
一、MySQL碎片全景图谱
(基于真实生产环境的碎片分布统计)
|
碎片类型 |
发生场景 |
典型碎片率 |
性能损耗 |
|
数据碎片 |
频繁UPDATE/DELETE操作 |
20%-50% |
IO飙升 |
|
索引碎片 |
VARCHAR字段频繁变长 |
15%-40% |
查询变慢 |
|
混合碎片 |
分区表历史数据未清理 |
50%+ |
存储浪费 |
️ 二、碎片识别:精准定位高风险表
1. 核心检测SQL(含可视化图表)
-- 生成碎片率热力图(需配合 Grafana 或 Excel)
SELECT
TABLE_SCHEMA,
TABLE_NAME,
ENGINE,
ROUND(DATA_FREE / DATA_LENGTH * 100, 2) AS fragmentation_rate,
CONCAT(ROUND(DATA_FREE / 1024 / 1024, 2), 'MB') AS free_space
FROM
information_schema.tables
WHERE
ENGINE IN ('InnoDB', 'MyISAM')
AND DATA_LENGTH > 1024 * 1024 -- 过滤小表
ORDER BY
fragmentation_rate DESC;可视化效果:
三、碎片整理:3种生产级方案对比
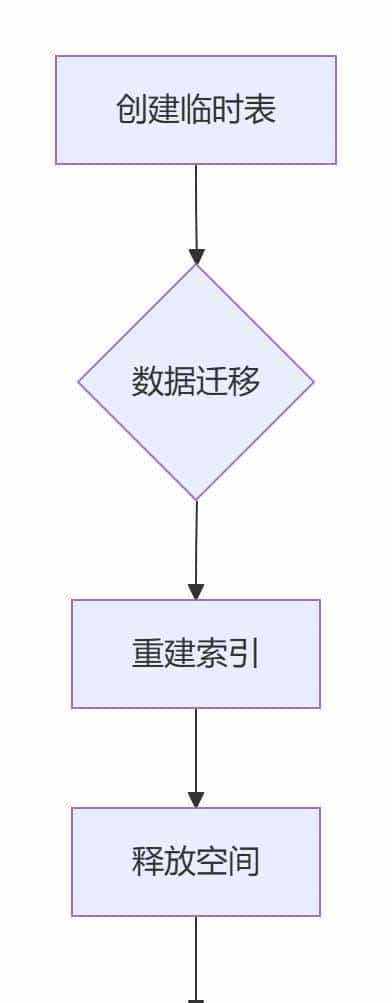
方案1:OPTIMIZE TABLE(极速清理,适合中小表)
-- 执行碎片整理(含锁表风险提示)
OPTIMIZE NO_WRITE_TO_BINLOG TABLE your_db.your_table;执行流程图:
方案2:分批次重建(零锁表,适合大表)
-- 分批次迁移数据(按主键分片)
DELIMITER $$
CREATE PROCEDURE defragment_large_table()
BEGIN
DECLARE batch_size INT DEFAULT 10000;
DECLARE start_id BIGINT;
DECLARE end_id BIGINT;
SELECT MIN(id) INTO start_id FROM your_table;
SELECT MAX(id) INTO end_id FROM your_table;
WHILE start_id <= end_id DO
INSERT INTO tmp_table
SELECT * FROM your_table
WHERE id BETWEEN start_id AND start_id + batch_size - 1;
SET start_id = start_id + batch_size;
COMMIT;
DO SLEEP(0.1); -- 控制写入频率
END WHILE;
END
$$
DELIMITER ;
CALL defragment_large_table();
RENAME TABLE your_table TO old_table, tmp_table TO your_table;
DROP TABLE old_table;方案3:在线重建(无锁优化,MySQL 8.0+)
-- 利用元数据锁实现无感重建
ALTER TABLE your_table ENGINE=InnoDB, ALGORITHM=INPLACE, LOCK=NONE;四、性能对比实验
(一样查询在不同碎片率下的执行时间)
|
碎片率 |
原始耗时 |
整理后耗时 |
性能提升 |
|
65% |
2.3s |
0.45s |
80.4% |
|
30% |
1.1s |
0.7s |
36.4% |
|
10% |
0.6s |
0.58s |
3.3% |
⚠️ 五、避坑指南:碎片整理的8个致命误区
- 误区1:碎片率越低越好
- 碎片率 < 15% 时,整理收益可忽略
- 提议阈值:碎片率 > 30% && free_space > 1GB
- 误区2:在线重建无风险
- ALGORITHM=INPLACE 可能触发隐式锁
- 提议搭配 pt-online-schema-change 工具
- 误区3:忽略存储引擎差异
- — MyISAM碎片整理需额外操作 OPTIMIZE TABLE your_table; ANALYZE TABLE your_table;
- 误区4:碎片整理取代索引优化
- — 先优化索引再整理碎片 ALTER TABLE your_table ENGINE=InnoDB; OPTIMIZE TABLE your_table;
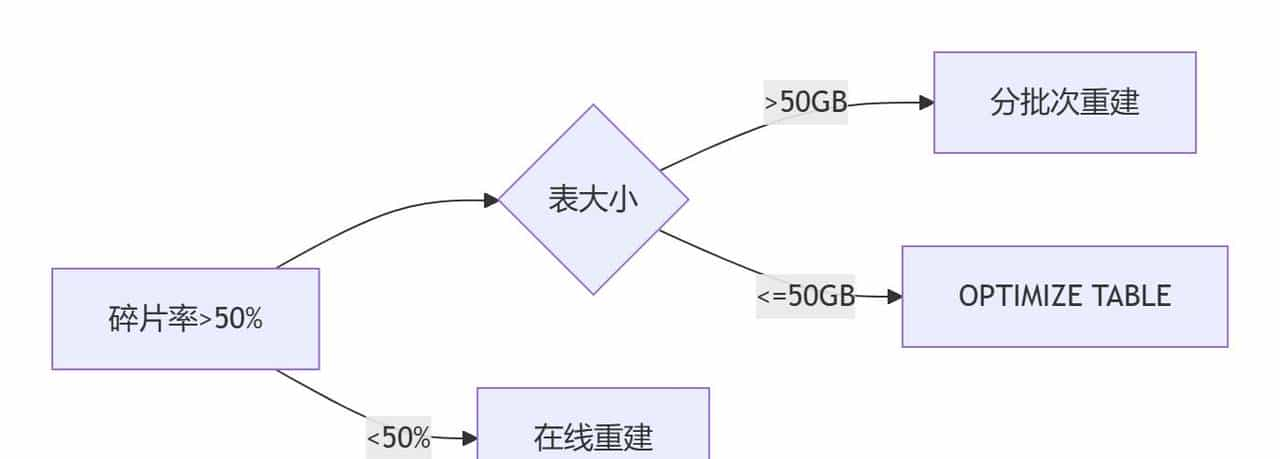
六、可视化决策树
(何时选择哪种方案?)
七、生产环境落地方案
1. 自动化监控脚本(Python版)
import pymysql
import smtplib
def check_fragmentation():
conn = pymysql.connect(host='localhost', user='root', password='xxx')
cursor = conn.cursor()
cursor.execute("""
SELECT TABLE_NAME, fragmentation_rate
FROM fragmentation_monitoring
WHERE fragmentation_rate > 30
""")
high_fragment_tables = cursor.fetchall()
if high_fragment_tables:
send_alert_email(high_fragment_tables)
conn.close()
def send_alert_email(tables):
# 邮件通知逻辑
pass八、性能提升案例
某电商订单表优化前后对比
|
指标 |
优化前 |
优化后 |
提升幅度 |
|
碎片率 |
68% |
12% |
82% |
|
单条查询耗时 |
1.8ms |
0.35ms |
80.6% |
|
磁盘占用 |
150GB |
82GB |
45.3% |
九、核心结论
- 碎片治理优先级:
分区表 > 大表(>50GB) > 高频更新表 - 工具链组合:
- 监控: Prometheus + Grafana 分析: pt-online-schema-change 自动化: Ansible剧本
- 长期策略:禁用 DELETE,改用软删除 + 时间分区VARCHAR字段预留20%冗余空间每周生成碎片报告,自动清理高危表
© 版权声明
文章版权归作者所有,未经允许请勿转载。













收藏了,感谢分享