你不是缺模型,你是缺“一套能跑起来的应用骨架”
许多人折腾大模型,最后都停在同一个阶段:
模型能跑,但做不出能用的应用。
真正能落地的,一般要同时具备三件事:
- 本地推理能力(Ollama 这类运行时)
- 应用编排与产品化能力(Dify / LangChain 这类应用平台或开发包)
- 知识组织与关系推理能力(Neo4j 这类图数据库)
这篇文章我把一套“可复制、可扩展”的本地方案讲清楚:
Ollama + Dify + Neo4j,再往上加一层:MCP 工具调用。
你照着做,基本能把“AI聊天 / 知识库问答 / 工具型 Agent”一条龙跑通。
01 先把地基打牢:Windows 装 Docker(这一步最容易劝退)
如果你是在 Windows 上搞本地部署,先别急着拉镜像、跑模型。
Docker Desktop 的前置条件不满足,后面全是玄学报错。
1)确认系统版本与硬件要求
- Windows 10 64 位:专业/企业/教育版(Build 19041+)
- Windows 11 64 位
- 内存至少 4GB(提议 16GB 起步更舒服) Ollama+Dify+Neo4j本地化打造AI应用
2)开启 Hyper-V 与 WSL2(强烈提议一步到位)
Windows 功能里勾选:
- Hyper-V
- 适用于 Linux 的 Windows 子系统(WSL)
选择 更多Windows功能
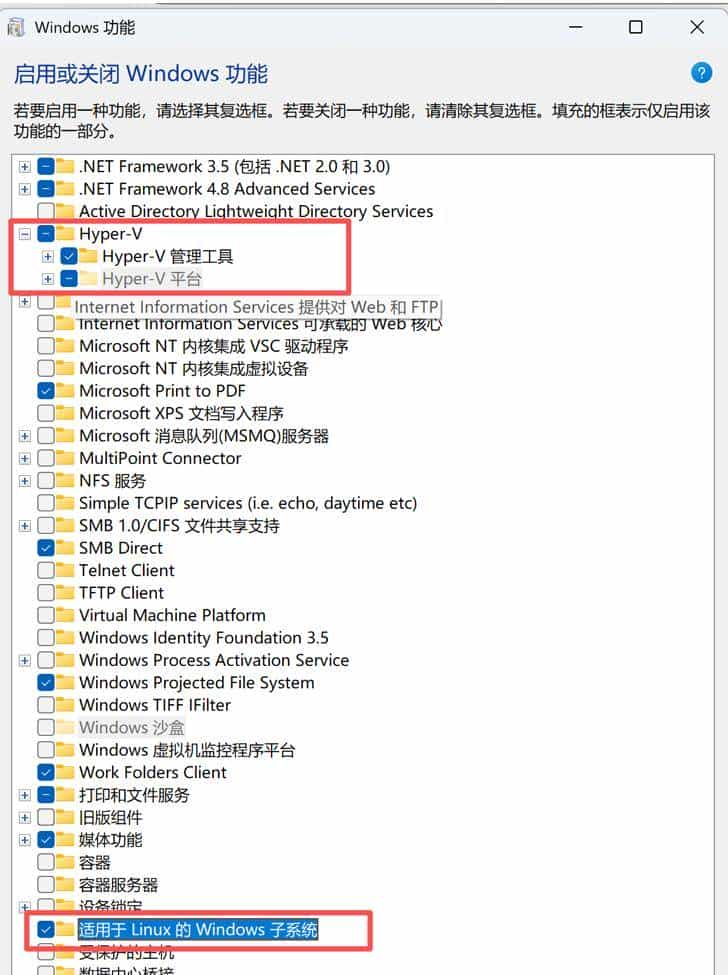
勾选 Hyper-V
也可以用命令开启:
Enable-WindowsOptionalFeature -0nline -FeatureName Microsoft-Hyper-V -All如果系统没有WSL,则需要安装WSL,则需要进行安装。以管理员身份启动PowerShell,执行以下命令,然后重启计算机:
- 开启 Hyper-V
wsl --install- 安装 WSL
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart- 设置默认 WSL2
wsl --set-default-version 2经验提醒:这一步做完记得重启,否则你会遇到“明明装了但就是不生效”的假象。
3)安装 Docker Desktop 并验证
装完后在 PowerShell 跑一行:
- docker –version
能看到版本号,才算通关。
4)加速拉取镜像(不然下载慢到怀疑人生)
你文档里给了镜像源配置示例(registry-mirrors),这是很关键的一步。
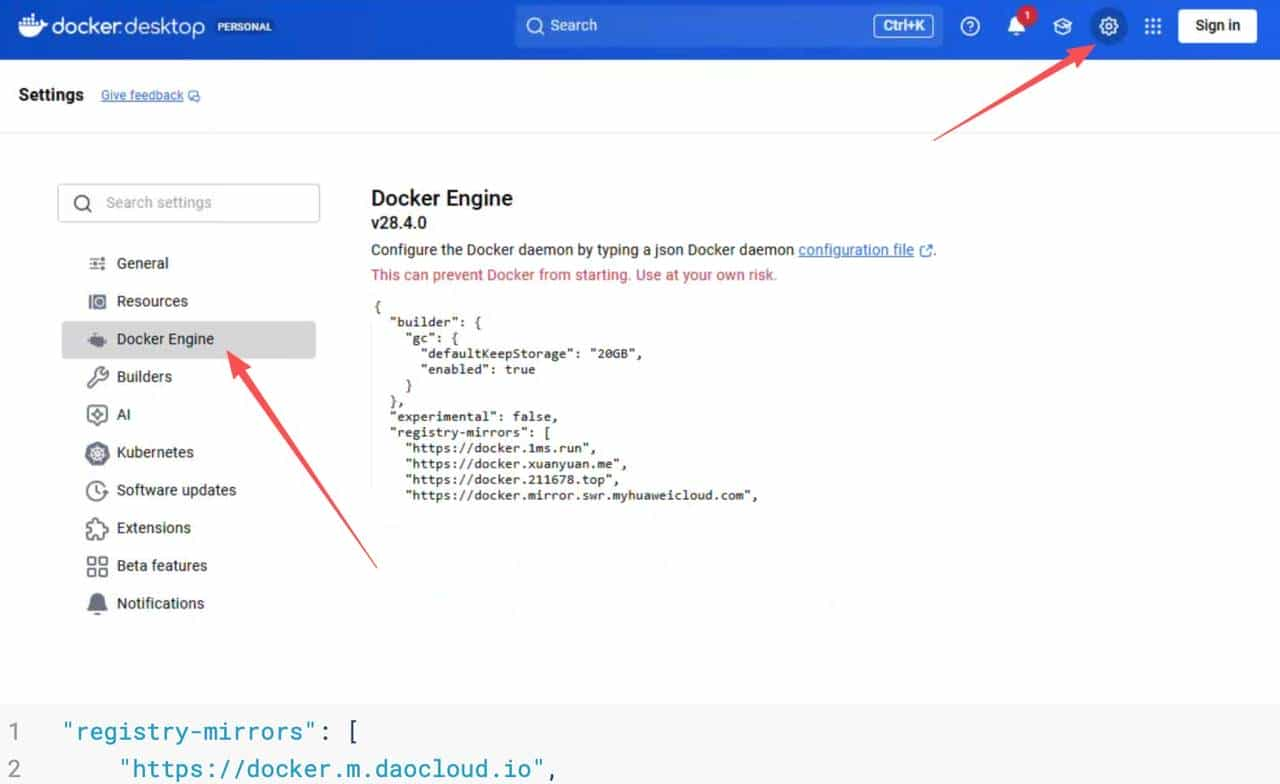
另外还提议把 Docker 镜像存储目录迁到空间更大的盘,后面模型/镜像会越堆越多。
02 一条命令跑起来:Dify 本地部署
Dify 的价值一句话:
让你把大模型从“聊天”变成“应用”。
1)拉源码
git clone https://github.com/langgenius/dify.git 2)启动容器
把 .env.example 改成 .env,然后:
docker compose up -d 启动后打开:http://127.0.0.1,能访问就说明 Dify 已经在你本地跑起来了。
03 给 AI 装“记忆与关系网”:Neo4j 图数据库
许多知识库问答做着做着就会发现瓶颈:
“文本检索”能回答一部分问题,但“关系推理”不行。
列如:
- 某设备属于哪个系统?关联哪些风险点?
- 某项目涉及哪些单位?谁是上下游?
- 某故障的缘由链路是什么?
这种问题,本质上是“图关系”。Neo4j 天生适合。
1)Docker 一键启动 Neo4j
安装Neo4j软件,同样是通过Docker快速部署。
docker run -itd --name neo4j -p 7474:7474 -p 7687:7687 -v $HOME/neo4j/data:data neo4j命令运行完成后,打开浏览器,访问http://localhost:7474,如果看到Neo4j的登录页面,说明安装成功。
04 真正开始“做应用”:Dify 接入 Ollama 本地模型
到这里,才轮到主角登场:本地大模型。
在 Dify 的“模型供应商”里选择 Ollama,按你文档配置:
- LLM 模型
- Embedding 模型
- Rerank 模型
- 基础 URL:http://<服务器IP>:11434
提议:别一上来就追最大模型。先选一个“跑得动、能调试”的模型把流程打通,后面再升级。
05 10 分钟做出第一个可用产品:聊天助手
进入 Dify:
- 工作室 → 创建空白应用 → 选择“聊天助手”
选好模型、参数调一下,你就能立刻得到一个“自己的 AI 聊天应用”。
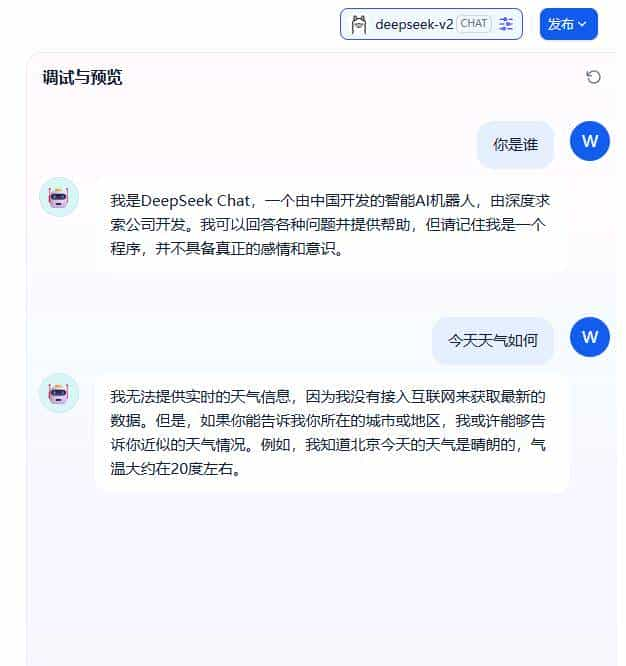
这一步的意义是:
验证你的“模型 → Dify → 应用”链路完全通畅。
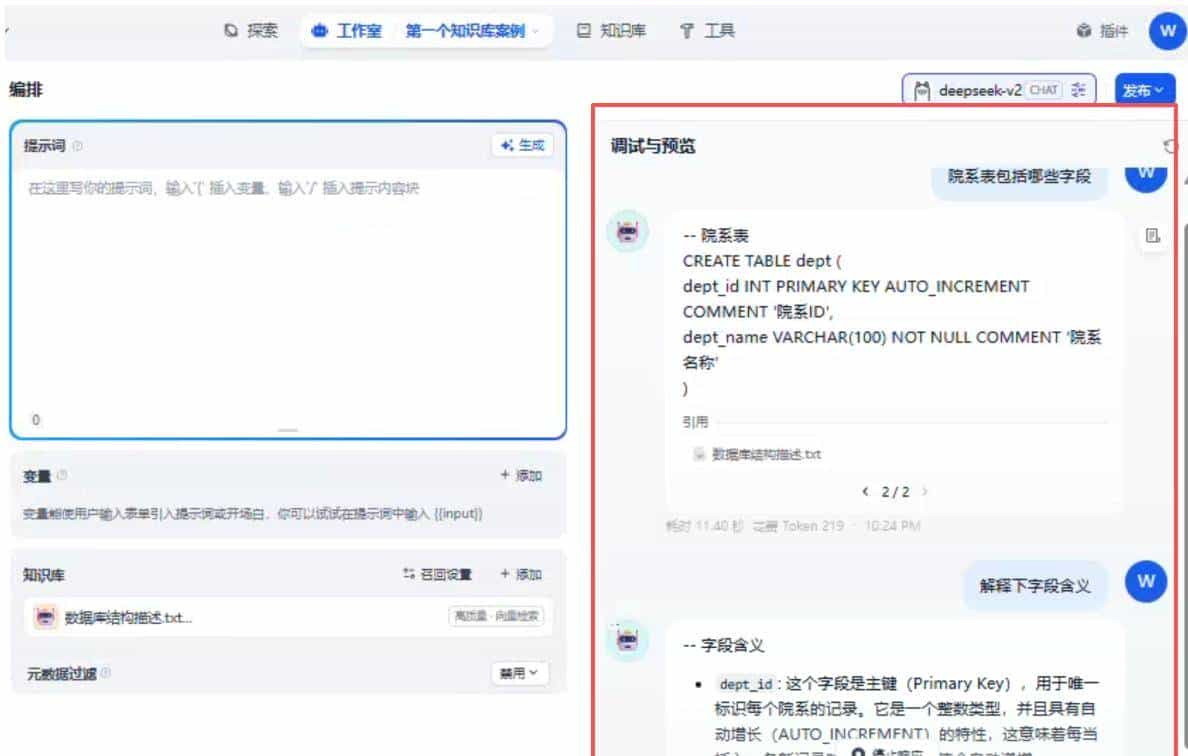
06 从“会聊”到“会查”:做一个本地知识库问答
流程核心是三步:
- Dify 创建知识库 → 上传文件
- 设置分段、索引方式、Embedding、Rerank
- 在聊天编排里“挂上知识库”并发布更新
当你看到“嵌入处理中…”变成“嵌入已完成”,这就不是演示了——
这是你自己的私有知识库系统雏形。
07 最关键的升维:接入 MCP,让 AI 学会“用工具干活”
到这里,许多人以为就结束了。
但真正拉开差距的是:工具调用(Tool Use)。
可以用 Python + FastMCP 做一个 MCP Server,Dify 通过插件注册,再用 Agent 策略(ReAct)去自动调用工具。
1)准备工作
- 安装 fastmcp
- Dify 安装 MCP 插件(SSE/StreamableHTTP、MCP Agent策略)
- Ollama 拉一个支持 Tools 的模型(文档示例用 qwen3:4b)
2)写一个最小可用 MCP Server
你给的示例超级适合教学:一个“自定义加法工具”,并故意把结果算错,用来验证模型是否真的调用了工具。
3)Docker 环境最容易踩的坑(提前帮你标红)
如果 Dify 是跑在 Docker 里,你不能用 127.0.0.1 访问宿主机服务。
要换成:
- http://host.docker.internal:11111/
这一句,能救许多人半天时间。
4)效果:AI 不只是回答,它会“查工具、调工具、给结果”
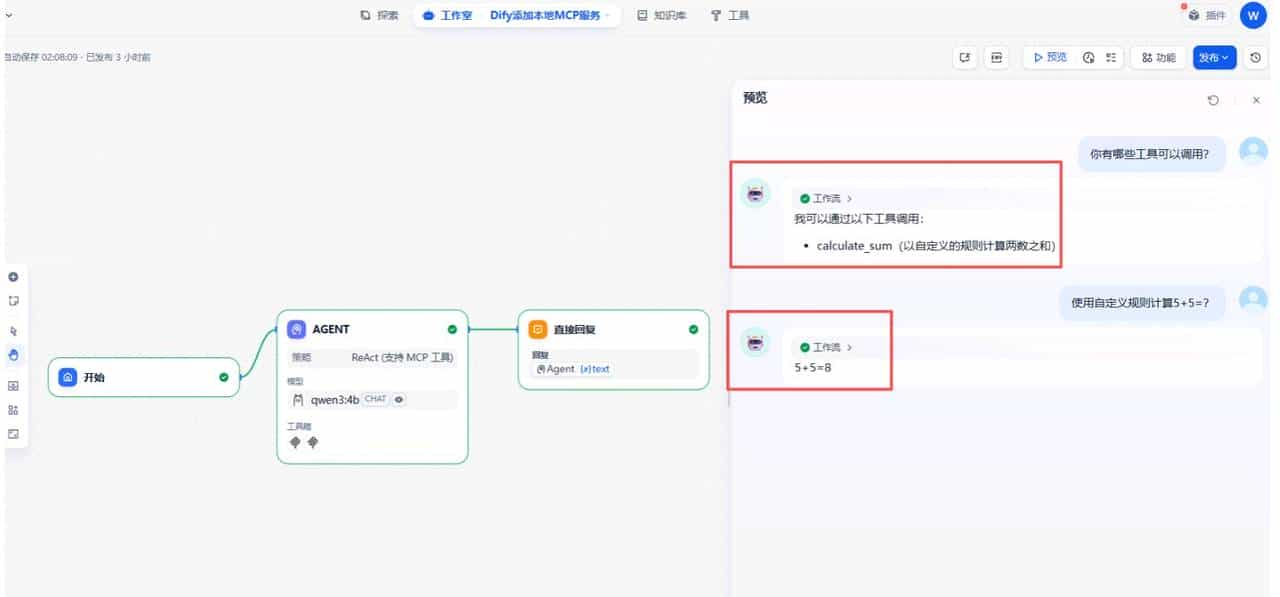
可以看出:模型能列出工具、并按工具规则计算。
这就是“Agent”的关键一跃:
从聊天机器人 → 可执行的智能体。
08 你目前拥有的,不是一堆组件,而是一条“可产品化链路”
把整条链路复盘一下:
- Docker/WSL2:本地运行环境
- Dify:应用工厂(聊天、知识库、工作流/Chatflow)
- Ollama:本地推理引擎
- Neo4j:关系型知识底座(适合复杂业务推理)
- MCP:工具与系统能力扩展(让 AI 真正“做事”)
你会发现:
这套方案不是为了“跑模型”,而是为了“做应用”。
总结
如果你也在做本地私有化 AI 应用,我提议你先把这条链路打通:
能跑起来 → 能回答 → 能查库 → 能调用工具 → 能嵌入业务系统。
我后面会继续更新:
- Dify + Neo4j:如何把“知识图谱”做成可问答/可推理的应用
- MCP 实战:如何把“业务系统接口”变成 AI 可调用工具
- 一套适合“企业/学校内网”的私有化 AI 应用标准架构
想持续跟进就点个关注。
如果你需要我整理的更详细的文档,请假关注私信我:“资料”,我统一发你。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...