
也许随着AI的持续发展,这个标题在未来真的可以实现,但并不是目前。
尽管ChatGPT的出现,让写程序的门槛大幅降低;但目前还是有不少ChatGPT无法解决,或是解决不好的问题。

这篇文章会用栗子让读者理解ChatGPT在写程序上的局限,以及适合使用的场景。
提醒大家,不要未经授权下载有版权保护的影片喔!
开发步骤:
STEP 1:安装相关Python 套件,pip install pytube pydub openai

STEP 2:建立一个ytb2txt.py的文件,贴上ChatGPT 的程序。
vi ytb2txt.py
from pytube import YouTube
from pydub import AudioSegment
import openai
# 设定要下载的影片URL
url = “https://www.youtube.com/watch?v=JuntxVmi3wM”

# 建立YouTube对象
yt = YouTube(url)
# 取得影片的音轨
audio_stream = yt.streams. filter (only_audio= True ).first()
# 下载音轨到指定的路径
audio_stream.download(output_path= “./save” , filename= “audio.mp3” )
# 读取下载下来的音频文件
audio_file = AudioSegment.from_file( “./audio.mp3” )
# 切割音频文件成多个小文件
chunk_size =100 * 1000 # 100 秒
chunks = [audio_file[i:i+chunk_size] for i in range ( 0 , len (audio_file), chunk_size)]
# 使用OpenAI 的Audio API 将每个小文件转成文字,然后合并在一起
openai.api_key = “YOUR_API_KEY”
transcript = “”
for chunk in chunks:
with chunk.export( “temp.wav” , format = “wav” ) as f:
result = openai.Audio.transcribe( “whisper-1” , f)
transcript += result[ “text”]
# 整理逐字稿
completion = openai.ChatCompletion.create(
model= “gpt-3.5-turbo” , #用turbo可以省钱哦
messages=[
{ “role” : “user” , “content” : “使用简体中文阅读,帮我改错字、加标点符号,并分段使内容更通顺:
” +transcript}
]
)
# 打印出整理后的文字
print (completion.choices[ 0 ].message.content)
STEP 3:在终端机输入python ytb2txt.py,然后稍等一段时间…就会看到成果啦!
表面上看起来整理得挺不错,但仔细看会发现结尾突然断掉了,这是为什么呢?
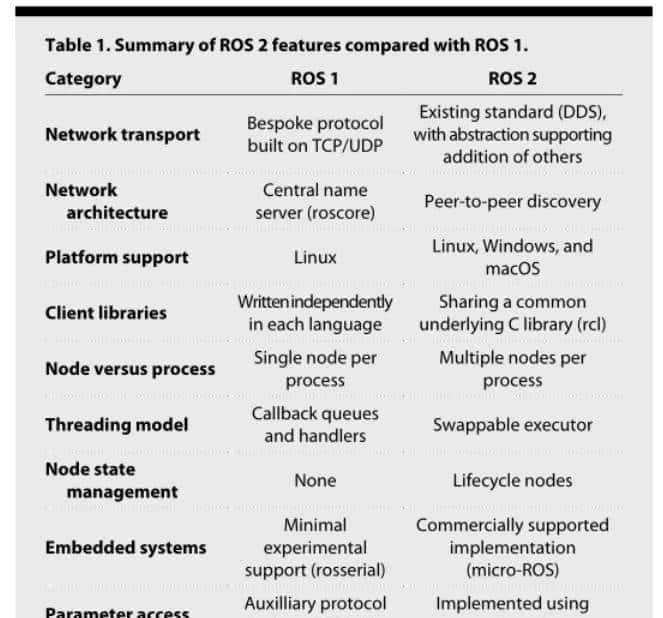
这边用OpenAI官方文件比较好说明,每个GPT模型都有自己的max_tokens,我们选用的 gpt-3.5-turbo 最高上限是4096。
https://platform.openai.com/docs/models/gpt-3.5
所以截断的缘由就是我们的prompt太长了,所谓prompt长度就是我们传入的逐字稿长度。
而中文跟英文计算Token 的方式也不尽一样,如果使用英文,1000 个tokens 大约等于750 个单字;但如果使用中文,1000 个tokens 大约只有400 字。
https://platform.openai.com/tokenizer
上面是补充说明,让我们回到原本的话题,我们要如何让逐字稿完整的被整理,不要被截断呢?
最直觉的做法就是将逐字稿「分段」传送过去,4096 的token 换算成中文大约1600 字,我们保守一点,用「1200」的长度来做分割,下面是整理好的程序。
# 依照我们指定的长度分割字串
def split_text ( text, max_length ):
return [text[i:i+max_length] for i in range ( 0 , len (text), max_length)]
# 整理逐字稿
def process_text ( text ):
response = openai.ChatCompletion.create(
model= “gpt-3.5-turbo” ,
messages=[
{ “role” : “system” , “content” : “You are a helpful assistant.” },
{ “role” :”user” , “content” : “使用简体中文阅读,帮我改错字、加标点符号,并分段使内容更通顺:
” +text}
]
)
return response.choices[ 0 ].message.content
# 处理长字串
def process_long_text ( long_text ):
text_list = split_text(long_text, 1200 )
processed_text_list = [process_text(text) for text in text_list]
return “” .join(processed_text_list)
# 调用处理函数
processed_transcript = process_long_text(transcript)
# 打印出处理后的逐字稿
print (processed_transcript)
在终端输入python python ytb2txt.py,就会看到被分段,并加上标点符号的成果啦!

成果图片
温馨提示:本文是纯学术讨论,请遵守国家相关法律
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章












学习了
厉害了
可以可以。