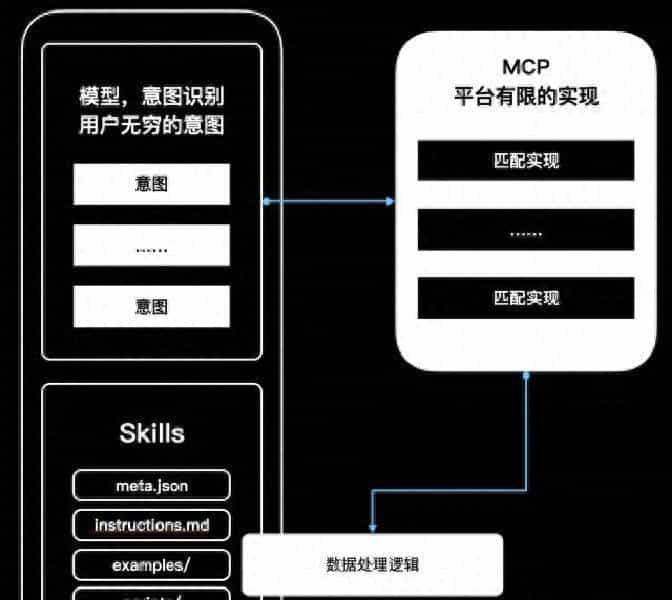
MCP已经成了实际上的接口标准,Skills变成了那层把业务套路塞进模型里的东西,两者相互补位,但也有摩擦。
上个月老板问了句“上月华东区销售Top3”,最后AI给出的汇报像人做的一样:一句话结论,几个关键数据点,异常提示,具体提议。结论写得直白:华东总体不错,Top3里两款增长,一款下滑;关键数据按产品列出,iPhone 15、MacBook Pro、AirPods Pro的销售额、增幅和毛利都有;对下滑的AirPods指出了门店库存高企并给出促销和补货提议。老板看完不到十秒钟就点头,开发团队在后台把这当成一次“吃鸡腿”的胜利。
这份“高质量输出”不是模型随意编的,而是Skills在起作用。工作流程倒着看很直观:先是Skill把输出结构、分析方法、禁忌、模板、例子都准备好;当模型拿到MCP返回的数据后,Skill会把“该怎么解读这些数据、该先说什么、别犯哪些错误”这些规则塞进上下文里,最后以固定格式输出。所谓渐进式加载,就是先用超级短的meta来做命中检索,只有命中的Skill才把完整的说明文档、示例、脚本加载进来。这样上下文就不会被各种说明撑爆,但模型依然能用上专业的SOP。
举个更具体的例子。boss_bi_briefing_cn 这个Skill,meta里会写清楚它适用于“高层经营汇报、按区域/产品看TopN、询问上月/上季度经营情况”等场景;instructions里会写输出结构必须是“一句话结论→关键数据点→缘由拆解→风险与提议”,并列出分析步骤,列如必须检查销售额、毛利、同比环比、重点客户贡献度,也会给出调用哪些MCP工具的提议。还有模板、正反例、检查清单。Claude接到“上月华东区Top3”的请求时,先用meta判断“这是给老板看的”,命中后把instructions拉进来,利用返回的数据按SOP组织内容,输出那段看起来很职业的汇报。
说Skills之前,得回到MCP。Model Context Protocol本质上是一个开放标准,用来统一模型和外部工具、数据的交互方式。想像一下HTTP的角色:只要大家按约定来,就能相互通。产生的背景比较实际:大模型想要解决现实问题,必须能读报表、查数据库、开浏览器、读写文件。早期的做法是把这些能力封装进一个中间程序:前端把请求给中间件,中间件去调用模型并根据模型的返回再去调用各种API。这样能工作,但问题也很明显——中间程序成了一个定制化、闭环的“胶水层”。
后来有人不太认同这个中间程序长期存在的做法,就把一套固定格式的API调用能力直接在模型侧做了支持,让模型能够以标准化的格式请求外部服务。接着文件读写、浏览器控制等需求都沿用了这套格式,慢慢形成了协议。结果就是目前MCP几乎成了实际上的通用方式:模型可以像调用函数一样“叫”外部工具,传入参数、取回结果。
回到实践层面,MCP的一个典型实现流程是这样的:先有一个预制的工具包,告知模型“你能用这些工具”,列如把销售分析、客户分析、运营分析这些工具列出来,每个工具再告知模型它能做什么、需要哪些参数。模型从自然语言里抽出参数,组装成工具调用指令,列如:

{ “tool”: “
sales_analysis.regional_ranking”, “parameters”: { “region”: “华东”, “time_period”: “last_month”, “top_n”: 3 } }
工具执行后返回结构化数据,模型拿到数据后可以继续加工或把它传给Skill去格式化输出。
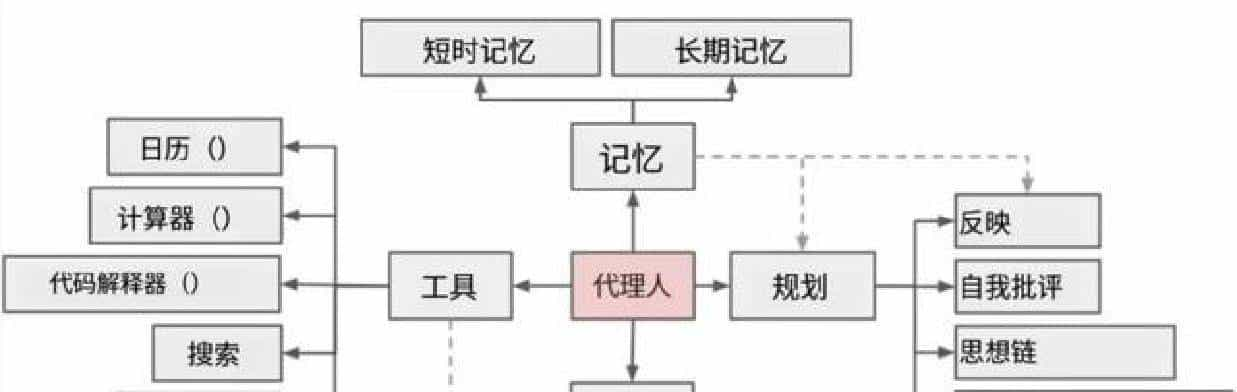
但这套体系有个明显的短板:MCP能把数据和接口接通,但模型具体怎么用这些数据,并不是MCP管的。换句话说,MCP确保“拿到东西”,但不会教模型“怎么用这些东西”。这就牵涉到知识产权和安全问题:许多公司不愿意把自己的业务逻辑、调用顺序、判断标准直接写进外部服务的描述里;同时也担心模型随意引用或泄露内部逻辑。Skills在这种情况下应运而生——它们更像是给模型准备的岗位说明书和操作手册,包含可复用的SOP、范例、脚本和资源。模型在执行任务时会扫描现有Skills,找到相关的就把这些说明拉入上下文里按规程执行。
把两个东西放一起看,会更清楚。MCP负责接入能力:把数据库、报表、文件、浏览器等能力标准化开放;Skills负责把具体的业务套路、汇报格式、敏感点、可接受的推断范围写清楚并按需加载。一个管“能拿到什么”,一个管“拿到后怎么干”。实践中二者边界并不总是那么硬,一个Skill里可能会提议去调用哪些MCP工具;同样有些MCP服务自带比较清晰的使用逻辑,能把部分“怎么用”写进工具说明里。
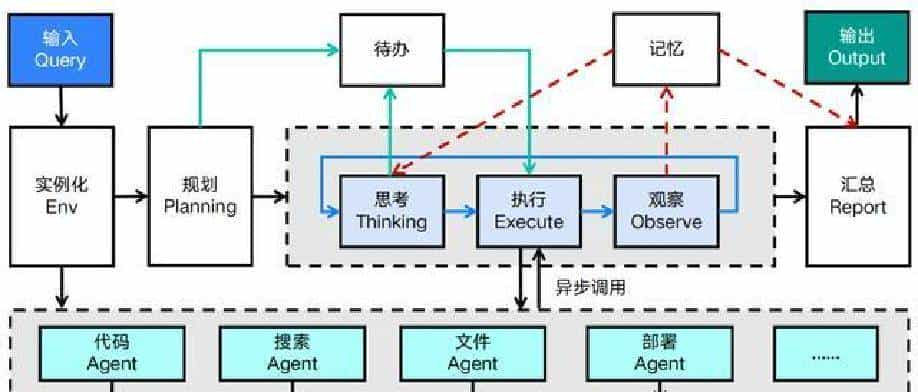
把流程拆开讲更容易理解。想像以前老板问问题的老流程:打开BI系统、选时间、筛区域、排序、看前几名,整个过程可能需要几分钟到十几分钟并且老板常常没耐心。目前的流程是老板直接问AI,AI把查询参数抽出来、调用MCP里的销售排行接口、拿到数据,再把数据交给对应的Skill按高层汇报格式输出,整个链路在十秒钟内完成。用户体验提升明显,但这背后是多个环节的协同:意图识别、参数抽取、工具调用、数据返回、Skill驱动的分析与输出模板。
说回技术实现细节,Skill一般是一个目录,里面有meta.json、instructions.md、examples、scripts、assets等。meta.json只写超级短的描述和使用场景,便于做快速检索;instructions.md写清楚SOP、优先级和禁忌;examples里放好坏样例供模型参考。实际触发时,模型先用meta做候选过滤,再把合适的instructions和样例拉进上下文。这样既保留了可控性,也能让模型输出符合业务需求的结构化结果。
有意思的是,这套体系对基模型的要求不低。Skill要按需加载并有效起作用,模型必须能准确判断用户意图并正确匹配Skill的meta。意图识别不到位,或者meta写得不够准确,都可能导致模型拉错Skill,反而把输出弄糟。换句话说,Skills把许多业务规则和专业化知识从Prompt里剥离出来,这本身是好事,但也把对模型的能力要求抬高了。
回过头看Agent架构的流行,有两个现实条件促成:一是大模型在过去几年里能力提升明显,包括推理和更长上下文;二是互联网多年积累下的各种小工具已经存在,等着被调用。Agent不可能穷举人的所有意图,但可以提供一组有限、可被命中的服务。当用户的意图落在这些服务里时,效果就会超级贴心。工程上,更多是把服务做好,把SOP写清楚,然后在模型端把匹配和调用做得稳当。
具体到企业应用,工程师们常常会把老板的偏好总结成一系列Skill:什么场景必须先给一句话结论,什么场景要强调毛利,哪些话不能说,哪些不该做推断。这些规则写成Skill后,模型在拿到MCP数据后就按规则报告。实际效果是,AI不再只是把数据平铺出来,而是以公司约定的“说话方式”去解读和提议。业务团队省了许多磨合成本,老板也乐意多用AI来问问题。
在实现上,MCP和Skill的分工看上去清晰,但真正把链路做稳需要不少工程工作:给模型准备好工具描述、调优意图识别、把Skill里复杂的SOP写得既详细又不冗长、处理好权限与审计链路、保证当数据不足时模型知道打补丁而不是胡乱推断。做得好的系统会在不暴露底层调用逻辑的前提下,把“怎么用”这件事交给企业可控的Skill集合。
最后一件事是来源背景:这场讨论许多来源于Anthropic发布的那篇长文,尝试把Claude的Skills和MCP、Projects、subagents之间的关系讲清楚。官方文档里给出的例子和设计理念在业界引发了不少实践和改造,大家也在试验不同的分工方式。实际落地像上面那个BI场景,有搞得很顺的,也有一开始拉错Skill、吐出奇怪汇报的案例。写到这里,觉得这套东西挺接地气,但也挺考验工程和模型配合水平的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...