
前文分析了 MiMo-V2-Flash 的模型结构和核心亮点,并对相应速度进行了测试。
本文将从更贴合实际的角度,看看 Claude Code 配上 MiMo-V2-Flash 之后,实际的效果如何?
前文错误修正
首先更正前文中存在的一处错误:MiMo-V2-Flash 是 Encoder-Decoder 架构。
之前看到它的网络结构图(如下图所示),和 Transformer 很像啊,自然想到左侧是 Encoder,右侧是 Decoder。
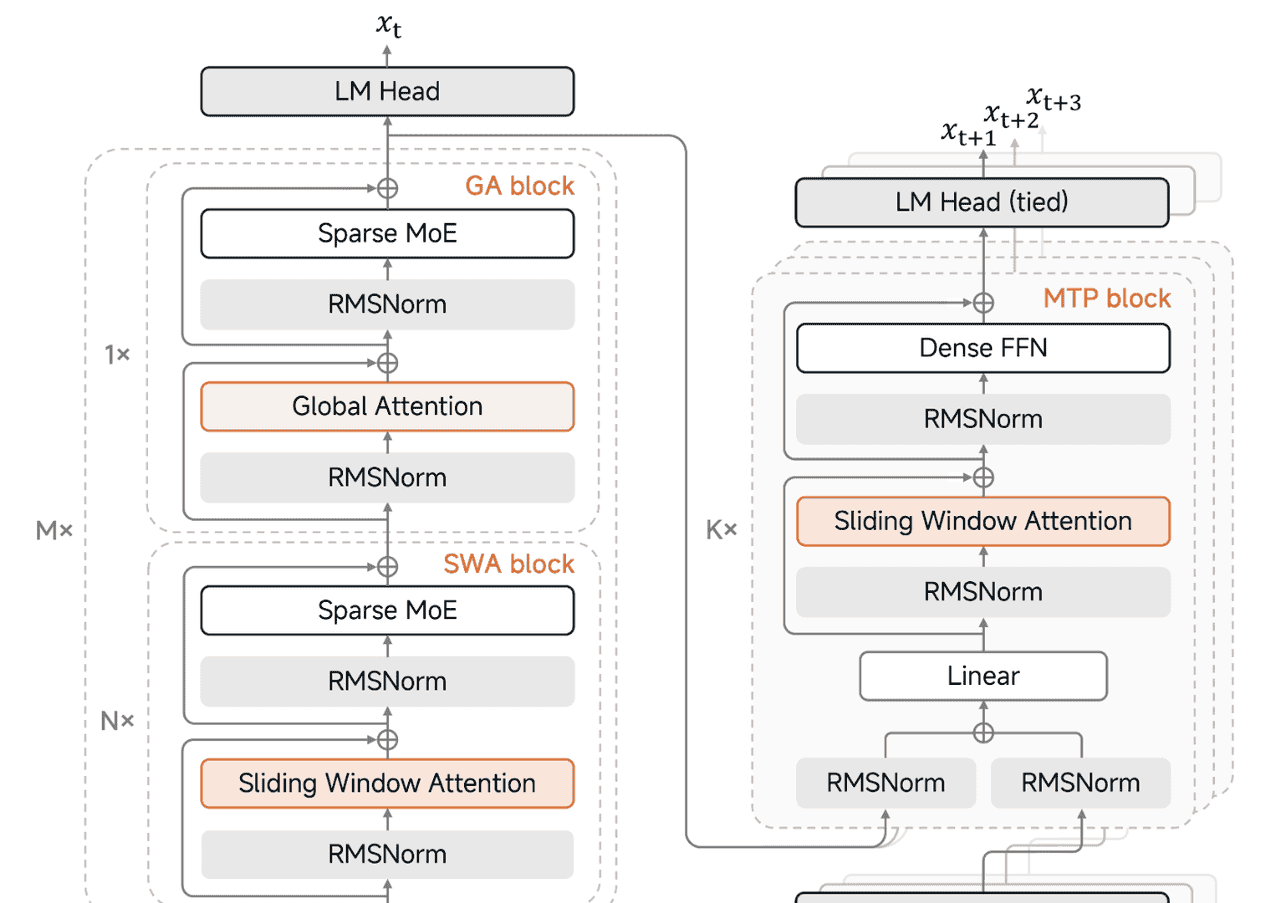
这种说法是不对的,一般来说,Encoder-Decoder 架构的模型,做不到很快的生成速度。
并且,自 GPT-3 之后,几乎所有的主流大模型都采用 Decoder-Only 的架构。
MiMo-V2-Flash 也不例外,图中左侧部分是Decoder,右侧部分是 MTP block。
因此,左侧和右侧没有Encoder-Decoder那种强关联,真正的有效输出仍然是从Decoder输出的。
右侧的三层 MTP block则是相对独立的结构,只是“借用”了Decoder计算得到的中间状态。
从 HuggingFace 上可以明确看到三层 MTP 的权重和结构。
MTP加速原理
MTP的加入是为了让模型一次性不仅仅只输出下一个Token,而是能输出多个连续的Token。
一开始,我的理解是:模型是在最后一层添加MTP后,一口气输出多个Token。
仔细看了模型结构,发现这种理解完全是错误的。
因为自回归模型的本质就是根据前面的Token,预测下一个Token,而不是预测多个Token。
从直观上的看,那就是主流的语言模型一直是一个字一个字地吐出来,而不是一口气吐出一段话。
所以,MTP本身还是串行的,就像上一节所展示的结构图中所表现得那样:输入xtx_txt,输出xt+1x_{t+1}x
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










