本文是一个实战文章,欢迎有兴趣的粉丝复现程序。有兴趣留言或者私信联络。
目录
概要介绍
为何引入机器学习算法判异
机器学习如何革新控制图判异
实现效果图
机器学习算法的表现评价
本文部分代码
概要介绍
如果我们将SPC的控制图数据看作一条时间序列,那么 “判异”本质上就是一个“异常检测”问题。这正是机器学习大显身手的领域。
我开发的这个程序的核心思路就是:在传统规则运行的同时,让九种不同的机器学习算法并行扫描同一条数据曲线。每种算法都有自己独特的“观察视角”:
有的关注距离,有的关注密度,有的试图重构数据,还有的专门寻找“孤独”的点。
当这些视角达成共识时,我们就有更高信心认定异常的存在;当它们意见不一,则提示我们需要深入分析数据的特殊结构。
我编写了一个SPC程序,已经完成了如下功能:
1)自动生成数据集,或者用户提交数据集
2)为数据集绘制控制图,可以根据数据的特点,绘制12种常见的控制图
3)绘制直方图
4)使用八大判异规则对数据进行判异,并列出判异点,绘制带判异点的控制图
5)使用机器学习算法判异,并列出判异点,绘制带判异点的控制图
6)计算过程能力指数
7)使用大语言模型综合上述结果解读数据集及对应的控制图
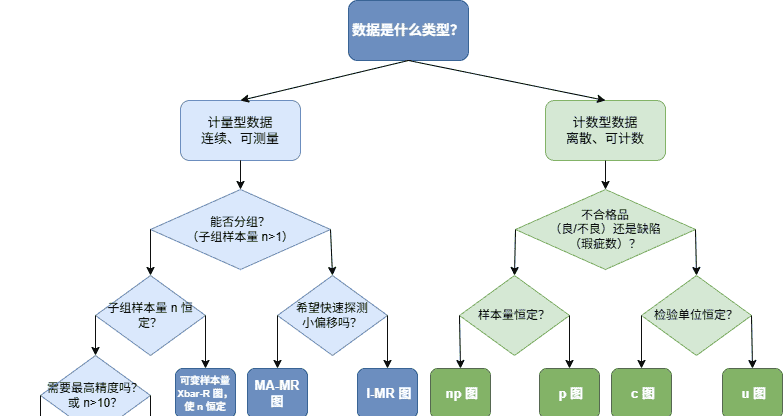
程序根据不同的数据,按照上述的控制图选择逻辑,支持的控制图如下:
计量型控制图(5种)
1. I-MR图(单值-移动极差图):适用于每次只收集一个数据或样本内无法分组的情况
2. Xbar-R图(均值-极差图):最常用,适用于样本量较小(通常n<10)且可分组的情况
3. Xbar-s图(均值-标准差图):适用于样本量较大(通常n≥10)且可分组的情况,用标准差代替极差
4. MA-MR图(移动平均-移动极差图):使用移动平均代替单值,对过程均值的小幅偏移更敏感,适用于需要平滑数据波动的情况
5. X̃-R图(中位数-极差图):使用中位数代替均值,对异常值更稳健,适用于数据中存在异常值或分布偏斜的情况
计数型控制图(4种)
6. P图(不合格品率图):用于监控不合格品所占的比例,样本量可以变化
7. NP图(不合格品数图):用于监控不合格品的数量,要求样本量固定
8. U图(单位缺陷数图):用于监控单位产品上的缺陷数,样本量可以变化
9. C图(缺陷数图):用于监控固定单位内的缺陷总数,要求样本量固定
其他常见类型(2种)
10. EWMA图(指数加权移动平均图):对历史数据赋予不同权重,对过程的微小漂移更敏感
11. CUSUM图(累积和图):累积过程偏离目标值的偏差,能更快检测出小幅度持续偏移
12. T²图(多元控制图):用于同时监控多个相关的质量特性
有关控制图及其介绍可以读这一篇推文:
怎么选?一文读懂12种SPC控制图,从基础到进阶,再到Python代码实现
程序支持的机器学习判异算法如下:
1.KNN(K近邻)
2.K-Means(K均值)
3.SVM(支持向量机)
4.Isolation Forest(孤立森林)
5.AutoEncoder(自编码器)
6.PCA-Based Outlier(主成分分析为基础的异常检测)
7.Prophet Outlier
8.Local Outlier Factor(局部异常因子)
9.DBSCAN(基于密度的带噪声应用空间聚类)
时序数据异常检测算法可以读这几篇推文:
怎么选?时间序列异常检测算法-基于深度学习的算法
怎么选?时间序列异常检测算法-基于图神经网络的算法及其它算法
怎么选?时间序列数据异常检测算法——线性模型与支持向量机算法
怎么选?时间序列异常检测算法-基于分解与预测的算法
怎么选?时间序列异常检测算法-基于集成与森林的算法
怎么选?时间序列异常检测算法-基于距离/密度的经典算法
怎么选?时间序列异常检测算法-传统统计学算法
Python语言的时间序列数据异常检测库
为何引入机器学习算法判异
随着制造业数字化转型的深入推进,质量控制呈现出新的发展趋势和需求:
智能化质量管理系统成为主流。企业需要能够实时感知工艺波动、精准预测缺陷风险、快速定位问题根源的智能系统。
绿色制造与可持续发展成为新方向。质量控制不仅要保证产品质量,还要考虑环境影响和资源利用效率。
个性化定制与柔性生产带来新挑战。小批量、多品种的生产模式要求质量控制系统具备更强的适应性和灵活性。
全球协作与标准化成为新趋势。跨国生产和供应链管理需要统一的质量标准和实时的数据共享。
面对这些新需求,传统 SPC 方法已经难以满足智能制造的要求,亟需引入新的技术手段。
而统计过程控制(SPC)自 20 世纪 20 年代休哈特博士提出以来,已经走过了百年历程。其核心思想是通过控制图识别过程中的异常波动,基于 “数据服从正态分布” 的假设和小概率原则进行判异。然而,随着智能制造时代的到来,传统 SPC 正面临着严峻的挑战。
首先是数据分布的复杂性。传统 SPC 方法严重依赖正态分布假设,但现实生产中大量数据呈现偏态分布、多峰分布或存在厚尾现象。例如,新能源电池生产线的电压数据可能因材料批次差异呈现偏态分布,医疗监护仪的心率数据易受个体差异影响出现厚尾特征。当数据不符合正态分布时,基于正态分布特性设计的控制限和判异准则就不能反应实际的小概率事件,导致误报警过多。
其次是检测能力的局限性。传统 SPC 被形容为 “后视镜式监控”,往往在发现异常时,已经产生了大量不良品。更严重的是,传统方法采用 “孤岛式检测”,无法发现多因素耦合作用,就像只量血压不管血糖,无法识别环境温湿度波动与设备振动的 “组合拳” 效应。此外,控制线设定依赖历史数据,对新材料、新工艺反应迟钝,缺乏自适应能力。
第三是智能化程度不足。调查显示,73% 的企业缺乏专业数据分析团队,SPC 控制图仍依赖人工解读,质量问题重复发生率高,根本原因难以精准定位。同时,IT 系统与 OT 生产系统分离,数据无法实时互通,生产计划与车间设备脱节,异常数据无法及时反馈管理层。
传统 SPC 的八大判异规则包括:
一点超出 3σ 控制限
连续 9 点在中心
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











