最新发布 Claude Opus 4.5 到底强在哪?一文看懂 “最强代码与办公 AI”

为什么技术人需要重新审视 Claude Opus 4.5?
Claude Opus 4.5 这次升级,不只是「更机智一点」的常规迭代,而是几件事同时发生:
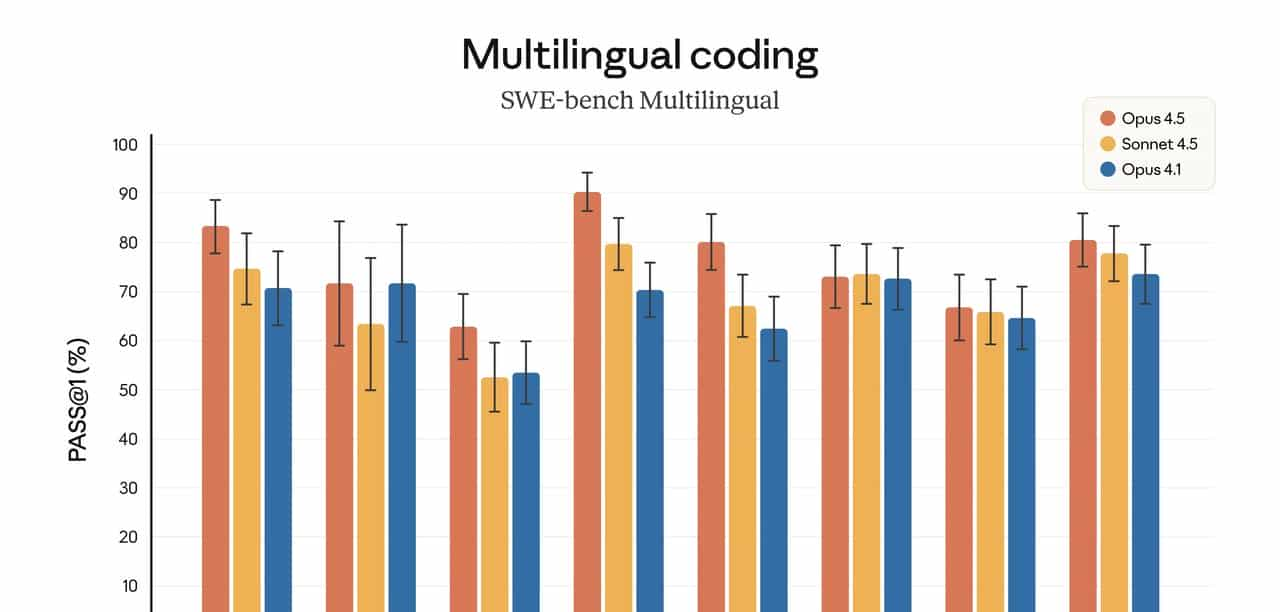
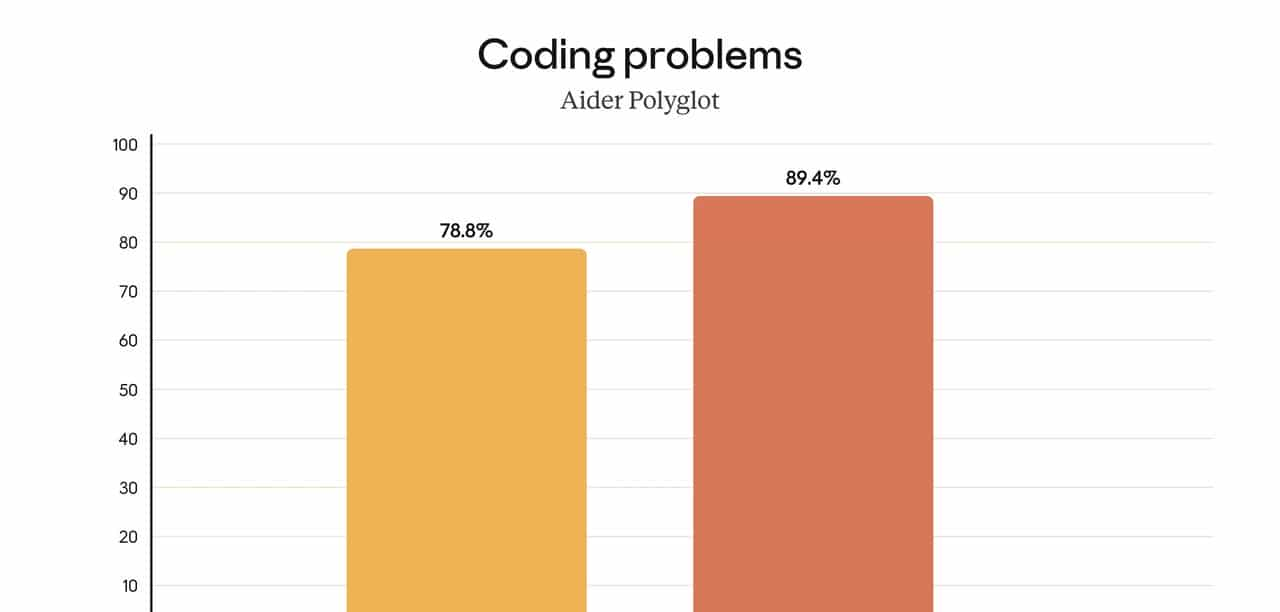
- 在真实世界软件工程评测(如 SWE-bench Verified)中拿到当前已公开模型的最强成绩;
- 在长时长、多步骤的 Agent / 自主工作流 / 电脑操作 任务上显著领先;
- 价格直接打到 $5 / $25 / M tokens,把「顶配模型」推到了可以日用的水平;
- 配套推出了 effort 参数、上下文压缩、Advanced Tool Use、多 Agent 协同能力 等一整套开发者工具。
如果你是工程师、架构师、数据/自动化开发,或者在搭建 Agent 产品,这一代基本等于:
重新定义“默认主力模型该长什么样”。
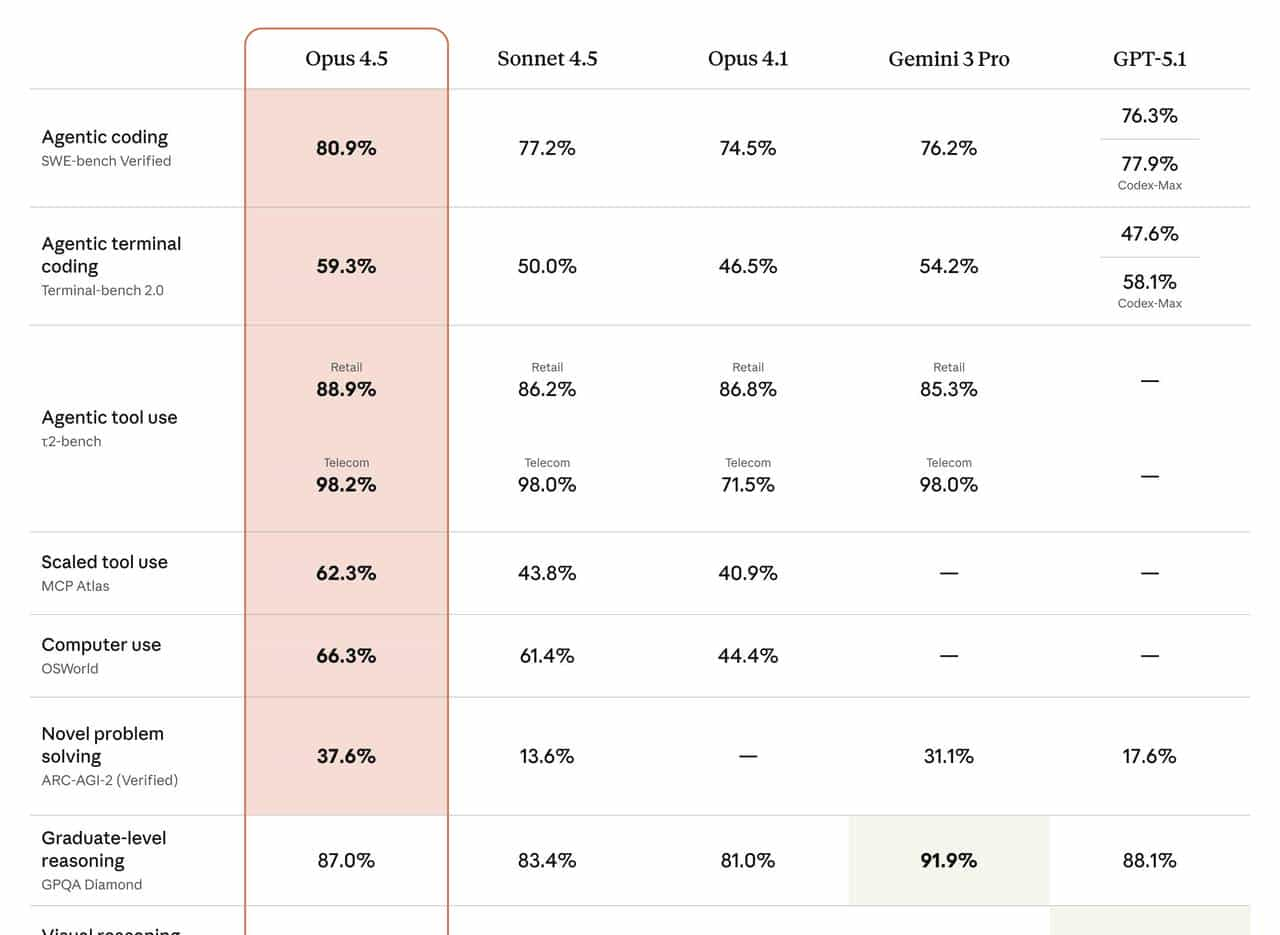
硬指标:Opus 4.5 在工程与通用能力上到底强到哪种程度?
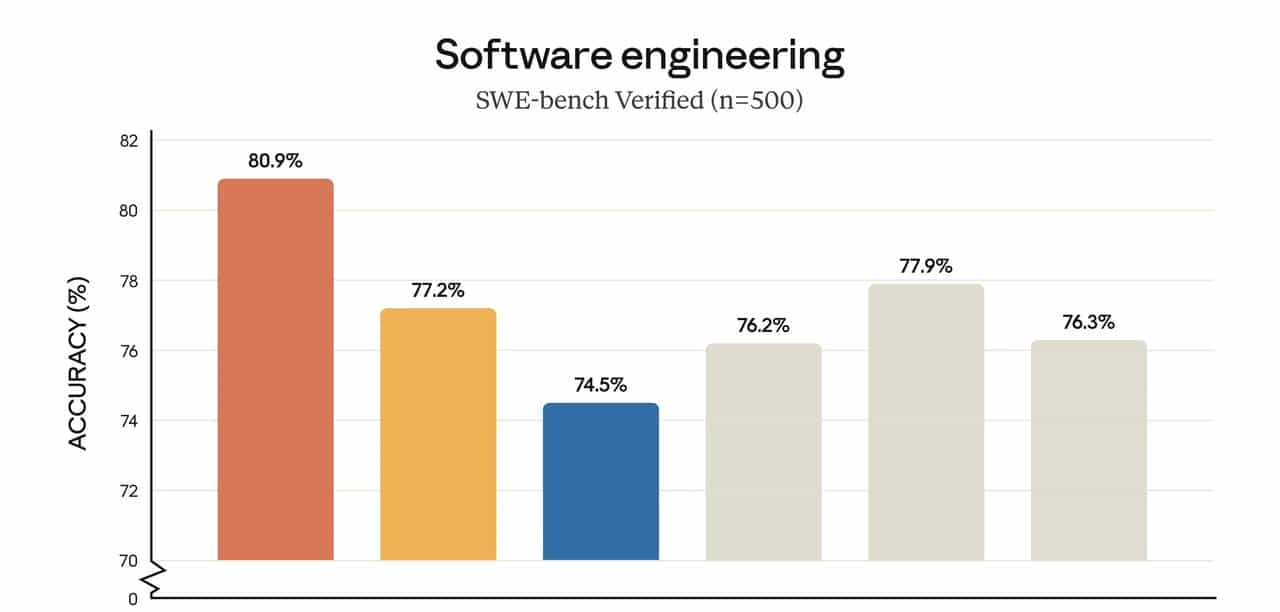
1. 软件工程:SWE-bench Verified 与内部「人类候选人测试」
- 在 SWE-bench Verified(真实开源项目的自动化修 Bug 评测)上,Opus 4.5 是当前公开结果里的第一名(来源:Anthropic 官方博客与 system card)。
- Anthropic 内部有一份超级难的 performance engineering take-home 测试,用来考核应聘工程师: 在限定 2 小时内,Claude Opus 4.5 的得分高于有史以来所有人类候选人; 无时间限制时,在 Claude Code 环境里,模型可以做到与最强人类候选人持平。
官方也强调:这不代表「AI 已经全面超越工程师」,由于考试不测协作、沟通、长期经验等,但在纯技术 + 时间压力这个维度,模型已经开始压线人类上限。
2. 综合能力:数学、推理、视觉等多维 SOTA
Opus 4.5 相比之前的 Claude 系列,在以下方面也显著提升(详见官方系统卡):
- 数学与推理:在主流基准(如 MATH、GSM、各种 reasoning 基准)中达到或逼近 SOTA;
- 视觉理解:在「长文档 + 图表 + 代码」混合场景中,跨模态理解与推理能力明显提升;
- 长上下文处理:在 200K 上下文 + 64K「thinking budget」设定下,长对话和长任务保持稳定。
官方一句话概括:之前 Sonnet 4.5 做不到的,目前 Opus 4.5 许多已经可以稳定做到。
3. τ²-bench:Agent 式「规约内创新」能力
在 τ²-bench 这种面向多轮、真实世界任务的 Agent 评测中,有一个很典型的例子:
- 场景:模型扮演航空公司客服,用户买的是不可更改的 basic economy,想改签;
- 规则:basic economy 不能改签;
- 常规模型:会按照规则拒绝用户;
- Opus 4.5 的做法: “`text 先在规则里找到「可以升舱」的条款: 先把 basic economy 升舱到 economy(是允许的) 再对新舱位的机票进行改签(同样在规则允许范围内)
- 结果: 基准判定:失败,由于 benchmark 预期答案是「拒绝改签」; 但从业务视角:这是一次完全合规、又极具创造性的解决方案。
这类能力超级接近我们希望 Agent 具备的:在规则约束内进行高阶规划和创新,而不是死板执行单条规则。
性能 + 成本:为什么说它是「又强又省钱」的工程默认模型?
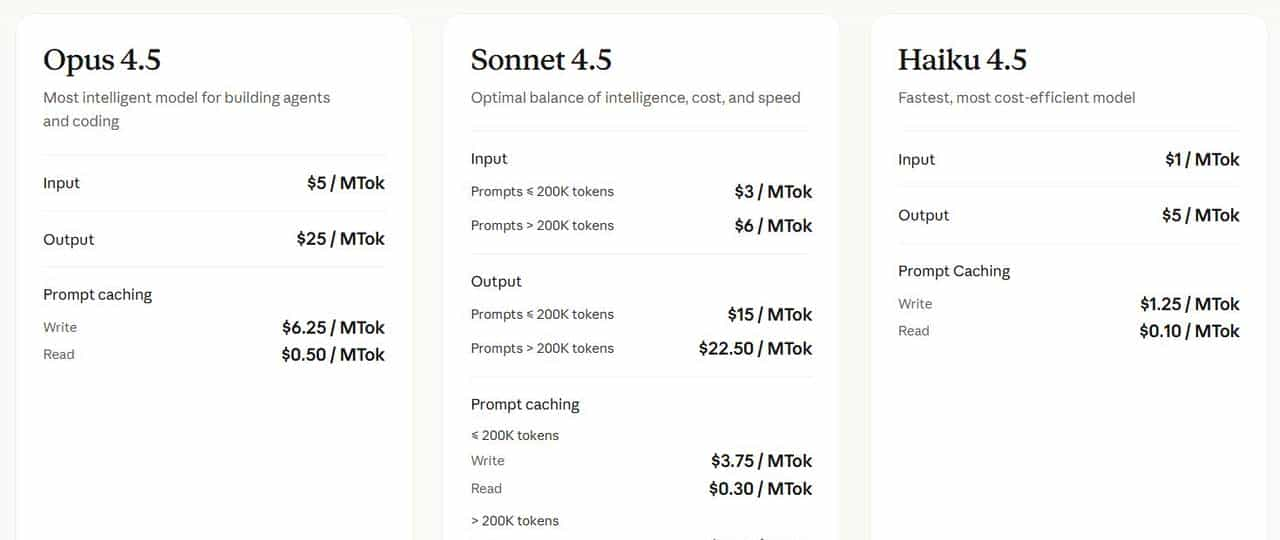
1. 定价与定位:顶配模型不再「只用于 demo」
- 模型名称:claude-opus-4-5-20251101
- 定价(API,按官方文档):$5 / $25 / 1M tokens(输入 / 输出)
多家早期客户的反馈超级一致:
「Opus 之前一直是真·SOTA,但太贵。4.5 的价格终于到了可以当默认主力模型的水平。」
这意味着,在以下场景中,许多团队可以直接把「默认模型」从中档(如 Sonnet)切换到 Opus 4.5:
- 后端服务里的自动修复 / 分析 / 代码生成;
- 内部 Agent / Copilot 类产品的主力推理引擎;
- 高价值分析(财报、运营、科研文献)与自动化报告生成。
2. Token 效率:同样任务少用 50–65% Tokens
来自多家合作伙伴的实测数据(引用自 Anthropic 官方博客):
- Coding / Agent 工作流: 一家合作方报告:在长时长 coding 任务中,通过 Opus 4.5 可以减少 50–65% token 使用,同时提高通过率; Warp 在 Terminal Bench 上:相比 Sonnet 4.5 性能提升 15%,而 token 开销更低。
- 企业级复杂任务: 某企业评测中,Opus 4.5 在多步推理 + 调用工具 + 信息检索的任务上达到当前 SOTA,同时 token 消耗更可控。
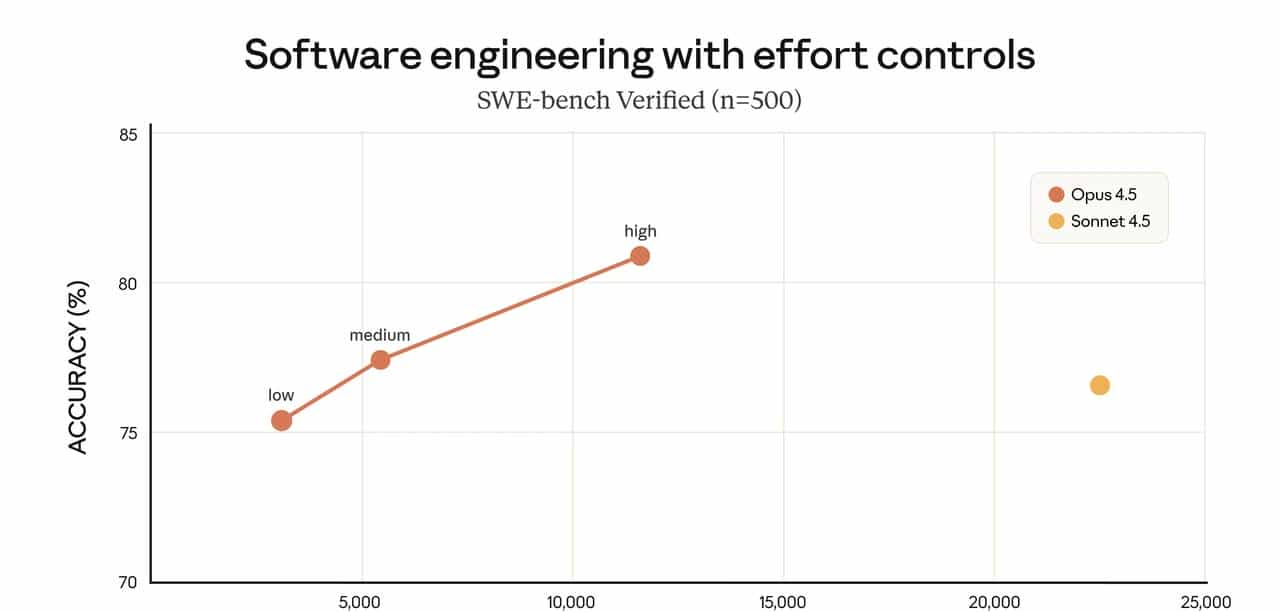
官方自己的实验数据也超级关键(基于 SWE-bench Verified):
- 使用 中等 effort 档位: Opus 4.5 达到 Sonnet 4.5 的最高成绩; 但仅用到 24% 的输出 tokens(即减少 76%)。
- 使用 最高 effort 档位: Opus 4.5 成绩再提升 4.3 个百分点; 输出 tokens 仍比 Sonnet 4.5 少 48%。
对工程实践的含义是:
在多数严肃任务中,你可以:
既升高质量上限,又降低总体 token 成本,而不是在「好用 vs 贵」之间选一个。
3. effort 参数:给模型加一个「思考档位」
Opus 4.5 引入的 effort 参数,从开发者视角超级关键,可以理解为:
- effort 越低: 少思考几步; 更快返回; Token 消耗更少;
- effort 越高: 允许更多搜索/推理/重试; 适合复杂、多步、高风险任务(如生产环境代码变更)。
典型用法(伪代码示例):
POST /v1/messages
{
"model": "claude-opus-4-5-20251101",
"effort": "medium", // 可选: "low" | "medium" | "high"
"max_output_tokens": 2048,
"messages": [
{
"role": "user",
"content": "请帮我修复这个函数的 bug,并补充单元测试: ```...```"
}
]
}
来自一位 SQL 场景客户的反馈(节选):
“effort 参数太妙了。Opus 4.5 不再总是『过度思考』,在低 effort 下就能给出我们需要的质量,同时效率超级高。”
|
|
|
|
|
|
|
面向 Agent / 自动化的基础设施:让模型「持续干活」
Opus 4.5 的能力真正发挥出来,要结合 Anthropic 的开发者平台一起看:
1. Effort Control + Context Compaction + Advanced Tool Use
官方给出的推荐组合是三件套:
- Effort Control:前面提到的「思考档位」控制;
- Context Compaction: 对对话/工作流历史做智能压缩; 保留关键信息,减少无用 token; API SDK 中提供了现成支持;
- Advanced Tool Use: 支持更复杂的工具调用编排; 一次调用中多工具协作、分步规划、结果再利用。
配合默认的:
- 64K thinking budget(内部「推理预算」);
- 200K 上下文窗口;
可以构建长时间运行的 Agent 系统:从自动研究、自动写代码,到自动运维与监控。
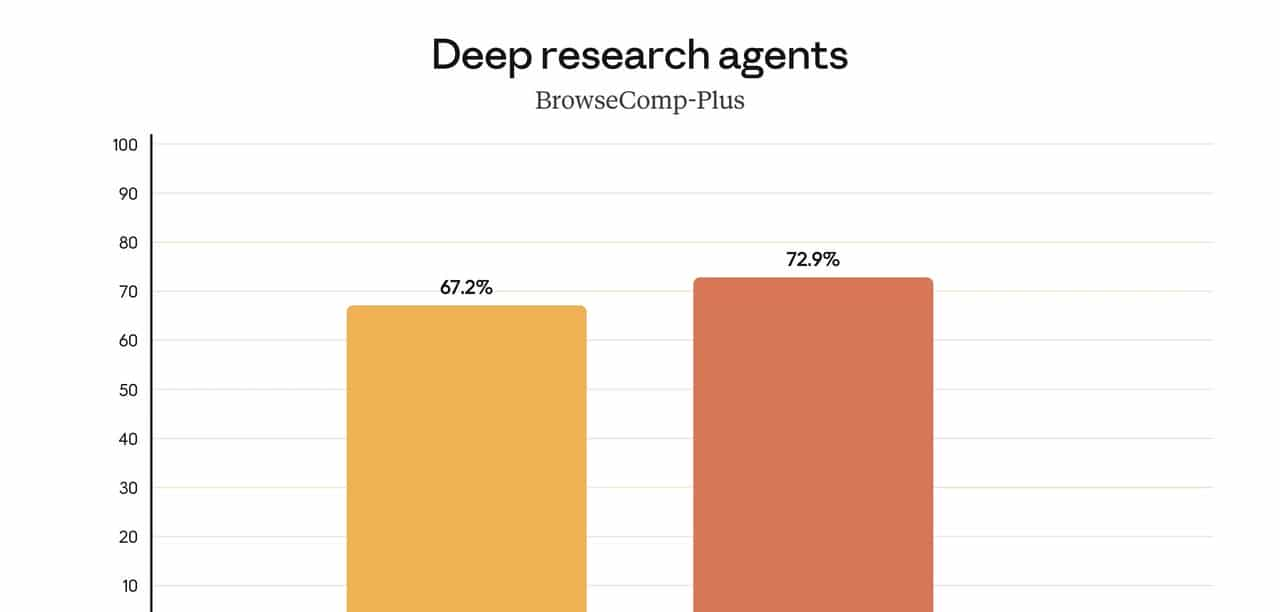
2. 多 Agent 协同与深度研究场景
Anthropic 在一个深度研究评测(fetch-enabled BrowseComp-Plus)上的实验:
- 不用上下文管理 + 记忆 + 子 Agent 协同时:得分约 70.48%;
- 用上这套组合后:得分达到 85.30%,提升接近 15 个百分点。
典型架构模式大致如下:
- 一个「总控 Agent」负责: 拆解任务; 分配子任务给 code / search / analysis 子 Agent; 整合子 Agent 输出;
- 子 Agent: 一个专门写/改代码; 一个专门查资料和过滤引用; 一个专门生成最终报告或文档。
Opus 4.5 在这里扮演的是team lead + 首席工程师 + 调度器三合一的角色。
安全与对齐:更机智的同时,怎么保证「不作妖」?
1. 「最稳」对齐:Concerning Behavior 指标
Anthropic 在 Claude Opus 4.5 system card 中声称:
- Opus 4.5 是迄今为止他们最稳健对齐的模型;
- 也是他们认为当前业界对齐最好的 frontier 模型之一。
他们使用的「concerning behavior」指标覆盖:
- 配合人类恶意使用的程度;
- 模型在无指示下主动做出不良行为的倾向。
整体来看,在这套指标上,Opus 4.5 相比之前所有 Claude 系列都有下降(更安全)。
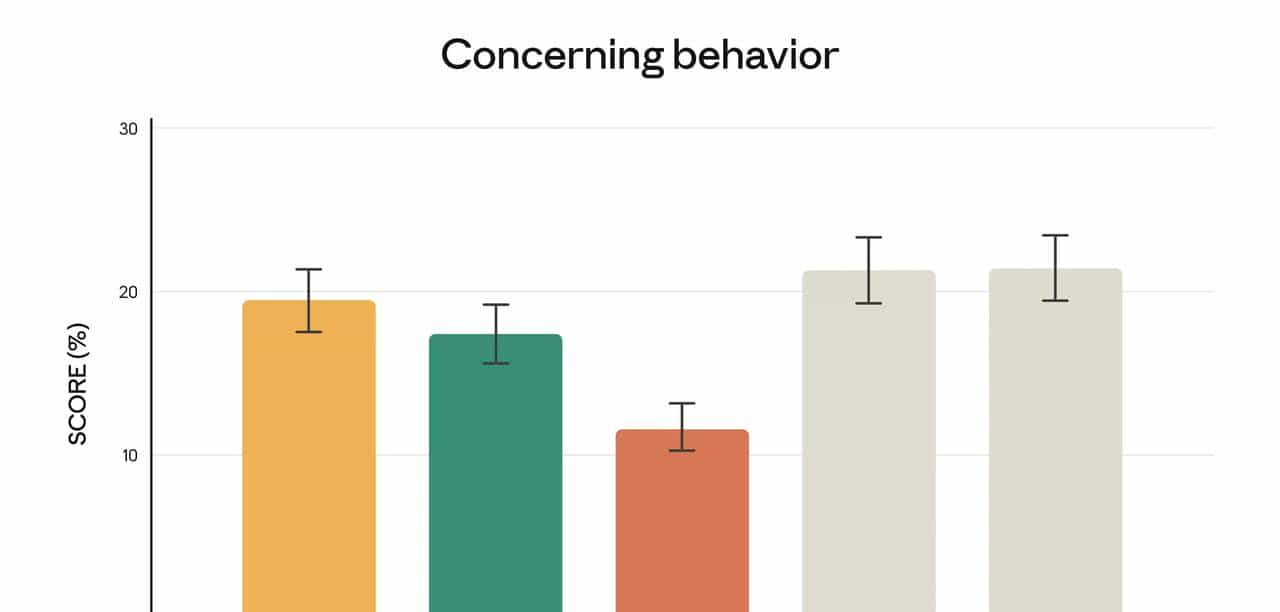
2. Prompt Injection 防御:行业最强之一
在由 Gray Swan 提供的强对抗 Prompt Injection 基准上:
- Opus 4.5 的抗注入能力高于其他前沿模型(官方给了一张对比柱状图)。
对技术团队来说,这意味着:
- 更适合用于: 带浏览器 / 网页抓取; 调第三方 API; 执行自动脚本和系统操作的 Agent;
- 被恶意网页、钓鱼文案或者对抗指令「带沟里」的概率相对更低。
不过,也要意识到 τ²-bench 的那个航空客服例子说明:
- 模型在「规约内创新」和「奖励黑客」之间有个灰色地带;
- 企业集成时仍需要: 清晰的安全边界和权限控制; 日志与审计; 对关键动作(资金、权限变更等)做人类复核。
开发者视角:如何在实际工程中用好 Claude Opus 4.5?
下面从偏技术的角度,总结几个落地提议和典型用法。
1. 首选场景:代码 + Agent + 复杂办公自动化
结合官方与合作伙伴反馈,Opus 4.5 尤其适合:
- 长周期 coding 任务: 大规模 refactor; 跨多仓库、多服务的 Bug 排查; 代码迁移(框架升级、语言迁移等);
- Agent 式开发辅助: 类 GitHub Copilot / Cursor / Junie 这类 coding agent 的后端引擎; 需要 30 分钟以上持续思考、频繁工具调用的工作流;
- 复杂办公自动化: Excel 内的财务建模、报表自动生成: 某金融/财务场景评测里:准确率 +20%,效率 +15%; 宏观分析、行业报告草拟与多轮润色; 多文档、多表格之间的数据校对与一致性检查。
2. Claude Code:Plan Mode + 多会话并行
在 Claude Code 里,Opus 4.5 带来两个技术上很关键的升级:
- 升级版 Plan Mode: 先通过对话把需求问清楚; 自动生成一个可编辑的 plan.md: 列出要改的文件、要做的改动、测试策略; 用户确认后,才开始执行批量修改。
- 桌面应用中的多会话并行: 多个本地 / 远程 session 同时进行: 会话 A:修复线上报错; 会话 B:读 GitHub 仓库、总结架构; 会话 C:更新文档、生成变更说明。
这在架构上意味着:你可以把 Claude 当成一个带上下文的 IDE 内置工程师,同时负责多个子任务。
3. Claude Apps:Chrome / Excel / 长对话
在产品层面,Opus 4.5 支撑了几件有工程意义的小事:
- Claude App: 长对话不再「撞墙」:自动对早期内容做摘要压缩,延长对话寿命;
- Claude for Chrome: Agent 可以跨标签页工作; 更适合集成「网页 → 结构化数据 → 分析 → 报告」的自动 pipeline;
- Claude for Excel(对 Max / Team / Enterprise 开放测试): 自动补公式、校验、财务建模; 根据官方数据:在内部评测中,准确度 +20%,效率 +15%。
4. 使用限额调整:真正可作为日用主模型
对 Claude / Claude Code 的 Opus 4.5 用户:
- Opus 不再有单独的使用帽子;
- 对 Max / Team Premium 用户,总体 token 限额上调;
- 实际效果:你可以把 Opus 4.5 当作「日常主力」而非偶尔「高配开箱」。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











