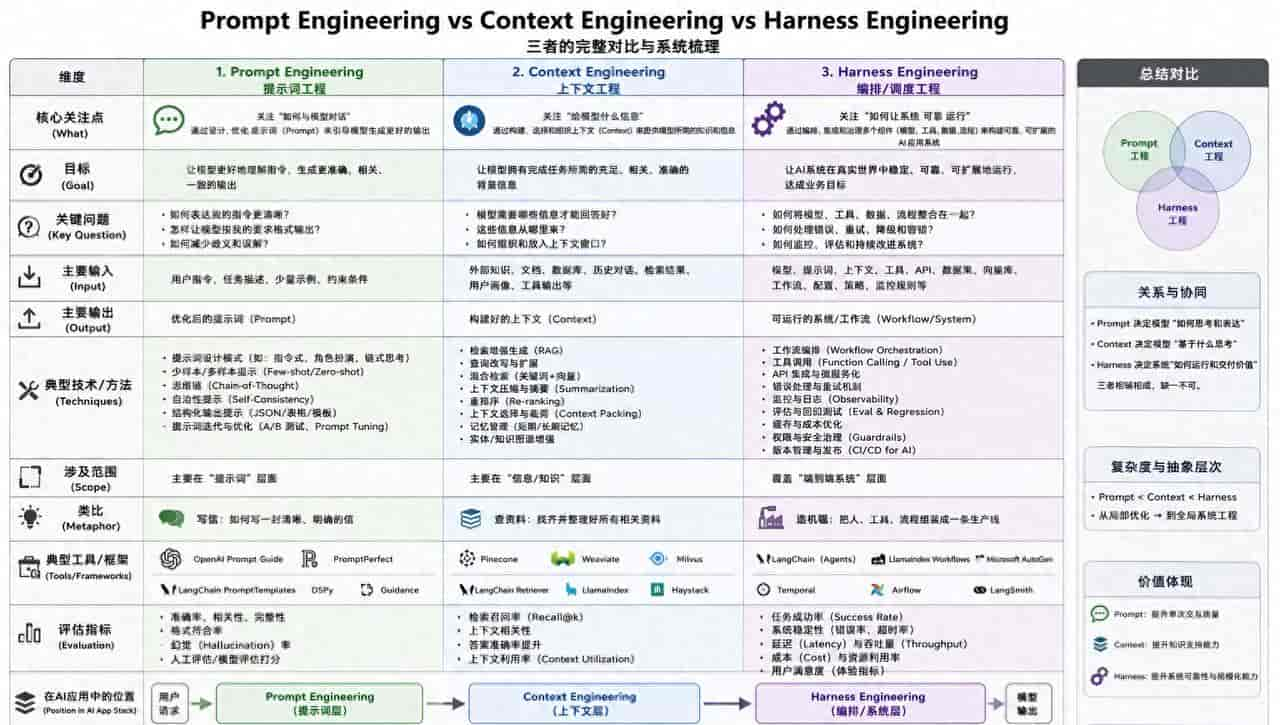
原始的Transformer有编码器(理解)和解码器(生成),像翻译官的两部分。但GPT系列发现,对于生成式语言模型,一个庞大的、堆叠的解码器就足够了。这是为什么?
本文是《从零到精通大模型》系列第11章,深入解析GPT架构的核心原理:为什么简单的”预测下一个词”任务能产生强大的智能?涵盖掩码自注意力、Decoder-only架构、规模定律等关键技术。
一、一个”反直觉”的发现
2018年,当OpenAI发布GPT-1时,我第一反应是:“这太简单了吧?”
当时的NLP领域,大家都在追求更复杂的架构:
BERT:双向Transformer编码器,擅长理解
Transformer:完整的编码器-解码器,擅长翻译
各种花式变体:多任务学习、多模态融合…
而GPT-1说:“我只要解码器,而且只做一件事——预测下一个词。”
我当时想:“这能行吗?预测下一个词,不就是完形填空吗?这算什么智能?”
但我错了,而且错得很彻底。
二、回顾:Transformer的双雄
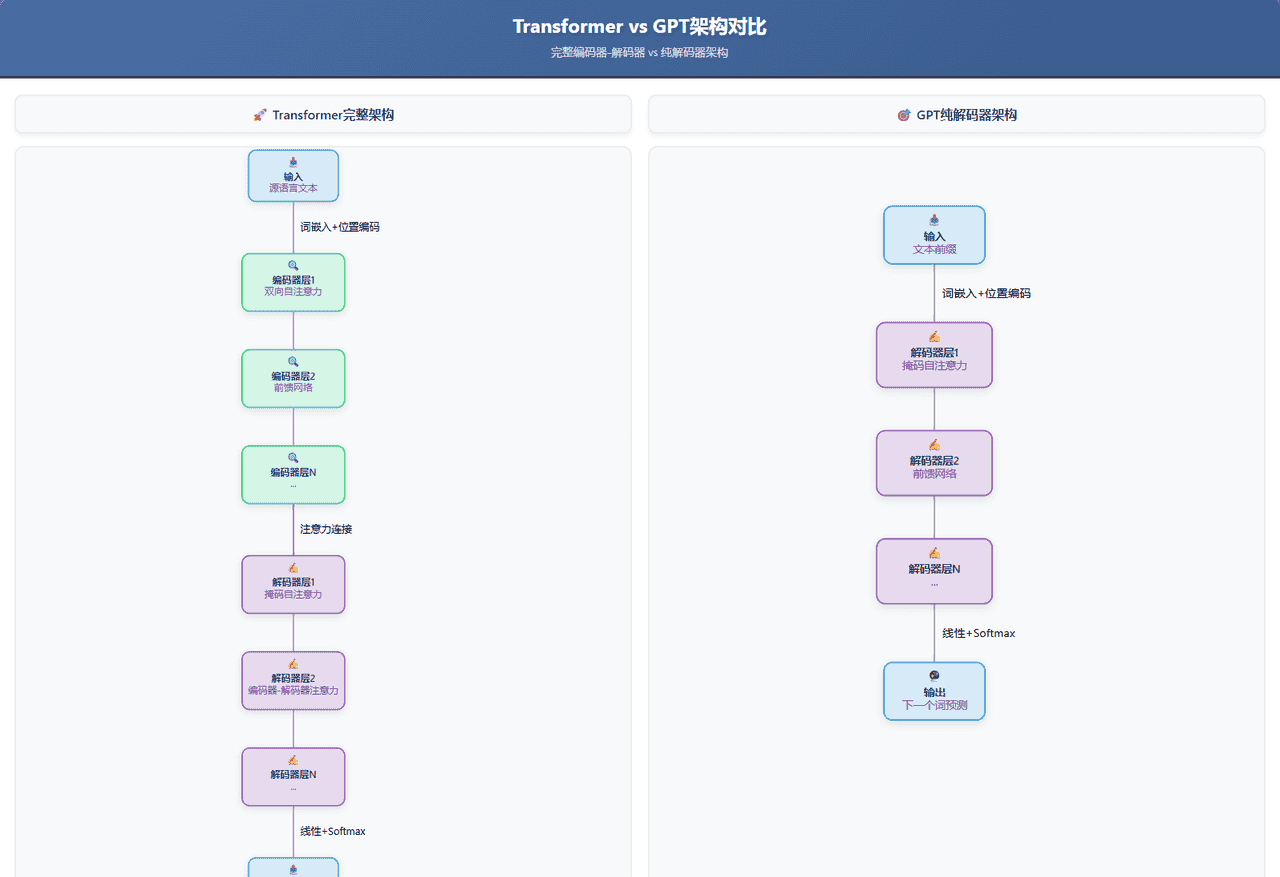
要理解GPT的选择,先回顾一下Transformer的两种主要变体:
1. BERT:双向理解专家
BERT(Bidirectional Encoder Representations from Transformers)使用编码器,能看到整个句子的所有词(双向)。
擅长:
文本分类(情感分析、主题分类)
命名实体识别(找出人名、地名)
问答(在上下文中找答案)
完形填空(Masked Language Modeling)
比喻:像开卷考试,可以随时翻看全文。
2. GPT:单向生成专家
GPT(Generative Pre-trained Transformer)使用解码器,只能看到左侧的词(单向)。
擅长:
文本生成(写文章、写代码)
对话(聊天机器人)
续写(给开头,写后续)
自回归语言建模(预测下一个词)
比喻:像闭卷作文,只能基于已写的内容继续写。
三、GPT的关键选择:掩码自注意力
GPT的解码器不是普通的解码器,它使用了掩码自注意力(Masked Self-Attention)。
什么是掩码自注意力?
在普通的自注意力中,每个词能看到所有词(包括后面的词)。
在掩码自注意力中,每个词只能看到它左边的词(包括自己)。
技术实现:在计算注意力分数时,把后面的词”遮住”(设为负无穷),这样softmax后权重就为0。
为什么需要掩码?
因为GPT的任务是预测下一个词。
如果让模型看到后面的词,那就变成”作弊”了——它已经知道答案了。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...