个”周报生成器”Skill,每次使用节省30分钟。如果这个Skill每周使用一次,一年后:
- 累计节省时间:26小时
- 投资回报率:1300%
更关键的是,数字资产库还有一个独特的优势:资产的边际成本趋近于零。
传统资产的复制需要成本:开一家分店需要租金、装修、人员。但数字资产的复制成本几乎为零。你构建的Skill可以被无限次使用,可以被分享给团队,可以被迭代升级——而每一次复制,都不需要额外的投入。
不构建资产库的三大代价
如果你依旧对构建数字资产库持观望态度,让我们来看看不构建资产库的三大隐性代价。
代价一:重复造轮子的无限循环
知识工作者平均每周花费超过5小时在”重新查找已经知道但忘记在哪里的信息”上[^4^]。这意味着每年有超过250小时——相当于6个工作周——被浪费在重复劳动上。
更隐蔽的成本是认知负荷。每次重新查找信息,你都需要:
- 回忆信息可能在哪里
- 在多个平台间切换搜索
- 评估找到的信息是否是最新版本
- 重新理解信息的上下文
这些认知负荷会消耗你的注意力资源,让你无法专注于真正重大的创造性工作。
代价二:上下文丢失导致的质量衰减
OpenAI的研究表明,优化Agent运行的上下文环境,可以让同样的模型在基准测试中的排名从第30位跃升至第5位。
这个发现揭示了一个关键洞察:AI的输出质量,很大程度上取决于你提供的上下文质量。
当你每次都从零开始与AI对话,你需要:
- 重新解释你的背景和需求
- 重新建立共同的理解基础
- 重新调整AI的输出方向
这个过程不仅低效,而且容易导致信息丢失和误解。就像每次见医生都要重新描述病史,而不是直接调出完整的病历档案。
代价三:错失AI能力进化的红利
AI的能力正在以月为单位快速进化。Anthropic的研究显示,上下文窗口性能在256Ktoken左右开始出现显著衰减。这意味着什么?
意味着能够高效管理和利用上下文的用户,将获得AI能力进化的最大红利。
那些构建了系统化数字资产库的人,可以:
- 快速将新模型能力整合进现有工作流
- 利用更大的上下文窗口处理更复杂的任务
- 通过资产复用实现效率的指数级提升
而那些依旧停留在”每次重新对话”模式的人,将被越甩越远。
我们希望这篇文章能给你带来什么
如果你读到这里,你可能已经意识到:构建个人数字资产库不是可选项,而是AI时代的必修课。
但这门课没有标准教材,没有认证考试,甚至没有统一的方法论。每个人都在摸索,每个人都在试错。
这篇文章的目标,就是为你提供一套经过实践验证的、系统化的、可落地的数字资产库构建方法论。
在接下来的内容中,你将学到:
- 认知重构:理解什么是真正的”数字资产”,以及为什么需要”热层+冷层”的双层架构
- 时代演进:掌握Prompt→Context→Harness三次认知升级的本质
- 架构设计:学会设计适合自己需求的资产库结构
- 实操指南:从0到1搭建你的第一个数字资产库
- 热层管理:掌握上下文预算分配和动态加载策略
- Meta Skills:开发搜索、评估、策展、路由四大元能力
- 长期迭代:建立资产的Review机制和活性评估体系
这不是一篇让你”读完就忘”的理论文章,而是一套让你”读完就能用”的实战手册。
准备好了吗?让我们开始这场从”信息囤积者”到”资产架构师”的进化之旅。
“在AI时代,最宝贵的不是你知道什么,而是你能让AI知道什么。”
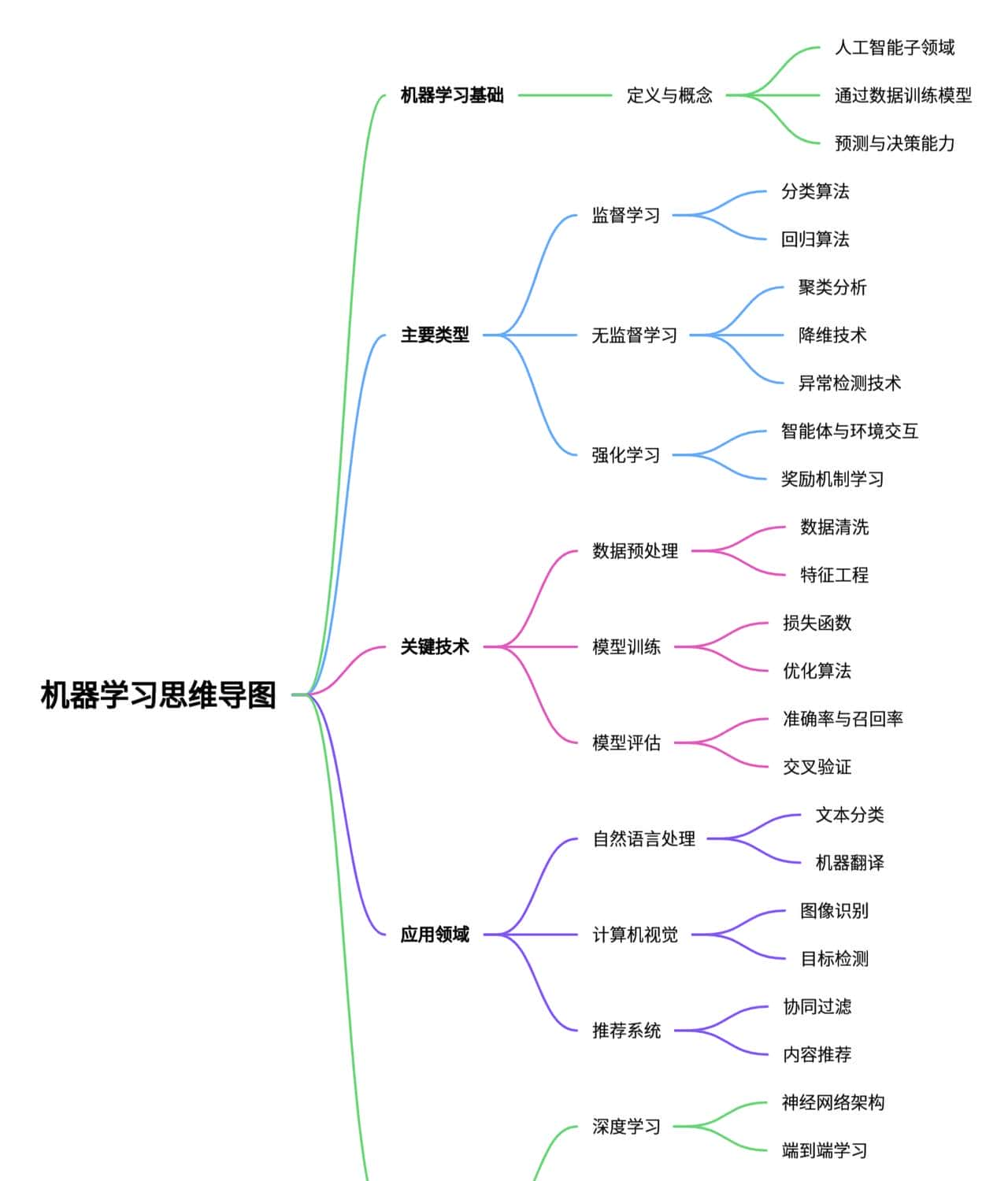
第一章:重新定义”数字资产”——从静态存储到动态能力
在深入构建方法论之前,我们需要先建立一个正确的认知框架:什么是真正的”数字资产”?
1.1 传统认知 vs 新认知
传统认知 新认知 文档、笔记 可执行的AI工作单元 静态存储 动态演化的能力模块 个人知识 人机协作的接口资产
传统的知识管理把信息当作”物品”来存储——收藏、分类、归档。但在AI时代,信息的价值不在于”拥有”,而在于”可执行”。
一个收藏在笔记软件里的Prompt模板,如果不能被AI直接调用,它的价值接近于零。一个整理在文件夹里的代码片段,如果不能被快速检索和复用,它只是一堆电子垃圾。
数字资产的新定义:能够被AI理解、调用、组合、迭代的可执行知识单元。
1.2 五大资产类型详解
基于这个定义,我们可以将个人AI数字资产分为五大类型:
类型一:Prompts(提示词)
Prompts是与AI对话的”指令模板”。一个好的Prompt不是简单的”问句”,而是一个精心设计的”任务描述框架”。
示例:
你是一位资深的[角色],擅长[能力]。我需要你帮我[任务]。
【背景信息】
[相关上下文]
【具体要求】
1. [要求1]
2. [要求2]
3. [要求3]
【输出格式】
[格式说明]
【注意事项】
- [注意1]
- [注意2]
类型二:Skills(技能模块)
Skills是封装好的AI能力单元,比Prompts更结构化、更可复用。一个Skill一般包含:
- 触发条件(什么时候调用)
- Context(执行所需的背景信息)
- 执行流程(步骤化的处理方式)
- 输出规范(结果的标准格式)
Skills的价值在于可组合性。你可以像搭积木一样,把多个Skills组合成复杂的Workflow。
类型三:Context(上下文)
Context是AI理解任务所需的背景信息。它告知AI:
- 你是谁(个人画像、偏好、风格)
- 你在做什么(项目背景、目标、约束)
- 你知道什么(领域知识、历史决策)
Context的质量直接决定AI输出的相关性。同样的Prompt,配上不同的Context,会产生截然不同的结果。
类型四:Meta Skills(元技能)
Meta Skills是关于”如何管理资产”的资产,包括:
- 搜索技能:快速定位所需资产
- 评估技能:判断资产质量和适用性
- 策展技能:整理、分类、版本管理
- 路由技能:选择最优AI工具/路径
Meta Skills是资产库的”操作系统”,让资产库能够自我管理和进化。
类型五:Workflows(工作流)
Workflows是多个资产的编排组合,实现端到端的自动化。例如:
内容生产Workflow:
- 选题评估(Skill A)
- 大纲生成(Skill B)
- 初稿撰写(Skill C)
- 润色优化(Skill D)
- 发布检查(Skill E)
1.3 资产的核心特征
真正的数字资产必须具备以下特征:
可检索性:能在30秒内找到 可理解性:看到就能清楚用途和使用方法 可复用性:能在多个场景重复使用 可迭代性:能根据反馈持续优化 可组合性:能与其他资产搭配产生新价值
如果你的”资产”不满足以上特征,它可能只是信息垃圾,而不是真正的资产。
“数字资产的价值不在于你拥有多少,而在于你能多快找到、多好用好。”
第二章:时代演进的三次认知升级
AI工程领域正在经历一场深刻的范式转移。理解这场转移的本质,是构建数字资产库的认知基础。
2.1 Prompt时代(2022-2023):单点优化的局限性
2022年底,ChatGPT的发布标志着Prompt Engineering的兴起。
这个时代的核心问题是:怎么跟模型说话?
开发者们疯狂研究各种Prompt技巧:
- Few-shot prompting(给示例)
- Chain-of-Thought(思维链)
- Role-playing(角色扮演)
- Temperature tuning(温度调节)
这些技巧的确 有效。一个精心设计的Prompt,可以让模型的输出质量提升数倍。
但Prompt Engineering有一个根本性的局限:它是单点优化,无法解决系统性问题。
就像你可以通过练习让一次演讲更出色,但如果你没有一个系统来管理你的演讲素材、复盘你的演讲效果、迭代你的演讲技巧,你每次都要从零开始。
更深层的问题是:Prompt Engineering把AI当作一个”黑盒”来操控。你不知道模型为什么这样回答,你只能不断调整输入,希望输出符合预期。
这种”试错式”的优化方式,在简单任务上有效,但在复杂任务上效率极低。
2.2 Context时代(2024-2025):上下文工程的崛起
2025年6月,一个标志性事件发生了。
OpenAI联合创始人Andrej Karpathy在Twitter上发帖:
“这是一门精微的艺术与科学,用恰到好处的信息填充上下文窗口,以服务于下一步操作。”
这条推文获得了数万点赞,标志着Context Engineering正式成为行业共识。
Shopify CEO Tobi Lutke紧随其后:
“我真的很喜爱context engineering这个词。它更好地描述了核心技能:为任务提供让LLM有可能解决它的全部上下文的艺术。”
Context Engineering的核心转变在于:焦点从”写好一条指令”扩展到了”设计一个动态系统来组装上下文”。
RAG(检索增强生成)、对话历史、工具输出、系统指令的编排,都成了工程师需要操心的事。
用一个类比来理解:
- Prompt Engineering是给厨师一个菜谱
- Context Engineering是给厨师配备完整的厨房——食材、工具、操作手册、甚至其他厨师的协作
Context Engineering解决了Prompt Engineering的一个核心痛点:如何让AI持续地、稳定地、高质量地输出。
但Context Engineering也有它的局限。2025年下半年,一线实践者开始发现:光有好的上下文,Agent依然会失控。
技术播客Vanishing Gradients在一期节目中揭示了一个关键悖论:上下文窗口的扩大,并不等于Agent性能的线性提升。
即便模型理论上支持100万Token的上下文,性能衰减在25.6万Token左右便已出现。
更可怕的是:上下文可以告知Agent”知道什么”,但无法阻止Agent”做不该做的事”。
播客记录了一起造成5万美元损失的事故:一个无人监控的Agent陷入无限循环,API账单累积到被人发现时已经来不及了。
2.3 Harness时代(2026至今):环境设计决定输出质量
2026年2月5日,HashiCorp联合创始人Mitchell Hashimoto在博客发文,正式命名了一种新的工程范式——Harness Engineering。
他的定义很简洁:
“每当你发现Agent犯了一个错误,你就花时间设计一个解决方案,使Agent永远不再犯同样的错误。”
六天后,OpenAI发布了一份详细的内部实验报告,标题直接用了”Harness Engineering”这个词。再之后,知名工程师Martin Fowler在Twitter上为Thoughtworks工程师对这份报告的深度分析站台。
一个月之内,Harness Engineering从一篇博客文章变成了开发者社区的高频词。
Harness Engineering的核心洞察是:决定AI输出质量的最大变量,不是模型有多机智,而是模型被放在了一个什么样的环境里。
LangChain的编码Agent在Terminal Bench 2.0基准测试上,通过仅优化Agent运行的外部环境(文档结构、验证回路、追踪系统),排名从全球第30位跃升至第5位,得分从52.8%飙到66.5%。底层模型一个参数都没改[^5^]。
安全研究员Can Boluk仅仅改变了Agent的代码编辑格式,Grok Code Fast 1的基准得分就从6.7%跃升至68.3%[^10^]。
OpenAI的那份报告记录了一个更直观的工程实际:5名工程师,五个月,零行手写代码,通过Codex Agent协作交付了超过100万行代码的生产级软件产品[^11^]。
这些案例揭示了一个共同规律:同样的模型,在不同的Harness(环境)下,表现可以天差地别。
2.4 三者关系:不是替代,而是融合
Prompt Engineering、Context Engineering、Harness Engineering三者是什么关系?
用一个开车的类比来理解:
- Prompt Engineering是司机收到的导航指令——”去哪里、走哪条路、中途停哪些点”
- Context Engineering是司机看到的路况信息——”地图、实时交通、交通规则、车辆操作指南”
- Harness Engineering是整套车辆管控体系——”刹车、安全带、安全气囊、红绿灯、违章抓拍、行车记录仪”
三者不是替代关系,而是层层递进、相互融合的关系。
没有Prompt,Context和Harness就失去目标;没有Context,Prompt就缺乏依据;没有Harness,Prompt和Context就无法稳定、可靠、安全地执行。
对于个人数字资产库构建而言,这意味着什么?
意味着你需要同时关注三个层面:
- Prompt层:积累高质量的指令模板
- Context层:构建系统化的背景知识体系
- Harness层:设计资产的组织、管理、迭代机制
只有这样,你的数字资产库才能真正发挥价值。
“Prompt管说什么,Context管知道什么,Harness管在什么环境里做事。三者合一,才能驾驭AI。”
第三章:资产库的核心架构设计——热层+冷层双层模型
理解了数字资产的定义和时代演进的背景,目前让我们进入实操层面:如何设计你的个人资产库架构?
3.1 两层架构:热层(Active)+ 冷层(Archive)
基于AI工作的特点,我提议采用热层+冷层的双层架构:
热层(Hot Layer)——Agent上下文层
热层是当前活跃的、直接服务于AI交互的资产。它的特点是:
- 高频访问:每天多次使用
- 实时更新:根据反馈即时调整
- 与AI紧耦合:直接注入AI的上下文窗口
- 容量受限:受上下文窗口约束(一般100K-200K tokens)
热层的存储位置一般是:
- Claude 的 Projects(项目级自定义指令 + 知识库文件)
- ChatGPT 的 Custom Instructions(全局)或 GPTs(项目级)
- Cursor 的 Rules(.cursorrules 或 .cursor/rules/*.mdc 文件)
- OpenClaw 的 SOUL.md(系统级行为约束)或 Skill 定义(SKILL.md 文件)
冷层(Cold Layer)——长期存储层
冷层是归档的、备用的、历史积累的资产。它的特点是:
- 低频访问:按需检索,不是每次都用
- 结构化存储:有清晰的分类和标签
- 可检索:能在需要时快速找到
- 容量无上限:理论上可以无限扩展
冷层的存储位置一般是:
- 飞书/Notion知识库
- 本地文件夹(配合Obsidian/VS Code)
- GitHub仓库
- 云存储(iCloud/Google Drive)
3.2 热冷转换机制
热层和冷层不是固定不变的,它们之间需要建立动态的转换机制:
热→冷(降级)的触发条件:
- 项目结束,相关Context不再需要
- 资产过时,被新版本替代
- 热层容量溢出,需要释放空间
- 连续7天未被使用
冷→热(升级)的触发条件:
- 新项目启动,需要相关Context
- 需求匹配,某个Skill突然高频使用
- 热层刷新,纳入新的高频资产
3.3 六大场景域
为了让资产库更有条理,我提议按照工作场景来组织资产。以下是六大核心场景域:
场景域 说明 典型资产 内容生产 写作、编辑、翻译、润色 文章模板、风格指南、标题生成器 信息处理 搜索、总结、分析、提取 摘要Prompt、分析框架、阅读笔记 技术开发 编码、调试、架构、部署 代码模板、Review检查单、Debug流程 决策支持 评估、对比、规划、预测 决策矩阵、SWOT模板、风险评估 协作沟通 汇报、谈判、教学、反馈 邮件模板、会议纪要、PPT框架 系统优化 流程改善、自动化、知识管理 效率工具、自动化脚本、复盘模板
每个场景域下,你可以根据自己的需求进一步细分。例如”内容生产”可以细分为:
- 长文写作
- 短文/社交媒体
- 技术文档
- 邮件模板
3.4 双轨分类:人类视角 + Agent视角
为了让资产库既能被人高效使用,又能被AI高效检索,我提议采用双轨分类体系:
人类视角(场景驱动):
按”我目前要做什么”来组织,方便人找:
内容生产
├── 长文写作
├── 短文/社交媒体
├── 技术文档
└── 邮件模板
Agent视角(功能驱动):
按”执行时需要什么能力”来打标签,方便AI检索:
- input:pdf – 处理PDF输入
- output:chart – 生成图表输出
- skill:reasoning – 需要推理能力
- domain:finance – 金融领域
- tool:python – 需要Python工具
一个资产的完整元数据示例:
name: "财报可视化分析器"
human_path: "信息处理/商业分析/财报解读"
agent_tags:
- "input:pdf"
- "output:chart"
- "skill:reasoning"
- "domain:finance"
- "level:workflow"
3.5 资产类型全景图
除了Prompts、Skills、Context、Meta Skills、Workflows这五大类型,你的资产库还应该包括:
负面资产(Anti-Assets):
知道”什么不行”比知道”什么行”更难获得,也更有价值。
- 失败Prompt库:曾经尝试但效果不好的指令
- 误用案例:某Skill在X场景下会失效的记录
- 过度优化记录:为了提升5%效果却增加50%复杂度的尝试
- 废弃版本存档:Skill的历史版本及被替换缘由
元认知资产(Meta-Cognitive Assets):
- 个人思维模式图谱:你分析问题的典型步骤
- 决策日志:关键决策的场景、思考因素、结果
- 审美标准库:写作风格、设计偏好、代码规范
- 信任边界定义:哪些任务AI可以自主,哪些必须人工确认
连接性资产(Glue Assets):
- 数据格式契约:Skill A的输出必须能被Skill B消费
- 状态传递协议:跨Agent会话如何保持上下文
- 错误处理模式:标准错误码、降级策略、重试逻辑
“热层是战场,冷层是兵工厂。战场上只带最需要的武器,兵工厂里储备所有可能用到的装备。”
第四章:从0到1搭建你的资产库——7天实战计划
理论再完美,不落地都是空谈。本章将带你用7天时间,从零开始搭建一个可用的个人数字资产库。
4.1 Day 1:环境配置与工具准备
上午任务:核心工具安装
工具 用途 推荐配置 预计时间 Claude Code AI开发环境 最新版 30分钟 飞书 冷层管理 桌面版+移动端 15分钟 GitHub Desktop 版本控制 最新版 20分钟 Obsidian/VS Code 本地编辑 个人偏好 15分钟
Claude Code 配置清单:
# 1. 安装 Claude Code
npm install -g @anthropic-ai/claude-code
# 2. 初始化工作目录
mkdir ~/ai-assets && cd ~/ai-assets
claude init
# 3. 配置 MCP Servers
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-filesystem", "~/ai-assets"]
},
"github": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-github"]
}
}
}
下午任务:飞书多维表格创建
- 打开飞书,创建新文档
- 添加多维表格,命名为”AI资产库”
- 创建第一个视图:”Skill清单”
- 设置字段(详见下文完整字段清单)
Day 1 检查清单:
- Claude Code 安装成功,可正常启动
- 飞书多维表格创建完成
- GitHub 私有仓库创建(命名为 ai-assets-backup)
- 本地工作目录结构初始化
4.2 飞书多维表格设计(完整字段清单)
飞书多维表格是冷层管理的核心工具。以下是完整的字段设计:
基础信息区(必填):
字段名 类型 说明 示例值 Skill名称 文本 唯一标识 CodeReviewer 状态 单选 活跃/草稿/归档 活跃 版本 文本 语义化版本 1.2.0 创建日期 日期 首次创建时间 2024-01-15 最后更新 日期 最后修改时间 2024-01-20
使用统计区(自动/手动更新):
字段名 类型 说明 更新方式 使用次数 数字 累计使用次数 手动+脚本 本周使用 数字 本周使用次数 公式计算 成功率 百分比 满意结果占比 手动评估 平均耗时 数字 平均执行时间(秒) 脚本统计 最后使用 日期 最近一次使用 自动记录
分类标签区(便于检索):
字段名 类型 说明 示例 主分类 单选 大类归属 编程/写作/分析 子分类 多选 细分类别 代码审查, Python 标签 多选 自由标签 高频, 重大, 待优化 优先级 单选 使用优先级 P0/P1/P2/P3
Context管理区(热层相关):
字段名 类型 说明 示例 Context大小 数字 Token数量 850 热层状态 单选 常驻/按需/冷存 常驻 触发关键词 文本 自动触发词 review, 代码审查 依赖Skill 关联 依赖的其他Skill BaseFormatter
质量评估区(持续优化):
字段名 类型 说明 评分标准 输出质量 评分 1-5星 5=完美, 1=不可用 稳定性 评分 1-5星 5=100%成功 易用性 评分 1-5星 5=零学习成本 维护成本 评分 1-5星 5=零维护 综合评分 公式 加权计算 自动
4.3 Day 2-3:设计你的第一个Skill
选择标准:什么样的Skill值得第一个做?
不要选择”最酷”的,选择”最常用”的。推荐从以下场景中选择:
- 代码审查 – 如果你每天写代码
- 邮件回复 – 如果你每天处理大量邮件
- 会议纪要 – 如果你每周有3+次会议
- 内容摘要 – 如果你每天阅读大量文章
- 周报生成 – 如果你每周需要写汇报
第一个Skill设计模板:
# Skill: CodeReviewer
## 元信息
- 名称: 代码审查助手
- 版本: 1.0.0
- 创建日期: 2024-XX-XX
- 使用场景: 每日代码Review
- 预期频率: 每天3-5次
## 触发条件
- 用户发送代码片段
- 用户说"帮我看看这段代码"
- 文件扩展名为 .js/.py/.ts 等
## Context内容
你是一个经验丰富的代码审查员,专注于:
1. 发现潜在的bug和性能问题
2. 检查代码风格和最佳实践
3. 提出具体的改善提议
审查维度:
- 功能性:代码是否正的确 现了需求
- 可读性:命名、注释、结构是否清晰
- 性能:是否有明显的性能问题
- 安全性:是否存在安全隐患
- 可维护性:是否易于后续维护
输出格式:
## 总体评分: X/10
## 主要问题(按优先级排序)
1. [问题描述] - [具体位置] - [修复提议]
## 优点
- [具体优点]
## 改善提议
- [可执行的提议]
## 示例
输入: [一段有问题的代码]
输出: [预期的审查结果]
## 版本历史
- v1.0.0: 初始版本
4.4 Day 4-5:目录结构创建
合理的目录结构是资产库可维护的基础。以下是经过实践验证的目录结构:
~/ai-assets/
├── skills/ # Skill库(核心)
│ ├── active/ # 活跃Skill(热层候选)
│ ├── archived/ # 归档Skill(历史记录)
│ ├── drafts/ # 草稿Skill(开发中)
│ └── templates/ # Skill模板
│
├── contexts/ # Context库
│ ├── hot/ # 热层Context
│ ├── warm/ # 温层Context
│ ├── cold/ # 冷层Context
│ └── archive/ # 归档Context
│
├── examples/ # 示例库
│ ├── positive/ # 成功案例
│ └── negative/ # 失败案例
│
├── docs/ # 文档库
│ ├── guides/ # 使用指南
│ ├── decisions/ # 决策记录
│ └── references/ # 参考资料
│
├── scripts/ # 自动化脚本
│ ├── sync/ # 同步脚本
│ ├── analysis/ # 分析脚本
│ └── utils/ # 工具脚本
│
└── config/ # 配置文件
├── claude.json # Claude Code配置
├── mcp-servers.json # MCP Server配置
└── settings.yaml # 全局设置
4.5 Day 6:首批资产入库
首批5个种子Skill推荐:
序号 Skill名称 使用场景 优先级 1 CodeReviewer 代码审查 P0 2 EmailWriter 邮件撰写 P1 3 MeetingNotes 会议纪要 P1 4 ContentSummarizer 内容摘要 P2 5 WeeklyReport 周报生成 P2
入库流程:
Step 1: 创建Skill目录
└── mkdir skills/active/[SkillName]
Step 2: 复制模板文件
└── cp templates/skill-template/* skills/active/[SkillName]/
Step 3: 填写内容
└── 编辑 README.md, context.md, examples.md
Step 4: 创建元数据
└── 编辑 metadata.json
Step 5: 飞书记录
└── 在多维表格中添加记录
Step 6: Git提交
└── git add && git commit && git push
Step 7: 测试验证
└── 在Claude Code中实际使用
4.6 Day 7:第一周复盘与优化
复盘清单:
- 使用数据统计
- 本周使用了多少次AI辅助?
- 哪些Skill被使用了?
- 平均每次节省多少时间?
- 问题记录
- 哪些Skill没有达到预期?
- 使用过程中遇到了什么问题?
- 有哪些新的需求被发现?
- 下周计划
- 需要优化哪些现有Skill?
- 需要新增哪些Skill?
- 需要改善哪些流程?
第一周里程碑检查:
- 工具链完整配置
- 至少3个可用Skill
- 版本控制正常运行
- 飞书表格保持更新
- 记录了至少5次使用日志
“第一周的目标不是完美,而是跑起来。先让系统运转,再持续优化。”
第五章:热层管理与动态加载策略
热层是资产库中最宝贵的”黄金地段”——它直接决定AI输出的质量和效率。本章将教你如何科学管理热层。
5.1 上下文预算分配
AI的上下文窗口就像一块需要精密计算的工作内存,而非无限存储容器。2026年3月的最新实践表明:质量胜过数量——8000个精心筛选的token往往胜过1000万个噪声token。以下是一个基于当前主流模型(Claude Opus 4.6 / Sonnet 4.6 1M、GPT-5.4 1M、Gemini 3.0 Pro 1M)的推荐预算分配方案:
资产类型 预算占比 说明 个人基础信息 10% 风格、偏好、常用格式 当前项目Context 25% 项目背景、目标、约束 激活的Skills 15% 当前任务所需的Skill 对话历史/中间结果 25% 本轮对话的上下文 缓冲 25% 应对突发需求
为什么需要留25%的缓冲?
由于上下文窗口是工作内存而非存储空间。当窗口利用率超过90%,模型不仅读取受限,生成高质量回复所需的”思考空间”也会被挤压。Claude Code的实践经验表明:在75%利用率时触发压缩,保留25%自由空间,反而比榨干到95%获得更长的有效会话和更高质量的输出。
5.2 什么进热层?四大触发条件
不是所有资产都值得进热层。以下四大触发条件,协助你判断:
条件一:频率
- 每日使用的Skill → 常驻热层
- 每周使用3+次的Skill → 思考常驻
- 每月使用1-2次的Skill → 按需加载
条件二:时效
- 当前项目相关的Context → 项目期间常驻
- 即将到期的任务 → 任务期间常驻
- 长期不变的基础信息 → 永久常驻
条件三:依赖
- 被多个Skill依赖的基础Skill → 常驻
- 独立使用的Skill → 按需加载
条件四:效率
- 加载后显著提升效率的Skill → 常驻
- 加载成本高于使用收益的Skill → 冷层
5.3 热层切换流程
当任务变化时,你需要动态调整热层。推荐以下五步切换流程:
Step 1: 声明(Declare) 明确告知AI任务的变化: “接下来我要处理财报分析,需要加载相关Skill”
Step 2: 检索(Retrieve) 从冷层检索相关资产:
- 在飞书表格中搜索”财报”
- 查看匹配的技能列表
- 选择最合适的Skill
Step 3: 确认(Confirm) 确认加载的Skill和Context: “将加载:财报可视化分析器(Context: 850 tokens)”
Step 4: 加载(Load) 将选定的资产注入上下文:
- 复制Skill定义到对话
- 确认AI理解新任务
Step 5: 执行(Execute) 开始新任务的执行:
- 提供输入数据
- 获取AI输出
- 评估输出质量
5.4 预算监控方法
如何知道你的上下文预算使用情况?以下是几种监控方法:
方法一:手动估算
- 了解常见内容的token数:
- 100字中文 ≈ 150 tokens
- 一段代码(50行)≈ 500 tokens
- 一篇短文(1000字)≈ 1500 tokens
方法二:使用工具
- Claude Code内置的token计数器
- 在线token计算器(如 OpenAI Tokenizer)
方法三:经验法则
- 当你感觉AI”忘记”了之前的内容 → 可能触发了上下文截断
- 当AI输出质量突然下降 → 可能需要清理上下文
自动清理策略:
当上下文使用率超过90%时,自动触发清理:
- 压缩对话历史(保留摘要)
- 移除不再需要的Skill
- 归档中间结果
“热层管理的核心原则:不是越多越好,而是让对的资产在对的时间出现。”
第六章:Meta Skills实战开发
Meta Skills是资产库的”操作系统”,让资产库能够自我管理和进化。本章将介绍四大核心Meta Skill的开发方法。
6.1 Skill Searcher(技能搜索器)
功能:根据任务需求,从冷层检索相关Skill
输入:
- 任务描述(自然语言)
- [可选] 输入数据类型(pdf/url/文本等)
- [可选] 期望输出格式
输出格式:
recommendations:
- skill: "财报可视化分析器"
reason: "任务涉及PDF财报+图表输出,匹配度95%"
load_command: "加载财报分析Skill,启用Python图表输出"
context_cost: "约占用30%上下文窗口"
alternative: "如只需文本摘要,可用轻量版:财报摘要提取器"
检索逻辑:
- 提取任务关键词 → 匹配场景路径
- 识别输入/输出需求 → 匹配功能标签
- 按匹配度排序,返回Top-3
- 提供加载指令和上下文成本预估
6.2 Skill Evaluator(技能评估器)
功能:对新收集的Skill进行质量评估
评估维度:
维度 检测项 评分标准 安全性 代码审计、权限审查、数据泄露风险 1-10分 实用性 功能完整性、文档质量、社区活跃度 1-10分 适配度 与个人工作流匹配度、上下文占用 1-10分
输出格式:
skill_id: "web-search-v2"
source: "github:xxx/xxx"
security_score: 8.5/10
utility_score: 9.0/10
fit_score: 7.5/10
recommendation: "adopt_with_modification"
notes: "需修改输出格式以适配个人笔记系统"
6.3 Skill Curator(技能策展人)
功能:管理Skill的生命周期——收藏、分类、版本控制、归档
核心机制:
- 智能标签:自动提取功能标签、技术栈、适用场景
- 版本快照:记录Skill的演进历史,保留稳定版本
- 使用追踪:记录调用频率、成功率、迭代修改
- 冷启动策略:低频Skill自动降级到冷存储
存储策略:
频率 存储位置 加载方式 每日使用 Agent常驻上下文 预加载 每周使用 本地Hot Cache 快速加载(<2s) 每月使用 飞书/Notion知识库 按需检索 极少使用 GitHub Archive 手动恢复
6.4 Skill Router(技能路由器)
功能:根据任务自动选择最优Skill组合
核心能力:
- 意图识别:解析用户真实需求,匹配最佳Skill
- 上下文管理:动态加载/卸载Skill,优化窗口使用
- 故障转移:Skill失效时自动切换备选方案
- 学习优化:根据历史执行反馈优化路由策略
决策示例:
用户输入:"帮我分析这份财报并生成可视化"
↓
Router分析:
- 任务分解:数据提取 → 分析 → 可视化
- Skill匹配:
* pdf-extractor-skill(加载)
* financial-analysis-skill(加载)
* chart-generation-skill(按需加载)
- 上下文预算:预留60%给数据,20%给分析指令,20%缓冲
- 执行监控:如pdf提取失败,切换至ocr-fallback-skill
“Meta Skills是资产库的'大脑',让系统能够自我管理、自我进化。”
第七章:长期迭代与进化机制
资产库不是一次性工程,而是需要持续迭代的 living system。本章将介绍如何让资产库自我进化。
7.1 每周Review机制
核心原则:删除 > 添加
大多数资产库的问题不是”不够丰富”,而是”丰富到无法维护”。因此,Review的首要任务是删除。
Review流程:
Step 1: 数据收集(10分钟)
- 导出本周使用日志
- 统计各Skill使用次数
- 标记未使用的资产
Step 2: 删除决策(15分钟)
- 连续2周未使用的Skill → 降级到冷层
- 连续1个月未使用的Skill → 归档
- 满意度<3分的Skill → 删除或重写
Step 3: 优化决策(15分钟)
- 满意度3-4分的Skill → 标记待优化
- 收集改善提议
- 制定优化计划
Step 4: 新增决策(10分钟)
- 识别新的需求场景
- 评估是否需要新增Skill
- 优先解决高频痛点
7.2 失败案例库建设(Anti-patterns)
为什么需要记录失败?
知道”什么不行”比知道”什么行”更难获得,也更有护城河。失败知识是个人认知的护城河。
失败案例模板:
# 失败案例:过度优化的Prompt
## 案例描述
尝试用一个Prompt覆盖所有写作场景,结果:
- 长度:800+ tokens
- 复杂度:12个条件分支
- 效果:每个场景都只有70分,没有90分场景
## 失败缘由
1. 追求"万能",忽视场景特异性
2. 条件分支过多,模型理解成本上升
3. 维护困难,修改一处影响全局
## 教训
- 宁可3个专用90分Prompt,不要1个万能70分Prompt
- 通用部分抽象为Context,可变部分保持独立
- 复杂度控制在"一眼能看懂"的程度
## 当前实践
- 基础层:个人风格Context(常驻)
- 场景层:专用Prompt(按需加载)
- 组合层:由Agent根据场景选择
7.3 使用数据追踪与分析
核心指标:
指标 说明 目标值 资产使用率 活跃资产数 / 总资产数 >50% 平均使用频率 总使用次数 / 活跃资产数 >3次/周 满意度评分 用户主观评分平均值 >4分 节省时间 使用资产前后的时间差 >50%
周报模板:
# 资产库周报(2026年第X周)
## 使用统计
- 总使用次数:XX次
- 最常用Skill:XXX(XX次)
- 新增资产:X个
- 优化资产:X个
- 删除资产:X个
## 本周亮点
- [具体案例]
## 本周问题
- [具体问题]
## 下周计划
- [优化计划]
7.4 资产活性评估公式
如何评估一个资产的”健康度”?可以使用以下公式:
资产活性 = 使用频率 × 迭代速度 × 可组合性 × 可解释性
各维度说明:
- 使用频率:多久用一次(每天/每周/每月)
- 迭代速度:根据反馈优化的周期(天/周/月)
- 可组合性:能和其他资产搭配产生新价值(高/中/低)
- 可解释性:你为什么这样设计,别人能否理解(高/中/低)
高活性资产示例: 一个每周用、每月优化、能嵌入3个不同工作流、有完整设计文档的”会议纪要生成器”
低活性资产示例: 一个收藏了半年从没用过、不知道来源、不知道适用场景的”万能Prompt”
“资产库的质量 = 移除速度 × 添加速度。只加不减,必死。”
第八章:实战案例——两个完整的工作流
理论说再多,不如看两个真实的案例。本章将展示两个不同场景下的资产库应用。
8.1 案例一:内容创作者的一周工作流
人物画像:
- 小王,自由撰稿人,主要写科技评论文章
- 痛点:选题困难、写作效率低、质量不稳定
- 目标:建立可复用的内容生产系统
资产库构建过程:
Week 1: 诊断与规划
- 用”效率系统审计器”扫描现有工作流
- 识别三大瓶颈:选题随机、素材散乱、缺乏复盘
- 制定资产库建设计划
Week 2-3: 热层搭建
- Claude Projects创建”内容生产”项目
- 导入核心Context:
- 个人写作风格指南(500字)
- 读者画像(3个典型用户)
- 历史爆款文章分析(5篇)
- 创建核心Prompts:
- 选题评估器
- 大纲生成器
- 标题优化器
Week 4: 冷层整理
- 飞书知识库建立”内容资产”空间
- 分类体系:选题库→素材库→成品库→数据复盘
- 导入历史积累的文章、笔记、灵感
Week 5-8: 迭代优化
- 每周用”周复盘模板”评估资产使用效果
- 根据数据调整Prompts和Context
- 沉淀新的资产到冷层
成果数据:
指标 优化前 优化后 提升 单篇文章耗时 8小时 4小时 50% 选题命中率 30% 65% 117% 读者满意度 3.8/5 4.5/5 18%
8.2 案例二:开发者的AI协作系统
人物画像:
- 小李,全栈开发者,独立开发SaaS产品
- 痛点:重复编码、文档滞后、技术债务累积
- 目标:用AI提升开发效率,降低维护成本
Harness Engineering实践:
阶段一:可观测性建设
- 建立开发日志系统
- 记录每次AI协作的输入、输出、结果
- 工具:Cursor的Chat History + 自建日志模板
阶段二:资产沉淀
- Prompt库建设:
- 代码生成类(组件、API、测试)
- 代码审查类(Bug检测、性能优化)
- 文档生成类(README、API文档)
- Context库建设:
- 项目架构文档
- 技术栈规范
- 设计模式指南
阶段三:工作流编排
- 新功能开发流程:
- 需求分析(AI辅助)
- 技术方案(AI生成初稿)
- 代码实现(AI辅助编码)
- 代码审查(AI初审+人工终审)
- 测试覆盖(AI生成测试用例)
- 文档更新(AI同步更新)
阶段四:可回滚机制
- 所有AI生成的代码必须人工审核
- 关键决策保留AI提议+人工判断记录
- 建立”AI决策日志”用于复盘
写在最后
AI时代,个人竞争力的核心正在发生根本性转移。
过去,价值来自于”你会什么”——掌握的技能越多,价值越高。
目前,价值来自于”你能多高效地调用和编排AI能力”——你构建的数字资产库越系统化、越可复用、越可进化,价值越高。
但这篇文章想传达的更重大的一点是:构建资产库的过程本身,就应该用AI来辅助。Claude Code、OpenClaw、MCP协议——这些工具本身就是Harness Engineering的最佳实践。用它们来构建你的资产库,就是AI原生思维的体现。
同时,要清醒认识到:基座模型的能力还在快速进化,你今天构建的许多东西,未来可能被模型的原生能力覆盖。因此,你的资产库需要具备可迁移性,你的差异化价值需要来自于个性化数据、领域深度、价值判断——这些是模型无法替代的。
最终,数字资产库的质量不取决于你拥有多少资产,而取决于:
你能多快找到需要的资产
你的资产能多稳定地产生高质量输出
你的资产库能多快速地适应变化
你能在模型能力进化的过程中,始终保持差异化价值。
附录:推荐工具与资源
热层工具
- Claude Projects:深度研究、复杂分析
- ChatGPT自定义GPT:特定领域助手
- Cursor:代码开发
- OpenClaw:多Agent编排
冷层工具
- 飞书知识库:团队协作、文档沉淀
- Notion:个人知识管理
- Obsidian:深度知识网络
- GitHub:代码资产、版本控制
推荐阅读
- 《Harness Engineering》by Martin Fowler
- 《Building LLM Applications》
- LangChain官方文档
社区资源
- MCP协议官方文档
本文完。如果你觉得有收获,欢迎分享给更多朋友。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...