
一个学生把习题册答案背得滚瓜烂熟(训练集满分),但考题稍一变样(新数据)就不会了。这就是”过拟合”。AI如何避免成为这样的”高分低能”学生?
本文是《从零到精通大模型》系列第12章,深入解析过拟合问题与正则化技术:Dropout、权重衰减、早停法等如何防止模型死记硬背,提升泛化能力。
一、我的”血泪教训”
2020年,一个电商评论情感分析项目。
客户要求:根据用户评论,自动判断是好评、中评还是差评。
第一阶段:盲目追求准确率
项目收集了10万条历史评论数据,精心标注。
用BERT模型训练,效果惊人:
训练集准确率:99.8%(几乎全对!)
验证集准确率:98.5%(也很棒!)
我当时的想法:“这模型太强了!”
第二阶段:现实打脸
模型上线后,客户反馈:“经常判断错误!”
检查发现:
训练数据中,”快递很快”基本都是好评
但现实中,有人写”快递很快,但商品是假货”(应该是差评)
模型看到”快递很快”,就判断为好评
问题:模型只记住了训练数据的表面规律,没学会真正的语义理解。
这就是典型的过拟合(Overfitting)。
二、过拟合:AI的”死记硬背病”
什么是过拟合?
模型在训练数据上表现极好,但在新数据(测试集、真实场景)上表现很差。
比喻:
好学生:理解知识点,能举一反三
刷题家:只背答案,题目稍变就不会
可视化理解
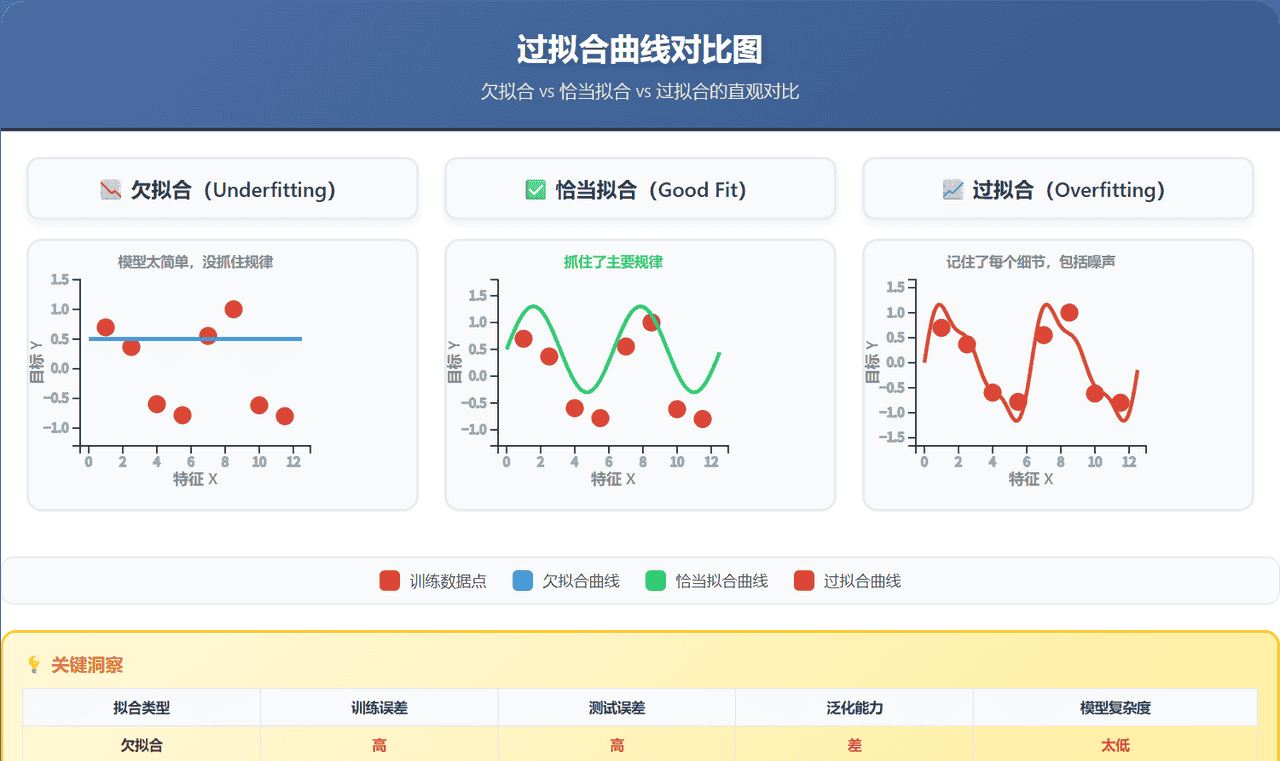
想象我们要拟合这些数据点:
欠拟合:一条直线,太简单,没抓住规律
恰当拟合:平滑曲线,抓住了主要规律
过拟合:扭曲曲线,穿过了每个点,但没抓住本质
为什么大模型更容易过拟合?
大模型(千亿参数)就像记忆力超强的天才:
能记住训练数据的每一个细节
包括噪声(偶然性)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











