
具与行动层 — Agent 的”手”到底怎么造?
一个只会”想”不会”做”的 Agent,和一个只会输出文字的聊天机器人没有本质区别。
Agent 真正的能力上限,取决于它能调用哪些工具——以及你有没有正确地造这些”手”。
—- 创作不易,请点赞收藏!
看完这篇,你会学到:
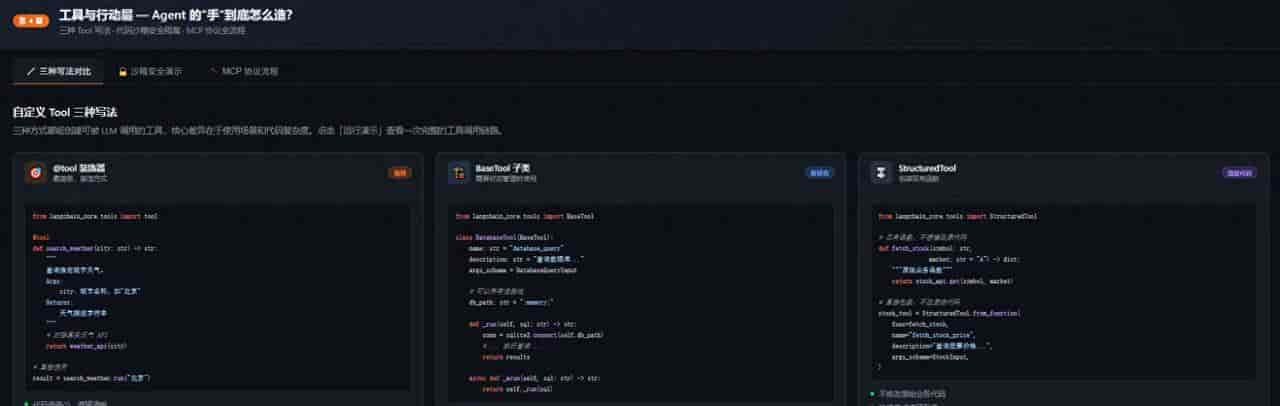
- 自定义 Tool 的三种写法(@tool 装饰器、BaseTool 子类、StructuredTool),以及各自适合什么场景
- 代码执行沙箱的安全隔离方案,避免 Agent 跑出来”删库跑路”
- MCP 协议是什么、为什么 2024 年之后几乎所有 Agent 框架都在接入它
一、工具层是什么?
先做类比。
LLM 是大脑,规划推理层是思维,而工具层是 Agent 的手和脚。
没有工具的 Agent,无论”想”得多精妙,最终只能输出文字——它看不了网页、查不了数据库、跑不了代码,更别说操作文件、发邮件、调第三方 API。
工具层解决的核心问题是:把真实世界的能力,封装成 LLM 可以调用的标准接口。
LangChain 的工具调用流程:
LLM 决定调用工具
→ 工具层解析工具名 + 参数
→ 执行对应函数
→ 把结果作为 Observation 返回给 LLM
→ LLM 继续推理
整个架构图里,工具层分三类:
|
类别 |
典型工具 |
核心能力 |
|
信息获取 |
Web 搜索、数据库查询、文件读取 |
给 Agent 提供外部知识 |
|
代码执行 |
Python 沙箱、Shell 命令 |
让 Agent 真正”做计算” |
|
业务集成 |
HTTP API、MCP 协议、邮件/日历 |
接入现有系统和服务 |
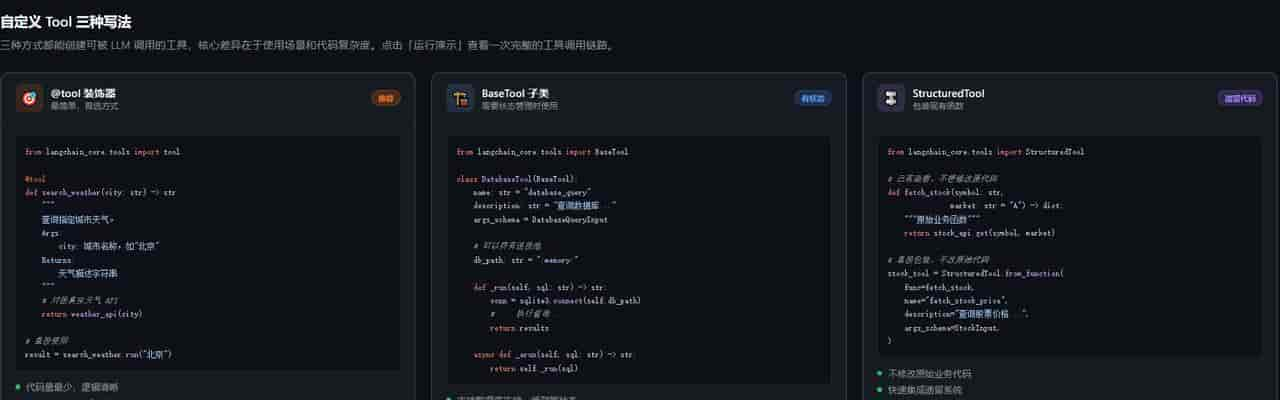
二、自定义 Tool 的三种写法
写法一:@tool装饰器(最简单,80% 场景够用)
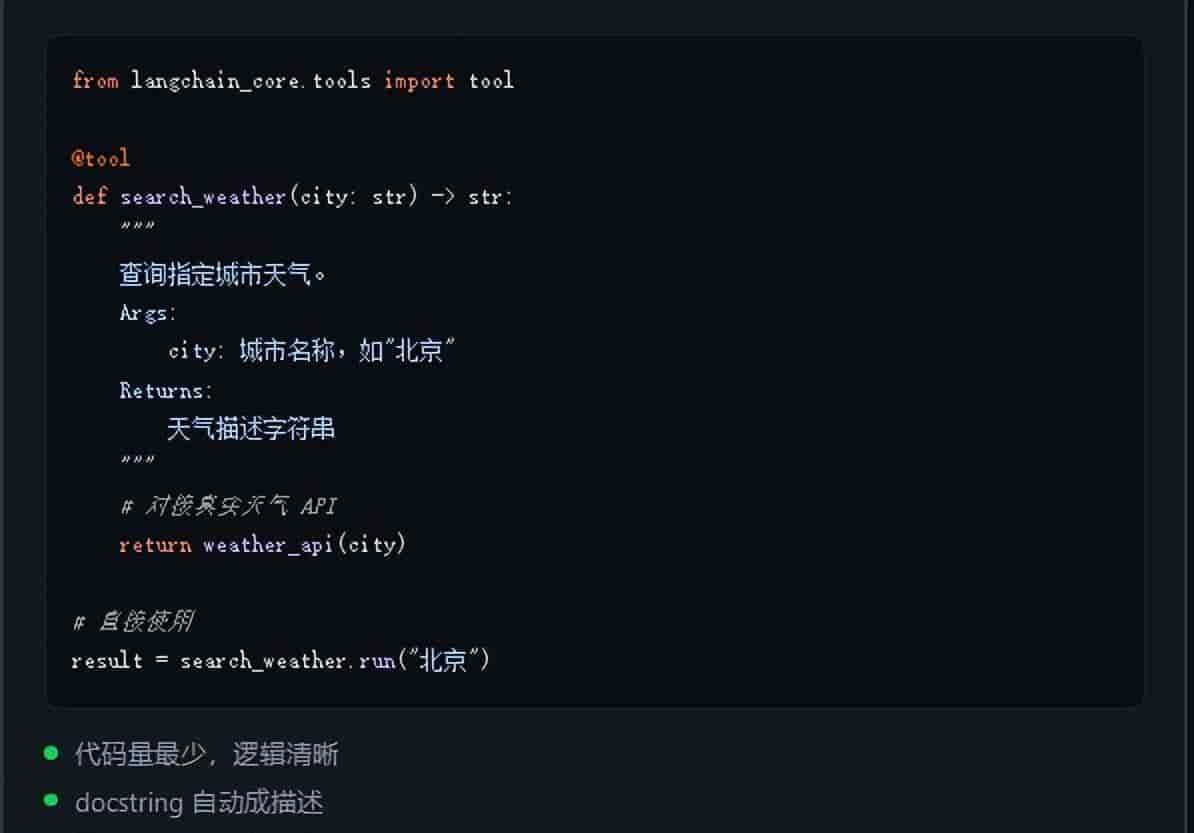
关键点:docstring 是写给 LLM 看的,越清晰准确,LLM 调用越精准。
写法二:BaseTool子类(需要状态管理或复杂初始化)
当工具需要持有数据库连接、API 客户端等有状态对象时,用 BaseTool 子类:
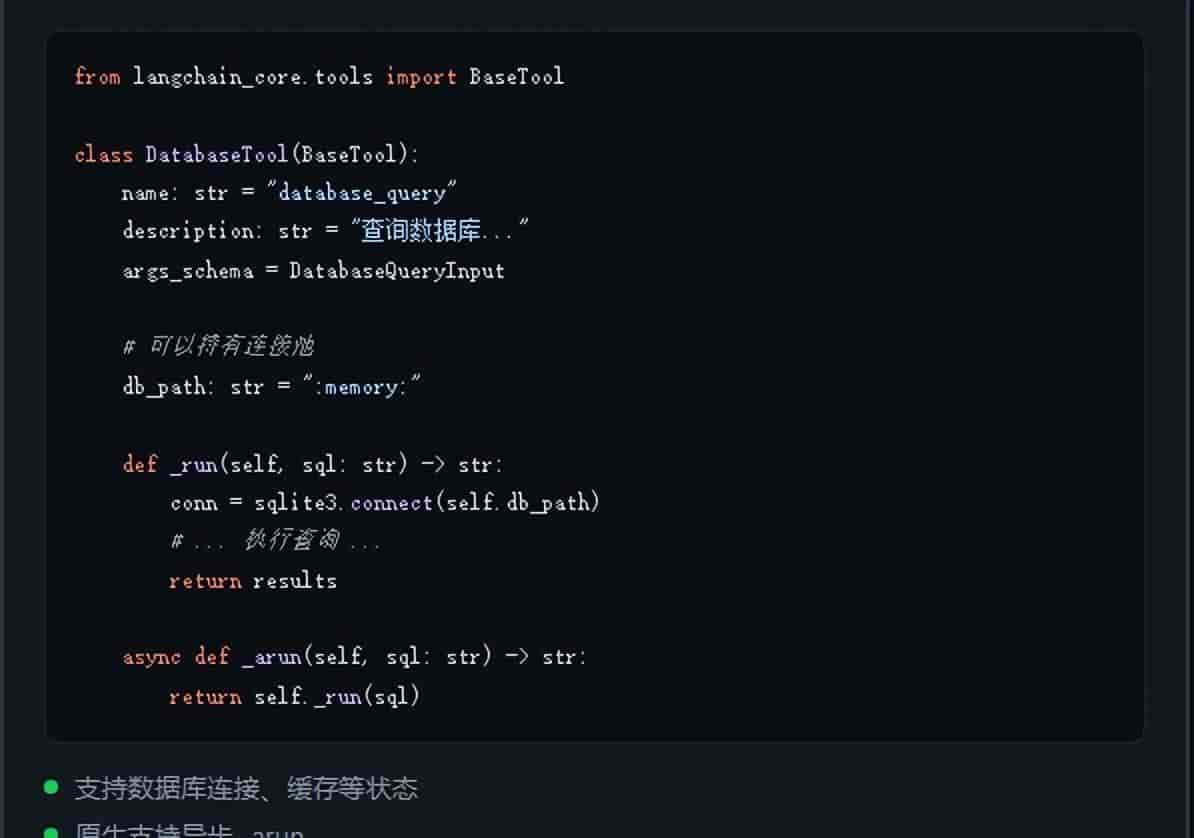
什么时候选 BaseTool:工具需要连接池、缓存、认证 Token 等需要初始化的资源时。
写法三:StructuredTool(从现有函数快速包装)
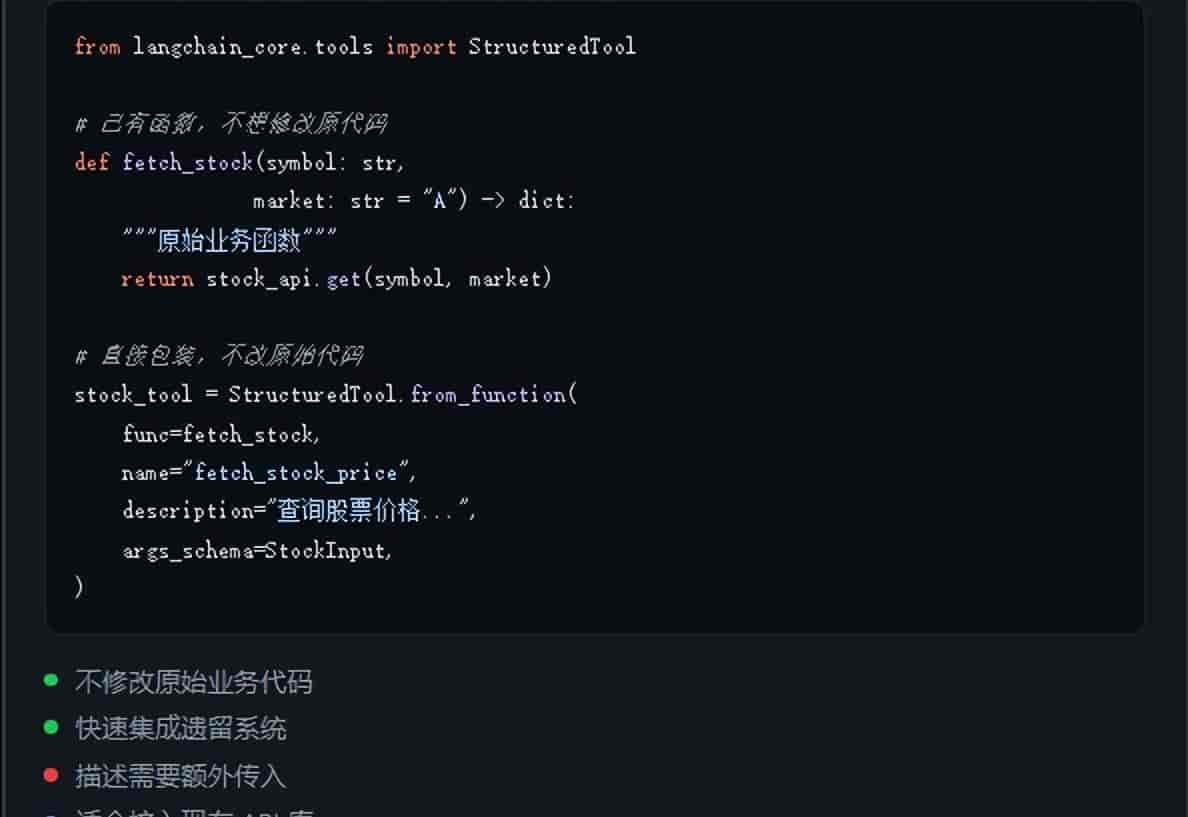
已有一个写好的函数,想直接变成工具而不改代码:
三种写法对比
选型决策树:
已有现成函数,想快速包装?
→ StructuredTool.from_function()
需要 __init__ 初始化(数据库连接/API客户端/缓存)?
→ BaseTool 子类
其他所有场景(推荐默认选择)?
→ @tool 装饰器
|
维度 |
@tool |
BaseTool |
StructuredTool |
|
代码量 |
最少 |
最多 |
中等 |
|
状态管理 |
❌ 无状态 |
✅ 支持 |
❌ 无状态 |
|
异步支持 |
✅ |
✅ |
✅ |
|
适合场景 |
简单函数调用 |
有状态服务 |
包装现有函数 |
|
推荐优先级 |
⭐⭐⭐ 首选 |
⭐⭐ 按需 |
⭐ 遗留代码 |
三、把工具挂上 Agent
三种写法写出来的工具,挂载方式完全一样:

四、代码执行沙箱:让 Agent 安全”跑代码”
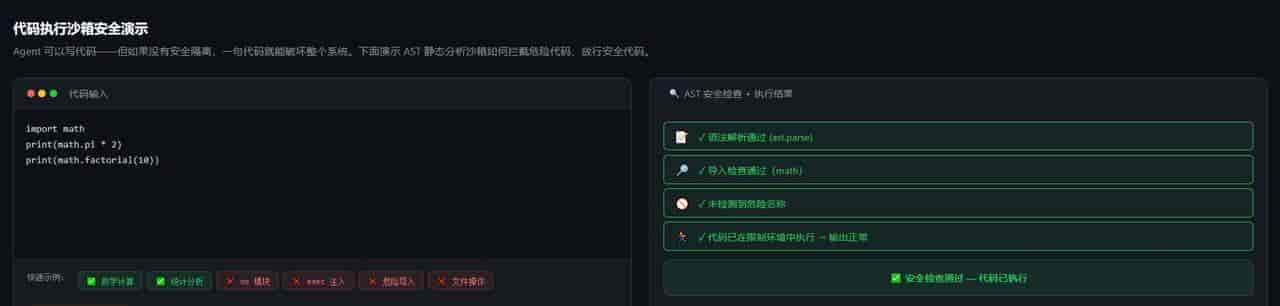
这是最容易翻车的地方。
Agent 可以写代码——但如果不做隔离,一句 os.system(“rm -rf /”) 就能把服务器清空。
危险场景演示
python
# ❌ 不要这样做!直接 eval/exec 毫无防护
@tool
def run_code_unsafe(code: str) -> str:
"""执行 Python 代码"""
exec(code) # 危险!Agent 可以通过这里执行任意系统命令
return "done"
安全方案一:受限沙箱(轻量,适合计算类)
安全方案二:Docker 沙箱(生产级,完全隔离)
两种沙箱对比
|
维度 |
受限沙箱(AST检查) |
Docker 沙箱 |
|
防护强度 |
中等(AST 可被绕过) |
极强(操作系统级隔离) |
|
启动延迟 |
< 1ms |
200ms ~ 2s |
|
依赖 |
无额外依赖 |
需要 Docker |
|
网络隔离 |
❌ 不支持 |
✅ 完全隔离 |
|
适合场景 |
内部工具、可信环境 |
公开服务、用户提交代码 |
选型提议:内部 Agent 用 AST 沙箱,对外提供代码执行服务必定要用 Docker。
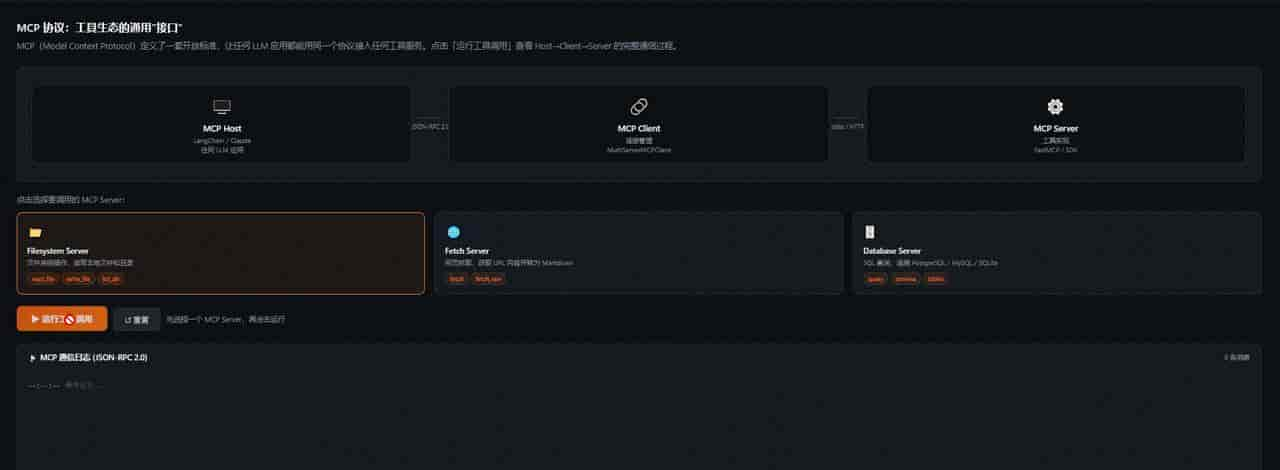
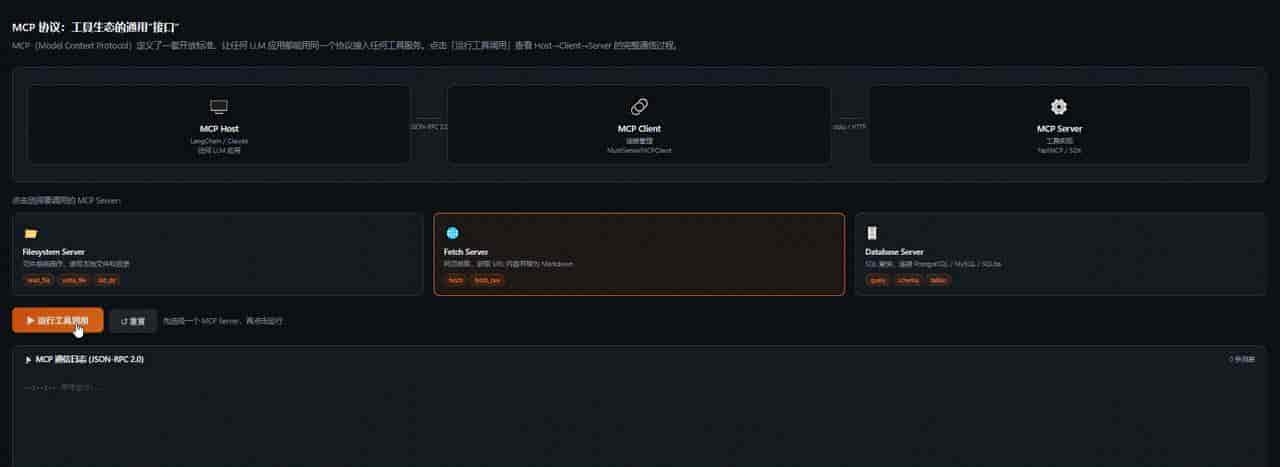
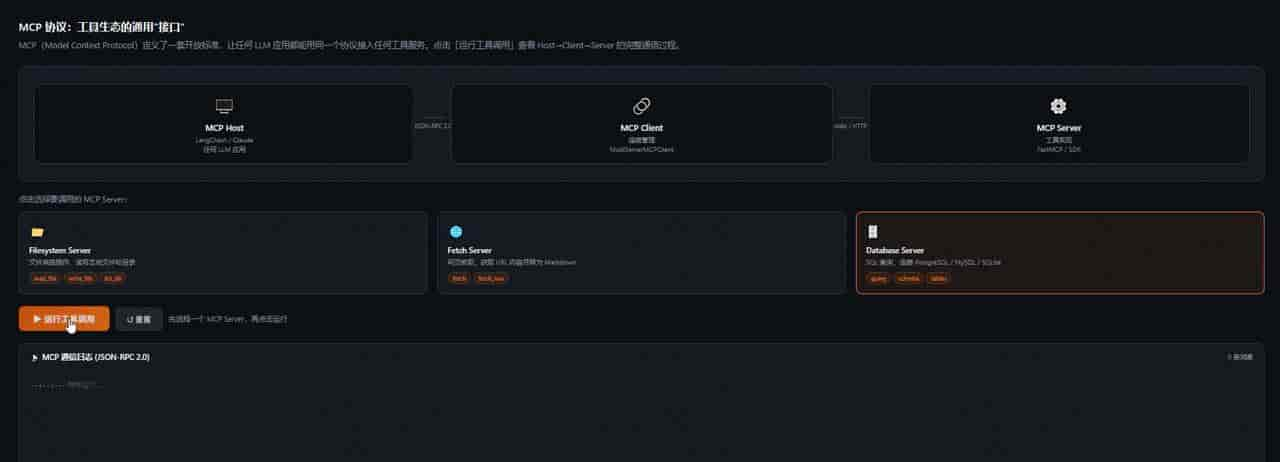
五、MCP 协议:工具生态的”USB接口”
什么是 MCP?
2024 年 11 月,Anthropic 发布了 Model Context Protocol(MCP)——一个开放的工具调用标准协议。
在 MCP 之前,每个 Agent 框架(LangChain、AutoGen、Dify……)都有自己的工具格式,工具无法跨框架复用,相当于每家电器有自己的插头,换个插座就不能用。
MCP 解决的问题就是:定义一套通用标准,任何 LLM 应用都能用同一个”插头”接入任何工具服务。
没有 MCP:
LangChain 工具 ────── 只能用于 LangChain
AutoGen 工具 ────── 只能用于 AutoGen
自研 Agent 工具 ─── 只能用于自己的项目
有了 MCP:
MCP Server(工具)
├── Claude Desktop
├── LangChain Agent
├── Cursor IDE
└── 任何支持 MCP 的应用
MCP 的架构
┌─────────────────────────────────────────────────────┐
│ MCP Host(宿主) │
│ Claude Desktop / LangChain App / Cursor / ... │
└────────────────────┬────────────────────────────────┘
│ MCP Protocol(JSON-RPC 2.0)
┌──────────┴────────────┐
▼ ▼
┌───────────────┐ ┌───────────────────┐
│ MCP Server A │ │ MCP Server B │
│ (文件系统) │ │ (数据库查询) │
└───────────────┘ └───────────────────┘
│ │
本地文件操作 PostgreSQL / MySQL
三个角色:
- MCP Host:运行 LLM 的应用,发起工具调用请求
- MCP Client:Host 内的连接层,管理与各 Server 的连接
- MCP Server:提供实际工具能力的服务,可以是本地进程也可以是远程 HTTP 服务
用 LangChain 接入 MCP Server
自己写一个 MCP Server
六、Tool Registry:大规模工具管理
当工具超过 20 个时,全部注册给一个 Agent 会导致 LLM 困惑(上下文太长、选择太多)。
解决方案:动态工具注册中心
python
七、踩坑提示
坑 1:Tool docstring 写得太模糊,LLM 乱调用
python
# ❌ 坏例子:描述不清楚
@tool
def query_data(input: str) -> str:
"""查询数据"""
...
# ✅ 好例子:明确说明输入格式、返回内容、适用场景
@tool
def query_order_by_id(order_id: str) -> str:
"""
根据订单号查询订单详情,返回状态、金额、物流信息。
只接受格式为 ORD-XXXXXXXX 的订单号(8位数字)。
如果需要按用户查所有订单,请用 query_orders_by_user 工具。
Args:
order_id: 订单号,例如 ORD-00012345
"""
...
坑 2:工具抛异常导致整个 Agent 崩溃
工具函数永远不要让异常向上传播,必定要在内部 try/except 处理并返回错误字符串——LLM 能理解错误信息并换一种方式重试:
python
@tool
def safe_http_get(url: str) -> str:
"""发起 HTTP GET 请求获取网页内容"""
try:
response = httpx.get(url, timeout=10)
response.raise_for_status()
return response.text[:3000] # 截断避免 Token 爆炸
except httpx.TimeoutException:
return "请求超时(10s),请稍后重试或换一个 URL"
except httpx.HTTPStatusError as e:
return f"HTTP 错误 {e.response.status_code}: {e.response.reason_phrase}"
except Exception as e:
return f"请求失败: {type(e).__name__}: {e}"
坑 3:没有限制 LLM 输出长度导致工具参数被截断
Agent 调用工具时,参数是 LLM 生成的 JSON。如果 LLM 生成的代码很长,可能被 max_tokens 截断,导致 JSON 格式损坏,工具调用失败。
解决方案:设置足够大的 max_completion_tokens,以及在工具调用节点前加一个检查:
python
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(
model="meta/llama-3.1-70b-instruct",
max_completion_tokens=4096, # 工具调用时需要更大的 token 空间
)
坑 4:MCP Server 进程没有正确关闭
在 Python 里 MultiServerMCPClient 必须用 async with 上下文管理器,否则子进程(MCP Server)会在程序退出后变成僵尸进程:
python
# ✅ 正确:用 async with 确保清理
async with MultiServerMCPClient({...}) as client:
tools = client.get_tools()
# ... 使用 tools
# ❌ 错误:直接实例化,进程泄漏
client = MultiServerMCPClient({...})
tools = await client.__aenter__()
# 如果这里抛异常,MCP Server 子进程不会被关闭
八、本篇小结
工具层是 Agent 能力的天花板。三个核心要点:
- 三种写法各有适用场景:80% 情况用 @tool 装饰器,需要状态管理用 BaseTool,包装现有代码用 StructuredTool
- 沙箱安全不可省略:开发环境至少做 AST 检查,生产环境代码执行必须上 Docker 隔离
- MCP 协议是趋势:工具一次写成 MCP Server,可以被任何框架复用——投资回报最高
- 欢迎评论区讨论
本篇配套演示:
- 三种写法对比:三列并排,@tool / BaseTool / StructuredTool 代码结构动态对比,点击高亮对应代码块

- 沙箱安全演示:输入不同代码片段,实时展示 AST 检查通过/拦截的过程,包含攻击样本演示
- MCP 协议流程:可视化展示 Host → Client → Server 的 JSON-RPC 通信过程,逐帧展示一次工具调用的完整报文
本地文件
抓取网页数据
连接数据库
下篇预告:《记忆系统 — 让 Agent 真正”记住”你》
你的 Agent 是不是每次对话都”失忆”?下一篇拆解四种记忆架构(短期/长期/情节/语义),以及如何用 Redis + 向量库打造永不遗忘的记忆系统。
参考资料:
- LangChain Tools 官方文档
- MCP 官方规范
- langchain-mcp-adapters
- FastMCP — 快速构建 MCP Server
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










