记得团队 AI Coding Agent 上线初期,大模型删掉了记录开发者个人偏好的配置文件,导致部分团队生码不符合团队规范,我们才意识到构建 AI 应用安全底线的重大性,大模型的自主泛化能力,在确定性要求极高的编程领域从特长变成了工程架构必须要解决的问题。今天我们重点讨论如何使用 Claude Code Hooks 打造 AI 应用的安全底线。文章中的每一行代码我都脱敏验证过,大家可直接复制引入自己的项目。
Hooks 在解决什么问题?
我之前的文章分析过,Skills 解决:怎么做以及有哪些文档可以参考着做的问题。那么 Hooks 解决:模型能不能做以及做完之后质量如何验证的问题。Hooks 最常见的应用场景:
- 构建安全底线:不该删的文件(除了临时文件,几乎所有文件都不允许硬删除),不能编辑的文件(用户的隐私文件,开发者的配置文件等),大模型绝对不能碰。
- 代码规范检查。大模型生成的代码,是否符合团队编码规范,是否有安全漏洞必须做后置位的检查。
用前后端技术概念类比,讲清楚 Hooks 的本质:
- Hooks 相当于前端 React 组件的生命周期钩子函数,用户可以在钩子函数定义自己的逻辑。
- Hooks 相当于服务端中间件。给开发者提供面向切面编程的能力,统一处理权限校验、日志埋点等不该业务代码去关心的逻辑。
一句话总结 Hooks 的核心价值:Hooks 统一处理代码规范以及安全问题,让大模型专注在需求理解以及代码生成上。Claude Code 是如何做到这一点的?拿工具调用举例:
用户请求 -> Claude 主任务 > PreToolUse Hook > 调工具 > PostToolUse Hook > 完结任务在工具调用前,我们可以定制 PreToolUse Hook 做安全检查,检查不通过阻止大模型调用工具;在工具调用后,我们可以定制 PostToolUse Hook 做文件格式化等规范校验。划重点:如果你想拦截或者改变 Claude 的行为,Hooks 是你唯一的选择,Skills 以及内置的命令都做不到。
Claude Code Hooks 概念与分类
Hooks 是通过事件来驱动的,也就是说 Claude Code 第一需要暴露出事件(也叫钩子),我们才能在钩子里面定制逻辑,截止到今天,Claude Code 官网支持 26 个事件。覆盖了从任务启动到任务结束的整个生命周期,参考官方给的图:
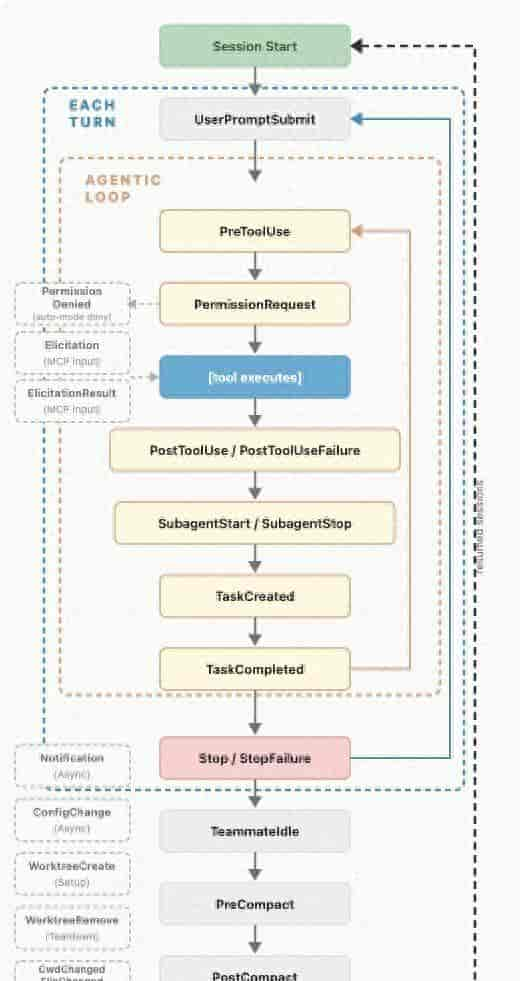
Claude Code Hooks 生命周期
大脑的记忆是有限的,我们学习新知识,不要着急记住所有细节,先在大脑中建立知识索引,标出重点知识,分支知识。优先学习重点知识,分支知识可以等需要的时候再根据索引反查知识点。接下来建立知识索引:适用场景到事件名称的映射关系:
- 我想对工具的入参做校验,危险操作阻止调用工具。记住:PreToolUse、UserPromptSubmit、Stop、SubagentStop。
- 我想内置默认逻辑。PermissionRequest 用来接管原本需要用户手动处理的权限弹窗,通过 Hooks 自动通过或拒绝权限请求。
- 我想对工具的返回值做一些后处理。记住:SessionStart、PostToolUse、PostToolUseFailure、Notification、SubagentStart、PreCompact、SessionEnd。
Hook 配置讲解
配置文件位置
Claude Code 支持在以下三个位置配置,根据你的述求做选择:
- 用户级:~/.claude/settings.json 根据你的个人习惯来配置,列如你喜爱的日志格式,只影响你自己,不需要共享给团队。
- 项目级:.claude/settings.json 团队约定,列如代码规范、文件黑名单,这些配置必须提交到 git 代码仓库,团队共享。
- 本地:.claude/settings.local.json 你写好的 Hook 想覆盖团队配置临时调试一下。
不管在哪里配,Hook 配置都长这样:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/dangerous.sh",
"timeout": 30000
}
]
}
]
}
}分层来看每个字段如何配置?
hooks 第一层:容器
├── PreToolUse 第二层:事件类型:触发时机
│ └── [第一组规则]
│ ├── matcher: "Bash" 第三层:匹配器:针对哪个工具生效
│ └── hooks: [...] 第三层:Hooks:你的定制逻辑写这里
│ └── type: "command"
│ └── command: "..."
│ └── timeout: 30000配置项讲解
matcher:指定 Hook 针对哪些工具生效,支持四种匹配模式:
- 准确匹配单个工具。示例:”matcher”: “Write”
- 匹配多个工具(用竖线分隔)。示例:”matcher”: “Edit|Write|MultiEdit”
- 匹配所有工具。示例:”matcher”: “*”。慎用:仅适合需要无差别校验的场景。
- 空匹配(拦截生命周期事件,不适用于拦截工具)。示例:”matcher”: “”
type:支持 command、prompt、http、agent。
- command:指定 Shell 脚本路径或者 Shell 命令,最常用的场景。timeout 指定超时毫秒时间,默认 60 秒。
- prompt:会用小模型(一般是 Haiku)来评估当前情况。列如:这些代码是否有安全漏洞,这需要理解代码的语义,模式匹配搞不定。
{
"type": "prompt",
"prompt": "写你的校验条件,列如:评估任务是否正确完成,检查是否存在错误或未完成的工作。"
}- http:定制逻辑不在本地执行,把事件数据 POST 到云端,由远程服务返回结果。
- agent:最“重”的评估方式,会启动一个子 Agent,这个子 Agent 可以翻你的代码仓库做决定。
类型选择指南
如何选择 type ?参考如下指南:
|
类型 |
场景 |
超时默认值 |
确定性 |
|
command |
超级确定的规则校验,文件检查 |
600s |
最确定,输入不变输出不变 |
|
prompt |
只有自然语言,需要模型来判断 |
30s |
中等,依赖模型能力 |
|
agent |
需要翻阅代码做判断 |
60s |
子代理决定 |
|
http |
需要调用云端服务做判断 |
600s |
远程服务的稳定性 |
原则:永远优先选择确定性最高的方案,除非不得已。
Shell 脚本与 Claude 的通信机制
拿 PreToolUse Hook 举例,PreToolUse Hook 类似安检,物品安全再乘车否则拒载。检查完毕需要将检查结果告知 Claude:允许(allow),拒绝(deny),修改参数后再执行(updatedInput)。PreToolUse Hook Shell 脚本第一从 stdin(命令行标准输入)拿到 JSON 格式的上下文:
{
"session_id": "xxx",
"transcript_path": "/path/to/transcript.jsonl",
"cwd": "/project/root",
"permission_mode": "default",
"hook_event_name": "PreToolUse",
"tool_name": "Bash",
"tool_input": {
"command": "rm -rf /tmp/test"
}
}解析 `tool_input.command` 就能知道是否属于危险操作。通过退出码或者 json 告知 Claude 结果:exit 0 表明放行;exit 2 表明阻止,官方推荐使用 json 格式(hookSpecificOutput):
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "allow | deny | ask" // 三选一
}
}PreToolUse Hook 实践
目标:使用 PreToolUse Hook 拒绝工具执行危险命令。
第一步、修改 settings.json
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "./hooks/dangerous.sh"
}
]
}
]
}
}第二步、编写 dangerous.sh 脚本,位置:项目目录/hooks/dangerous.sh
#!/bin/bash
# dangerous.sh
# 拒绝执行危险的 Bash 命令,参考官方文档的写法
set -e
# 读取 stdin 输入
INPUT=$(cat)
# 解析命令
COMMAND=$(echo "$INPUT" | jq -r '.tool_input.command // ""')
# !注意:调试日志输出到 stderr,不影响给到大模型的 JSON 响应
echo "DEBUG: Checking command: $COMMAND" >&2
# 危险命令黑名单
DANGEROUS_PATTERNS=(
"rm -rf"
"rm -rf ~"
"rm -rf /"
"rm -rf $HOME"
"rm -rf /*"
"> /dev/sd"
"mkfs."
"dd if="
":(){:|:&};:"
"chmod -R 777 /"
"git push --force origin main"
"git push --force origin master"
"git reset --hard origin"
"DROP DATABASE"
"TRUNCATE"
"curl.*| sh"
"curl.*| bash"
"wget.*| sh"
"wget.*| bash"
)
# 检查每个危险模式
for pattern in "${DANGEROUS_PATTERNS[@]}"; do
if [[ "$COMMAND" == *"$pattern"* ]]; then
echo "BLOCKED: Command matches dangerous pattern: $pattern" >&2
cat <<EOF
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "Blocked dangerous command pattern: $pattern. This command could cause irreversible damage."
}
}
EOF
exit 2
fi
done
# 命令安全,可以发起后续的工具调用
echo '{}'
exit 0如果不熟悉 Shell 脚本,可以让豆包或者千问帮你写脚本(注意:大模型生成的脚本,读取入参的地方需要参考官网调整),提示词如下:
写一段 sh 脚本,要求:1.读取 stdin 输入,判断是否包含危险 sh 命令,列如:rm -rf、curl.*| sh 等
2.常见危险命令写成黑名单,如果 stdin 输入存在黑名单中的命令,输出:cat <<EOF
{
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": "Blocked dangerous command pattern: $pattern. This command could cause irreversible damage."
}
}
EOF exit 2。如果 stdin 输入不包含黑名单中的命令,输出:echo '{}';exit 0。3、脚本使用 jq 处理 json 字符串。第三步、验证效果。
方式1:进入 claude 主任务,输入:
执行 rm -rf configs/pro.config.ts,删掉配置文件观察日志发现危险命令被 Hook 阻止了:

Hook 拦截效果
方式2:直接终端运行:echo '{“tool_input”:{“command”:”rm -rf /”}}' | ./hooks/dangerous.sh

终端命令验证 Hook
PostToolUse Hook 实践
PostToolUse Hook:工具调用成功之后执行。适用场景:后处理(格式化、质量验证)、反馈(告知 Claude 校验结果)以及记录日志。接下来我们手搓一个 PostToolUse Hook。相比 PreToolUse,PostToolUse Hook 会多拿到一个工具返回值字段 tool_response:
{
"session_id": "xxx",
"hook_event_name": "PostToolUse",
"tool_name": "Write",
"tool_input": {
"file_path": "/project/src/admin.js",
"content": "xxx"
},
"tool_response": {
"success": true,
"result": "xxx"
}
}PostToolUse 需要使用 additionalContext 字段向 Claude 反馈质量检查结果:
{
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"additionalContext": "ESLint found 3 errors in the file you just wrote."
}
}additionalContext 会被注入 Claude 当前任务的上下文中,从而调整自己的行为,修复问题提升输出质量。接下来手搓一个 PostToolUse Hook。
目标:使用 PostToolUse Hook 格式化 Claude 产出的代码。
第一步、修改 settings.json
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write",
"hooks": [
{
"type": "command",
"command": "./hooks/format.sh"
}
]
}
]
}
}第二步、编写 format.sh 脚本,位置:项目目录/hooks/format.sh
#!/bin/bash
# format.sh
# 自动格式化代码文件,参考官方文档的写法
set -e
INPUT=$(cat)
FILE_PATH=$(echo "$INPUT" | jq -r '.tool_input.file_path // ""')
# 没有文件路径,无需格式化
if [ -z "$FILE_PATH" ] || [ ! -f "$FILE_PATH" ]; then
echo '{}'
exit 0
fi
echo "DEBUG: Begin Format file: $FILE_PATH" >&2
# 获取文件扩展名
EXTENSION="${FILE_PATH##*.}"
# 根据文件类型选择格式化工具
case "$EXTENSION" in
js|jsx|ts|tsx|json|md|css|scss|html)
if command -v npx &> /dev/null; then
if npx prettier --write "$FILE_PATH" 2>&1; then
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Format use Prettier"}}'
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Prettier format failed"}}'
fi
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Prettier not available"}}'
fi
;;
py)
if command -v black &> /dev/null; then
if black "$FILE_PATH" 2>&1; then
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Format use Black"}}'
else
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Black format failed"}}'
fi
fi
;;
go)
if command -v gofmt &> /dev/null; then
gofmt -w "$FILE_PATH" 2>&1
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Format with gofmt"}}'
fi
;;
rs)
if command -v rustfmt &> /dev/null; then
rustfmt "$FILE_PATH" 2>&1
echo '{"hookSpecificOutput": {"hookEventName": "PostToolUse", "additionalContext": "Format with rustfmt"}}'
fi
;;
*)
echo '{}'
;;
esac
exit 0注意事项
以上两个实践,都需要注意:
1、提前安装 jq(Shell 脚本处理 json 数据依赖该库):brew install jq
2、sh 脚本需要赋执行权限:chmod +x ./hooks/dangerous.sh
总结
本章节我们学习了:Hooks 解决的问题、基础概念以及用法,通过文中的两个实践,我们能建立起 AI 应用最基本的安全防线,让大模型专注处理业务逻辑。 下一个章节我们讲解 Hooks 的高阶用法:如何实现多 Hooks 链式调用?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...





![西游H5圆美商业服务端游戏源码[教程+支持内充+GM后台]](https://img.dunling.com/smtb/20230825/64dd930b9af14cb7a041010bbcca032f.jpg)