
全文约1800字,系统梳理GPT-Image 2时代的能力边界、工作流选择与创意心法
GPT-Image 2时代,
真正的竞争根本不在模型
过去一周,我把市面上所有关于GPT-Image 2的内容全跑了一遍。
模型会越来越强,这个没有悬念。真正拉开差距的,是你知道怎么用、怎么改、怎么固化。
今天把这三篇串起来,给你一套完整的GPT-Image 2使用地图。
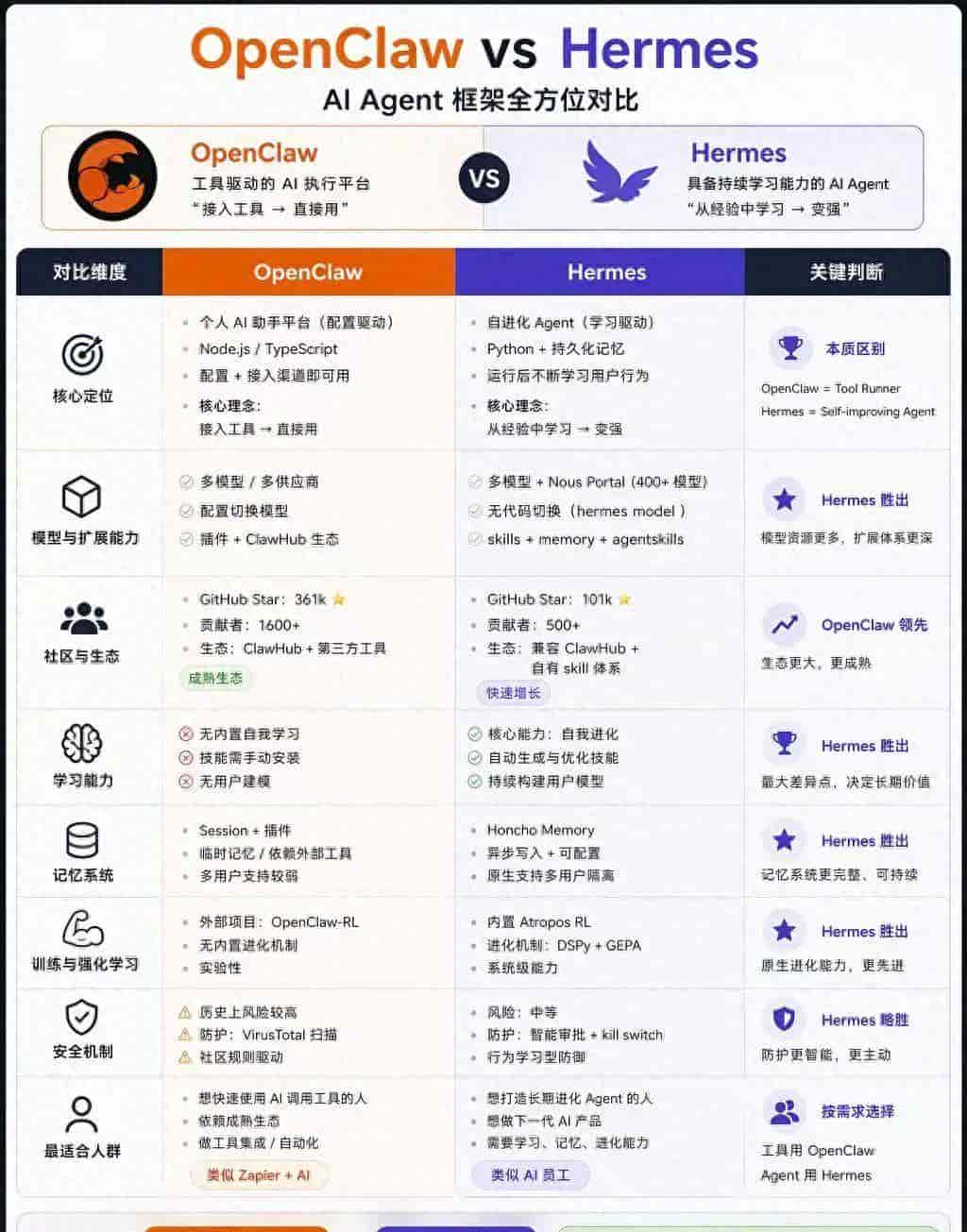
01 · 模型到底强在哪
先说能力,别跳过这节——后面所有技巧都是建立在这个能力边界上的。
GPT-Image 2的核心跃升有两点:
第一,中文终于丝滑了。
之前所有AI生图最大的坑就是中文乱码、排版错位。GPT-Image 2一次性解决了这个问题——字体清晰、语义准确、版式可控。这是它封神的核心缘由之一。
第二,细节还原度前所未有。
光影层次、材质质感、情绪氛围——这些过去需要专业修图才能达到的效果,目前一句话就能生成。
免费用户每日有限额(官方说2-3张,实际有人测到12张仍可用,灰度测试)。够用,但别浪费在试错上——把技巧学到位,每一张都用在刀刃上。
02 · 为什么ChatGPT不适合做设计
模型能力够了,但工具形态有问题。
对话模式适合探索,不适合生产——每改一个细节都要重新输一遍提示词,不可控,效率低,产出质量飘忽。
真正搞设计的人都知道:作品是改出来的,不是一次生成的。
你要的不是”生成一次就满意”,而是”元素级的精修能力”。ChatGPT给不了你这个。
这就是Lovart这类工具存在的意义——接入了GPT-Image 2的模型能力,补上了工作流控制的缺口。
03 · Lovart把工作流补齐了
Lovart(lovart.ai)是目前把GPT-Image 2用到生产环节最顺的工具,缘由就一个——它解决的不是生图的问题,是工作流控制的问题。
品牌套件:一次定义,反复调用
字体、颜色、风格定义成一套品牌套件,后来每次生成直接@调用,不用每次重述。设计师定义好的视觉规范,直接变成可复用的资产。
元素级编辑:直接在图上改,不破坏已有元素
文字、人物大小、配色细节——不用重输提示词,直接选中图片提出修改需求,准确度比提示词高十倍。这才是设计生产的真实需求。
Skill固化:把工作流存成模板
封面图、海报、产品图……固定类型的工作流可以存为Skill。下次要用,直接从模板调,不用重新设计。
三个真实工作流:产品线框图→高保真设计稿、品牌海报→素材导出、零件拆解→整车还原→电商商品图——全流程不需要设计师参与。
04 · 创意才是真正的壁垒
模型能力到位了,工作流也打通了,最后一层竞争在创意。
AI能画出任何东西,但画什么、怎么组合、用在什么场景——这些判断永远需要人来做。
最好的证明就是那些”古典人物×现代场景”的反差创意——黛玉卖情绪疗愈套装、悟空卖祥云、鲁智深卖梁山入伙码。模型能还原细节,但这个脑洞,是人想出来的。
提示词五层框架(直接拿去用)
【Image Type】图像类型 + 比例 + 分辨率 + 使用场景 【Subject】主体 + 年龄 + 表情 + 动作 + 服装 + 道具 【Scene】背景环境 + 空间结构 + 时间 + 光线 【Layout/UI】信息图结构 / 海报层级 / 排版逻辑 【Style】艺术风格 + 色彩系统 + 材质语言 + 情绪氛围 【Typography】字体风格要求(极重大) 【Negative】明确禁止项 还有一个偷懒技巧:直接把参考图扔给模型,说”请参考这个样式,帮我做一个xxx”——模型直接复制那张图的提示词逻辑。
参考网站:PromptHero(工程师级)/ Lexica(训练级)/ Krea(设计师风格)/ Lovart(电商专项)。

05 · 工具组合才是你的护城河
设计师不会被取代,但只会执行、不会判断的画图师会。
真正的壁垒不是你用了什么AI工具,而是你知道怎么组合工具、怎么固化工作流、怎么让AI的产出真正可控。

GPT-Image 2负责提升生成质量。Lovart负责搞定生成后怎么用、怎么改。你的创意负责决定画什么、怎么组合。
工具会越来越强
但真正拉开差距的,永远是使用工具的人
GPT-Image 2 · Lovart · 提示词框架 · 品牌套件 · Skill固化
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










