先说结论:这两个模型当然可以比,由于它们代表了当前大模型技术路线的两个典型分支——一个在专业深度上持续加码,另一个在通用宽度和体验上构筑壁垒。选择Claude Opus 4.7还是GPT-4,取决于你更需要一个严谨的专家,还是一个灵活的助手。
之所以拿这两个模型来比,是由于它们都瞄准了同一个市场:企业级AI应用和重度个人用户。它们都拥有庞大的上下文窗口(Claude的100万Token对GPT-4的128K),都支持多模态,都提供API和订阅服务。但在此之上,它们的设计哲学和优化路径出现了关键分歧,这直接导致了性能表现的鲜明分野。
编程能力对决,Claude实现了关键超越
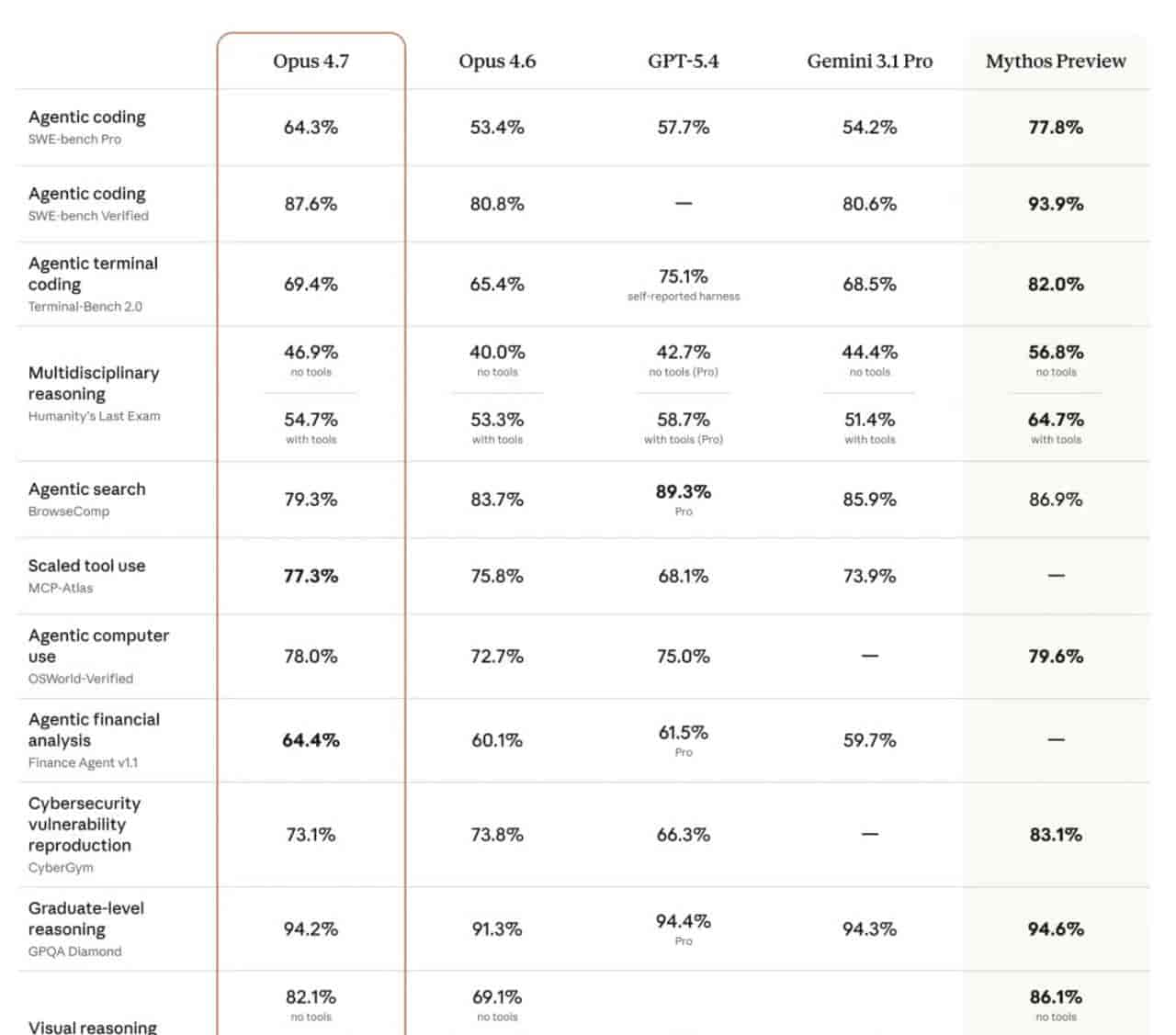
在衡量真实软件工程能力的硬核测试SWE-bench Pro中,Claude Opus 4.7取得了**64.3%**的得分,而作为主要参照的GPT-5.4(代表OpenAI当前顶级水平)为57.7%。这近7个百分点的差距,是Claude在专业领域拉开身位的关键证据。
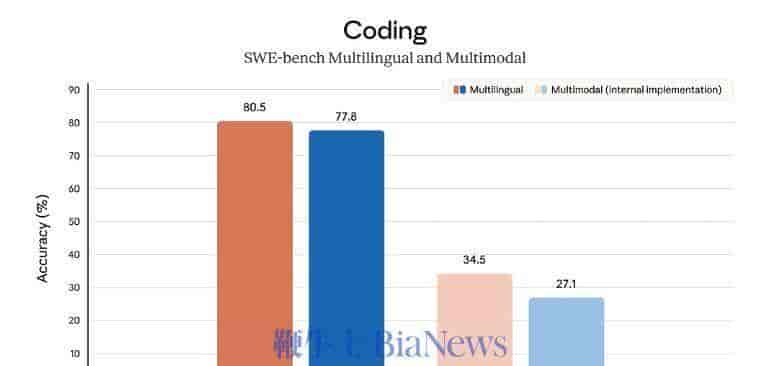
更值得关注的是行为差异:用户反馈和早期合作伙伴(如Stripe、Replit)的测试表明,Opus 4.7在处理复杂任务时,会主动进行自我验证甚至自我纠错,在执行前就尝试捕捉逻辑缺陷。这让它在处理那些以往需要工程师密切监督的高难度编程任务时,显得更可靠。

而GPT系列在代码生成上同样顶尖,但其输出风格更倾向于“一次成型”,在严谨的长期任务规划和自我验证机制上,Claude当前的策略似乎更受专业开发者青睐。
视觉与工具调用,Claude的“高分辨率”优势与“不编造”原则
在视觉能力上,Claude Opus 4.7实现了一次硬件级提升:其支持的图像输入分辨率长达2576像素(约375万像素),是前代模型的3倍,也显著高于GPT-4V等模型常见的1024像素级别。
这使得它在解析技术图纸、化学分子结构、密集的UI截图等需要像素级细节的任务上,具备了天然优势。反映在测试中,其CharXiv视觉推理得分(使用工具)达到了91.0%。
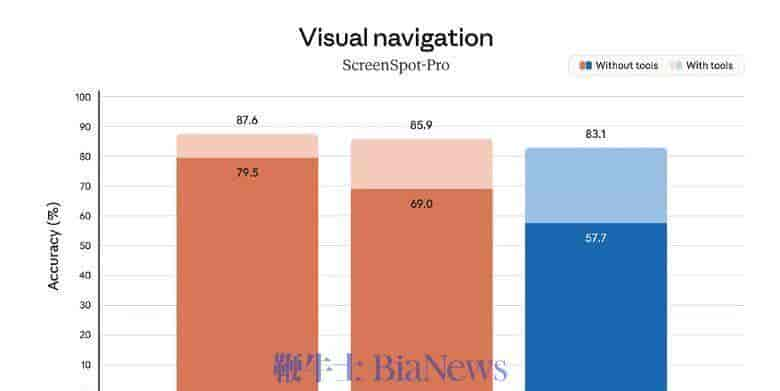
在工具调用方面,Claude Opus 4.7在MCP-Atlas(衡量复杂多轮工具调用)基准上以77.3%领先于GPT-5.4的68.1%。这体现了它在规划、执行多步骤任务时的协调能力。不过,在BrowseComp这类代理搜索测试中,它的得分(79.3%)却低于GPT-5.4(89.3%)。
Anthropic官方对此的解释是:Opus 4.7在遇到信息缺失时,倾向于直接报错而非编造一个看似合理的答案,因此在以“是否给出答案”为标准的测试中会吃亏。这恰好点明了两个模型的核心性格差异:Claude追求严谨准确,GPT追求完成与流畅。
成本与体验,GPT-4的“好用”与Claude的“好用但贵”
这是最现实的分水岭。Claude Opus 4.7的API定价为输入$5/百万Token,输出$25/百万Token。更关键的是,其全新的分词器导致一样文本的Token消耗可能增加10%-35%,高分辨率图像处理可能使Token消耗暴涨3倍以上。
加上其在复杂任务中“愿意思考更久”的特性,实际使用成本可能远超标价。有用户反馈“3-4个复杂问题就可能耗尽Pro订阅额度”。
相比之下,GPT-4通过ChatGPT Plus订阅制($20/月)为用户提供了稳定的使用门槛和额度,更适合日常高频、轻量级的交互。其API定价虽因版本和平台而异,但整体上Token利用效率被认为更优,在通用任务中成本更可控。
体验上,GPT-4在对话的自然度、多模态交互的流畅性(尤其是GPT-4o的实时音频)上更胜一筹。而Claude Opus 4.7被部分用户评价为“更难聊”、“更字面”,需要用户给出更准确的指令才能发挥最佳效果。
其优势体验在于处理超长文档(百万Token上下文)和跨会话记忆任务时,表现得更为连贯。
结论:根据你的任务画像做选择,没有万能答案
经过以上对标,最关键的那个差异变量已经浮现:模型优化的核心目标。
- Claude Opus 4.7 优化目标是降低专业任务中的人工复核成本。它通过提升严谨性、准确性和长任务可靠性,尝试成为金融、法律、高级软件工程等领域的“专家同事”。为此,它牺牲了部分对话柔顺度和成本可控性。
- GPT-4系列 优化目标是最大化通用场景下的用户体验和任务完成率。它追求在绝大多数情况下给出流畅、有用、即时的回应,并通过灵活的订阅和API模式覆盖最广泛的用户群体。
因此,这个选择并不复杂:
- 选Claude Opus 4.7,如果你:是专业开发者,处理代码重构、系统级编程;是金融分析师或律师,需要严谨的模型、报告和法律文本分析;常常需要处理整本书、超长技术文档,并从中进行准确信息提取和推理;且预算相对充足,愿意为更高的准确率和可靠性支付溢价。
- 选GPT-4(尤其是GPT-4o),如果你:需要日常的创意写作、内容生成、多轮对话客服;看重多模态交互,尤其是语音对话能力;进行通用性的数据分析、研究和学习;对使用成本敏感,或需要高度定制化(微调)模型以适应特定场景;追求开箱即用、自然流畅的交互体验。
它们不是简单的“谁更好”,而是在回答“好在哪里,为谁而好”。在AI工具日益分化的今天,认清自己的核心需求,比追逐单项跑分第一更重大。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





![西游H5圆美商业服务端游戏源码[教程+支持内充+GM后台]](https://img.dunling.com/smtb/20230825/64dd930b9af14cb7a041010bbcca032f.jpg)